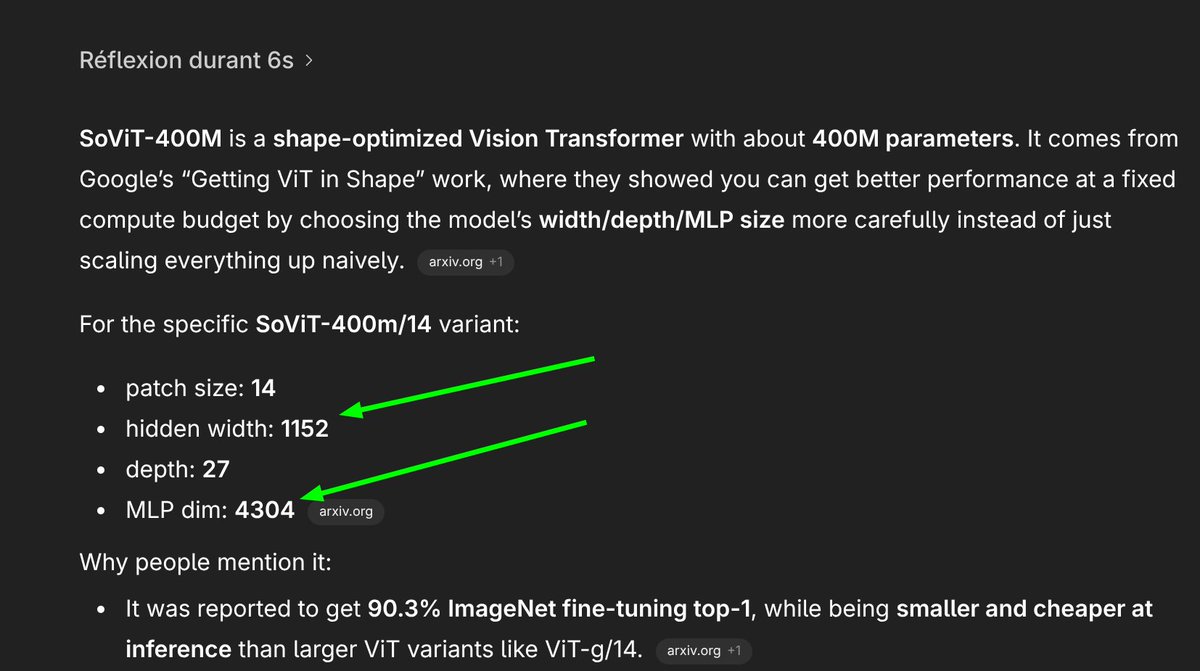
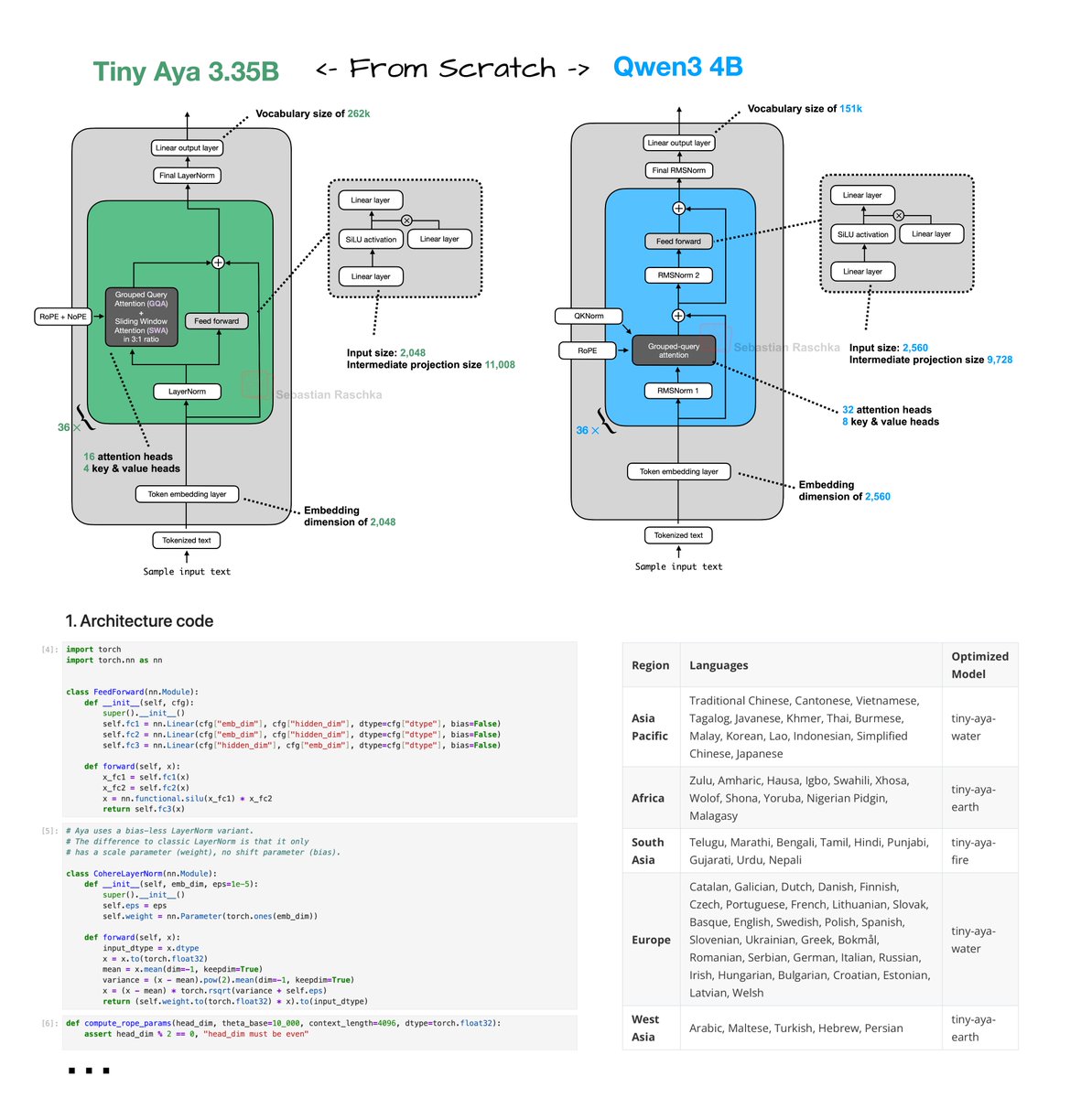
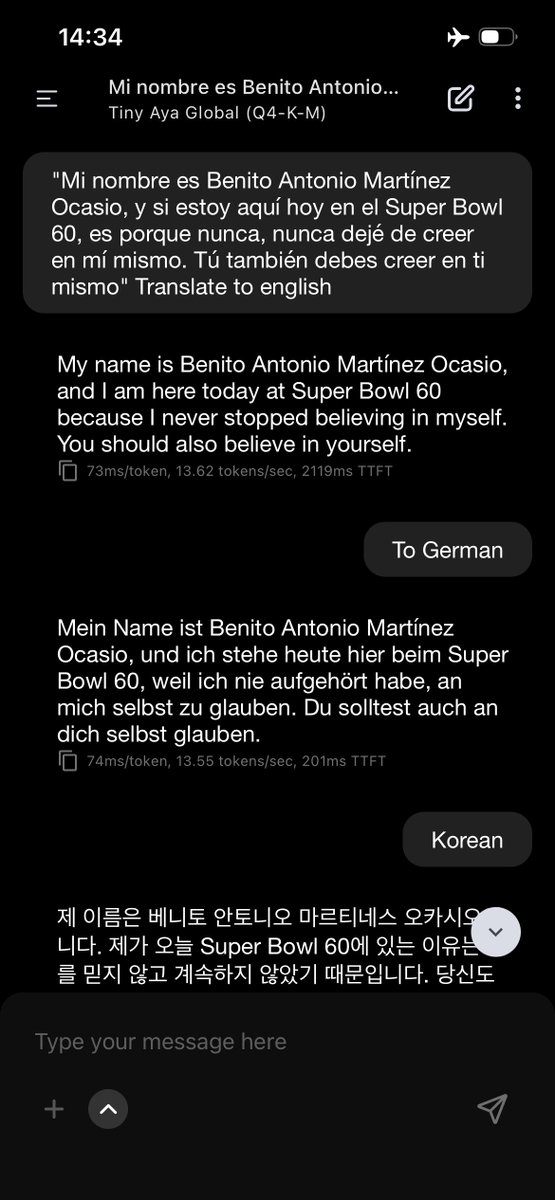
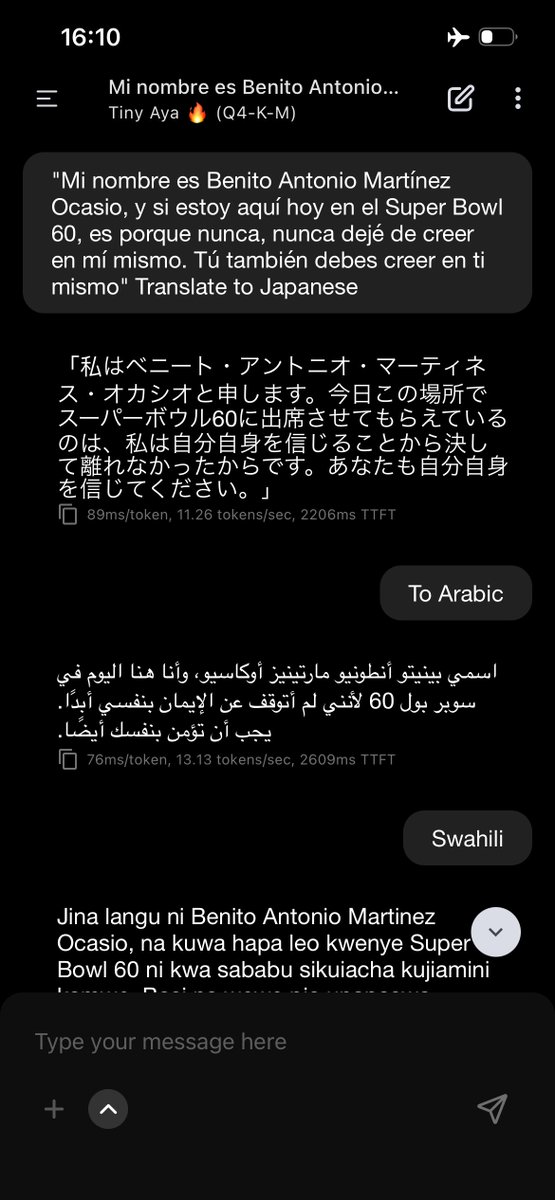
@giffmana @tenderizzation @bilaltwovec I agree! Unfortunately, It just didn't gel well with the 384 size!
English
Saurabh Dash
546 posts
@TheyCallMeMr_
Bottomless pit supervisor. ML @CohereAI , PhD Student @GeorgiaTech. Previously @Apple, @IITkgp. https://t.co/yZLkUsiZ7P. Opinions expressed are my own