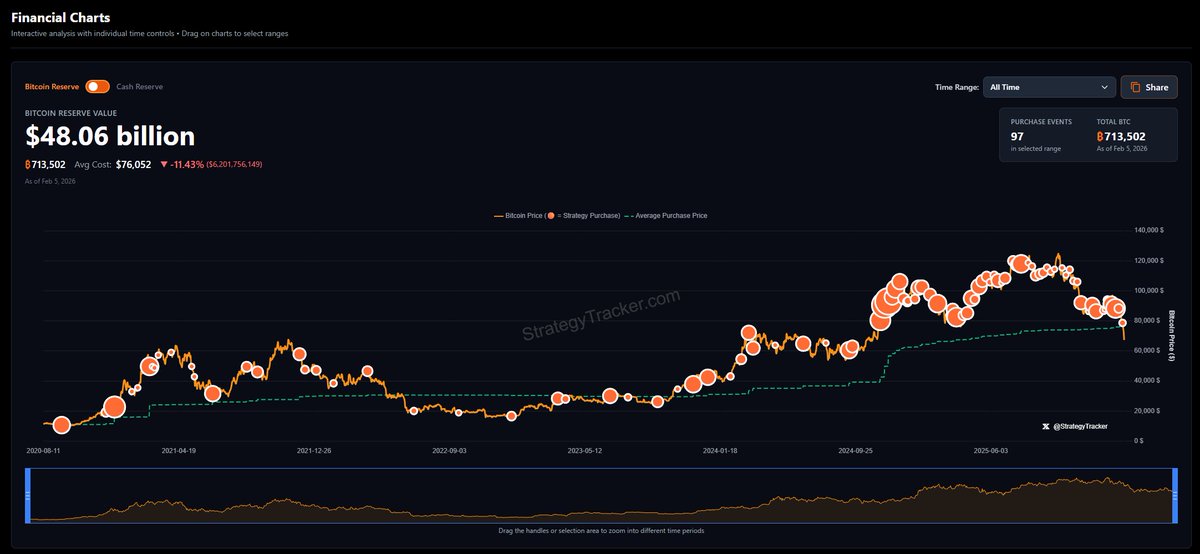
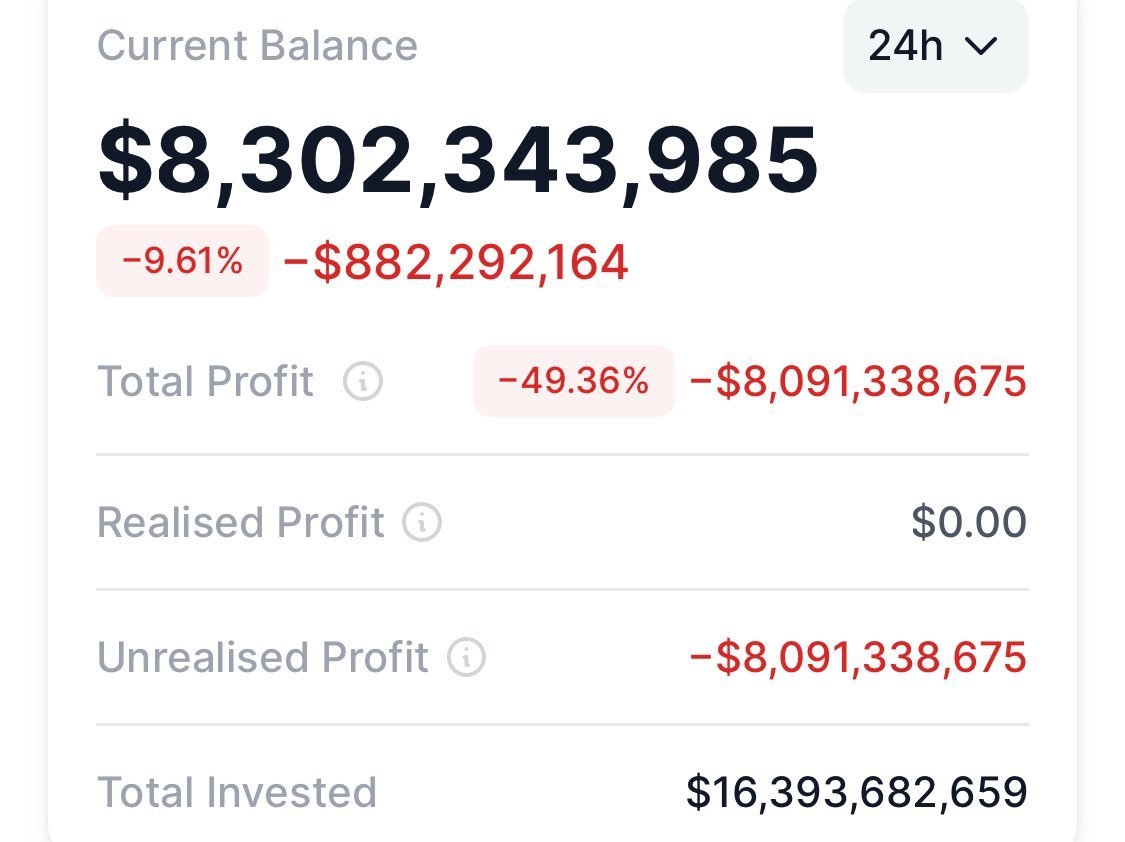
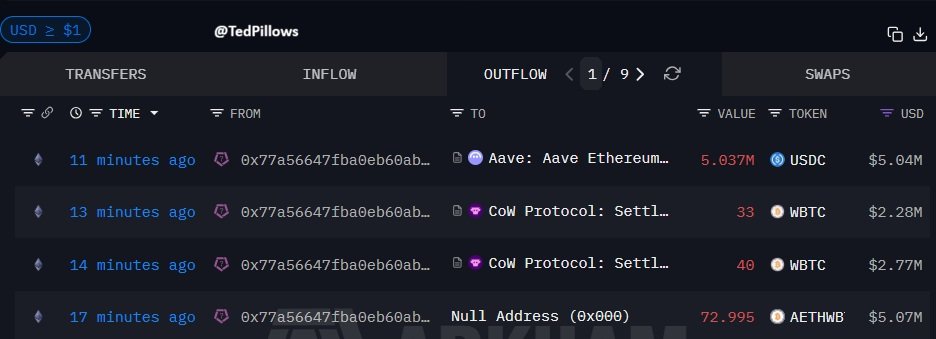
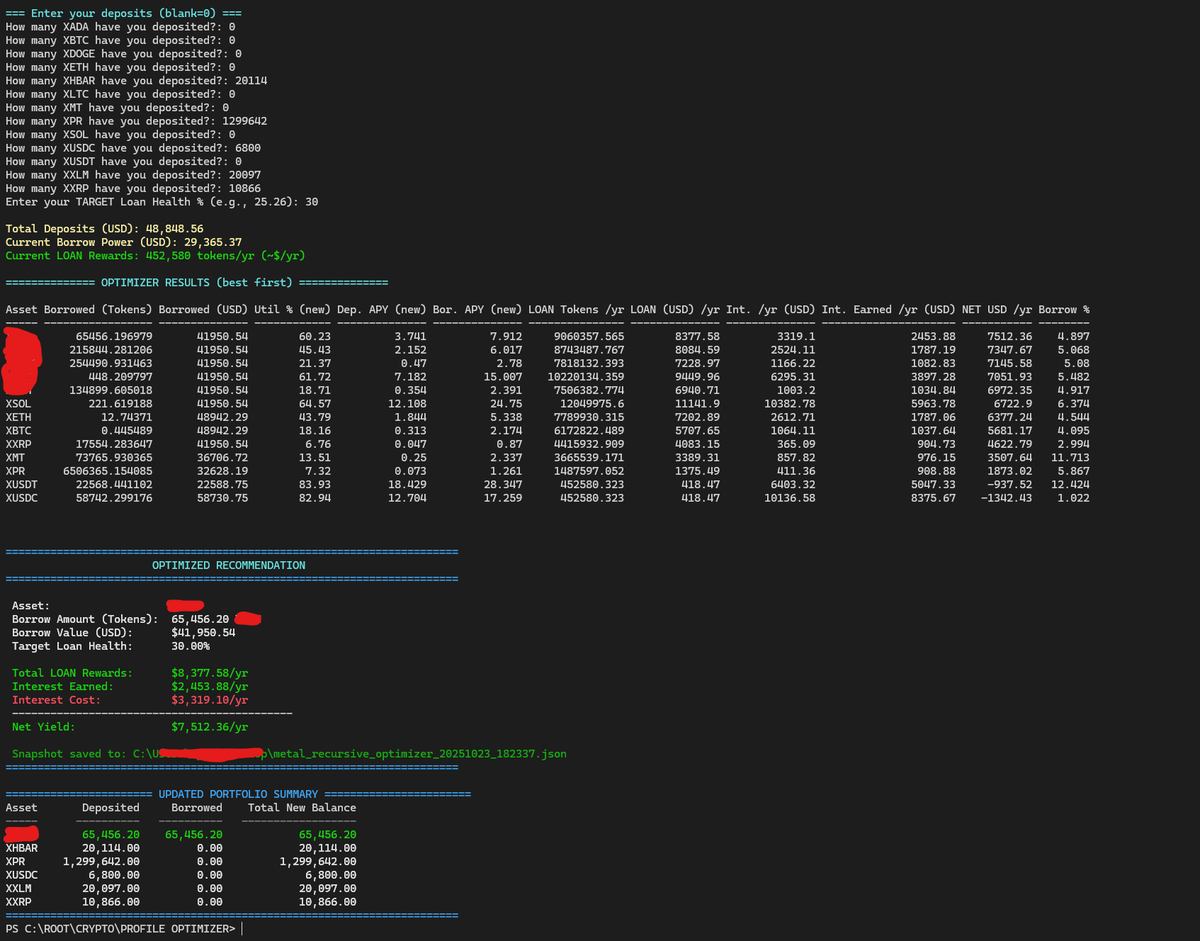
It’s funny you say this- because I started with Ollama as the main local host. Once I learned it capped the number of layers that I can have on the GPU for the Quin3.5 MoE to 30- pushing the other 11 to the system RAM- I said fuck it and switched my backend to llama.cpp - best decision ever.
English