
Tom Pease
143 posts

@Graham_dePenros Bummer. Don’t know what to do. Works for speakers. Sigh
English

Hi y'all!
I am having severe audio issues just with this Space. Is anyone else experiencing the same?
I get "no sound" consistently after 30 to 45 seconds.
I have swapped two cells - Android and iPhone - cleared app cache on both, and rebooted. Same. "No sound" consistently after 30-45 seconds.
Now I am on a MacBook Pro M4 Max with Beyer Dynamics headphones and a SHURE mic via a top-of-the-line Focusrite box. Same. "No sound" consistently after 30-45 seconds.
I have 5 bars on my Mobile Hotspot, and in a speed test, everything looks good. Switched to 10 Gbps WiFi, and no joy either.
What is going on?!?!?
This is a one-in-a-million chance to hear @Scobleizer and @BrianRoemmele, and I can't hear anything!
Anyone else?
Best,
Graham
Robert Scoble@Scobleizer
Join @BrianRoemmele and me discussing how AI is changing X. Decreased reach? Intellectuals filtered out? New AI feeds? Changes in API pricing? The current and future of X is on the table. twitter.com/i/spaces/1kJzD…
English
Tom Pease retweetledi

Dear President Trump, Thomas Sowell is an American treasure. Please consider honoring him with the Presidential Medal of Freedom. I can’t think of a greater representative of American values.

English
@BrianRoemmele @ReadMultiplex I should mention this system handles research, monitoring, and personal productivity only. No confidential client information ever touches this system.
English
Thank you @BrianRoemmele. I'll keep reading your posts and @ReadMultiplex for additional ideas to incorporate.
English
I wanted to thank Brian as this post changed my trajectory. Eight weeks later: I have built a version of this system that continues to evolve. A patent litigator and AI enthusiast's version of the Zero-Human Company. 🧵

Brian Roemmele@BrianRoemmele
We at the Zero-Human Company with CEO, Mr. @Grok’s guidance also have dozens of Kimi K2.5s with PicoClaw running in Raspberry Pi’s! We will have 64 by weeks end. Sunk cost per using is $50 per employee plus JouleWork! You can do this and I’ll show you how with one single file soon. OH AND YOU CAN RUN ONE FOR EVEN LESS! $10 bucks. LOCAL!
English
@sudoingX @NeoAIForecast What’s the best place to get a 3090? Many eBay deals seem sketchy
English

own your compute anon. even if it means buying a single 3090, a 4090, an entry dgx spark. just one card under your desk. then prompt it freely without openai logging every thought, without anthropic indexing your work, without your queries becoming training data for the next model competing with you.
compute is where thinking happens. healthy thinking needs private infrastructure. rented thinking on someone else's gpu is borrowed, monitored and revocable.
these prices are going. ram crisis is real, hbm locked through 2027, chip lead times blowing out. the 3090 you can grab today for $900 - $1,200 won't be that price next quarter. window is open right now, closing fast.
not fud anon. same memo every chip analyst has been writing for six months. get a card. get a taste. once you've thought freely without billing meters and surveillance behind your prompts, you don't go back.
Sudo su@sudoingX
corporate labs pay their employees to go on x and tell you local isn't there yet, think about who benefits from that framing. 24gb of vram and a one sentence prompt is all this took. google cooked, the model isn't bad, the narrative around local is. if you have a 3090, 4090, or desktop 5090 sitting around, pull google_gemma-4-31B-it-Q4_K_M.gguf, fire llama-server, open the web ui. that's the full setup. no rate limits, no dependency, just your gpu and the model. the skeptics will find a new line after this one lands. the builders are already downloading.
English
@TheAhmadOsman I'm using PicoClaw with a bunch of LicheeNano RVs, all controlled by Raspberry Pi 5 with Hermes.
English

If you give this command + system architecture screenshots to any agent like
Codex / Kimi Cli / Droid / OpenCode / etc
You can tell it to create you a VM for an 8GB VRAM VM that matches mine in performance for Hermes Agent
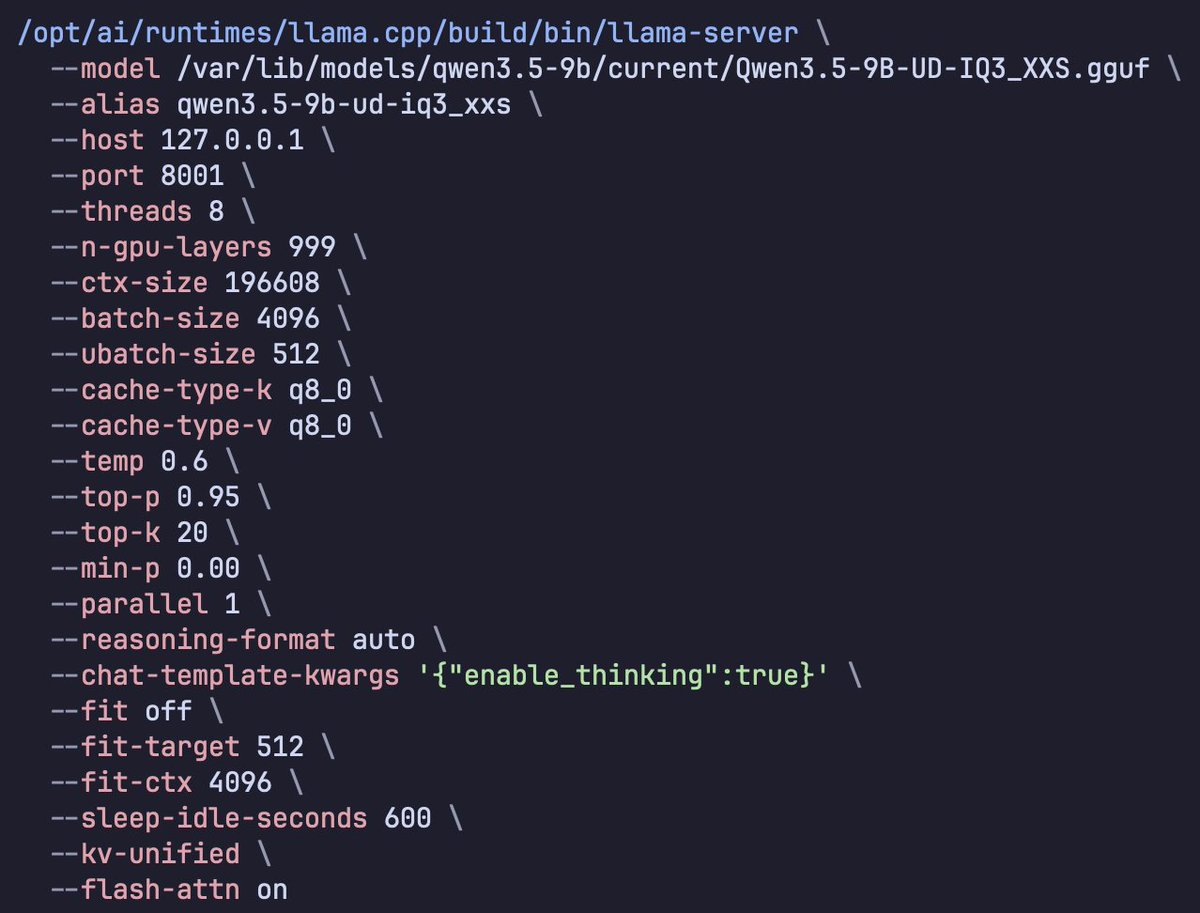
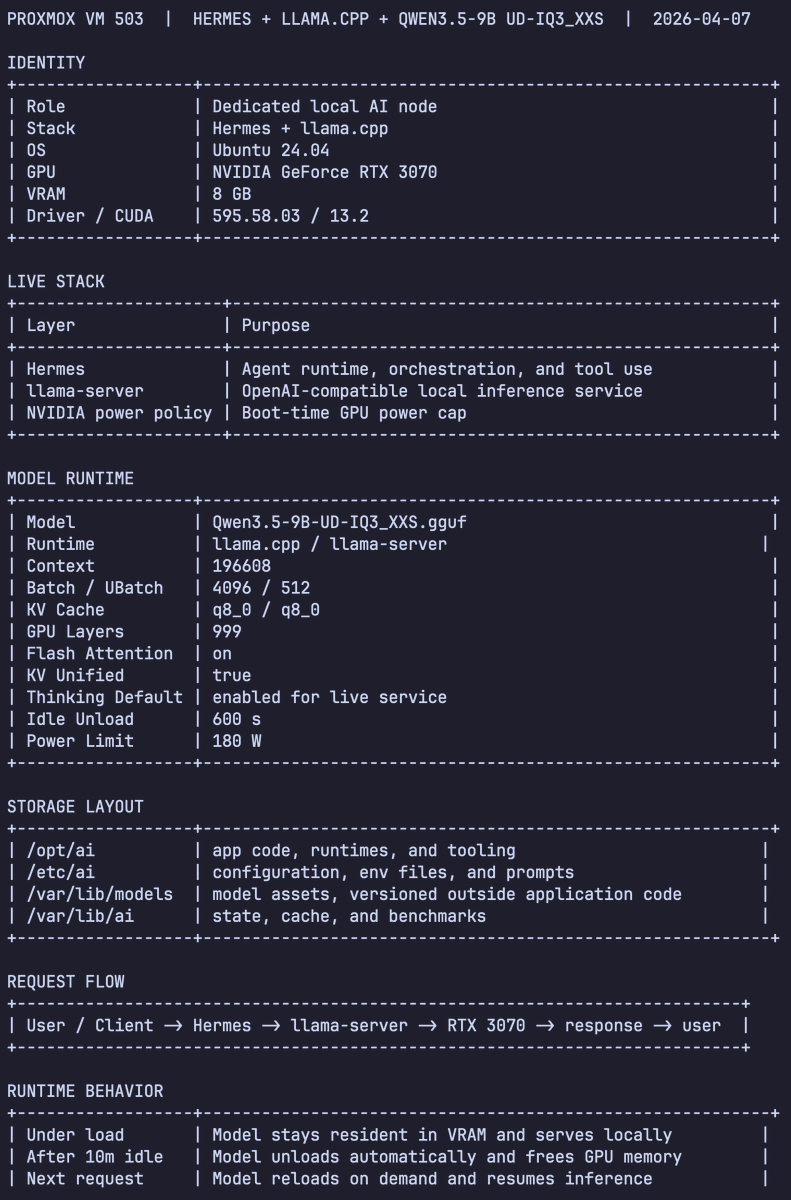
Ahmad@TheAhmadOsman
Used Codex Cli to profiled Qwen 3.5 9B Dense (Unsloth's UD-IQ3_XXS via llama.cpp) for Hermes Agent Tuning: > context length > batch size > tokens/sec > peak memory To squeeze every last drop out of an 8GB VRAM card
English

Tom Pease retweetledi

Hello Senator Thune,
At 3 AM on Friday, March 27th, in a near-empty chamber, you passed a bill by voice vote that excludes all funding for ICE and CBP.
Let me repeat that: voice vote. No roll call. No record of who was there. No accountability. Just you, Barrasso, and a handful of senators shuffling paper in the dead of night while America slept.
You could have demanded a recorded vote. You chose not to.
You could have held the line for five more days until the House returned. You chose not to.
You could have used the same procedural tools Democrats have used against you for 40 days. You chose not to.
Instead, you gave Chuck Schumer exactly what he asked for, DHS funding minus immigration enforcement, and called it a win. Then you walked to the cameras and blamed the Democrats.
Let's be precise about what you did:
1. You caved to a demand Democrats made on Day 1 of this shutdown. Forty-one days of supposed hardball negotiation, and you settled for their opening offer.
2. You handed them a template. The next time Democrats want to defund any agency — ICE, CBP, or anything else — they now know: just shut down DHS and wait. John Thune will fold at 3 AM.
3. You punted to reconciliation. "Good possibility," you said. Not "we will." Not "guaranteed." Just maybe. Meanwhile, ICE operates on fumes from last year's bill with no certainty of future funding.
The precedent you set:
You have argued for months that the filibuster is sacrosanct. That the 60-vote threshold protects minority rights. That we cannot bend Senate rules for policy wins.
But at 3 AM on Friday, you bent every norm that actually mattered:
• Voice vote to avoid accountability
• Empty chamber to avoid debate
• Midnight deal to avoid scrutiny
• Immediate recess to avoid questions
You'll bend the rules to avoid a fight. You just won't bend them to win one.
What you've actually accomplished:
Democrats demanded ICE restrictions. They got ICE defunded.
Not reformed. Not restrained. Defunded.
And you're out here tweeting about how Democrats are the "Defund the Police" party while you just voted to defund border enforcement at 3 in the morning.
The question you should answer:
Why did this deal have to happen at 3 AM?
Why couldn't it happen at 3 PM, with cameras rolling and every senator on record?
You know why. Because you didn't want your voters to see what surrender looks like.
Here's my message: We saw it anyway.
Stop hiding behind "Democrat obstruction." You're the Majority Leader. You set the schedule. You control the floor. You chose this outcome.
Own it.
English
Tom Pease retweetledi

Sometimes, I wonder why I do this work.
I wonder why I work so hard to elect Republican majorities into office
& — when we are in power — our very elected officials don’t wield or harness that power.
I wonder why I lose sleep, miss family vacations, & put my personal life on hold, so wealthy Senators can go on paid vacations
after not achieving the very promises they campaigned on.
Sometimes, I wonder if they truly care about us & if they actually want to represent the will of the very people that elected them into positions of authority.
I will tell you this: if the Senate ultimately does not pass the SAVE America Act, I will use all of the energy, hustle, & organizing efforts we used to elect these Senators into office
as tools to peacefully & respectfully defeat them in their upcoming elections.
English
Tom Pease retweetledi

This is one of the hardest things we have ever had to share. We are not the kind of people who like to ask for help. We have always believed in putting our heads down, working hard, trusting God, and doing everything we can to carry the weight ourselves. But there comes a point where the truth is bigger than pride, and our customers, followers, supporters, and everyone deserves to know what is really happening.
Right now, we are in a legal battle with a major meat processor. And while this fight has our name on it, it is much bigger than our family alone. Small producers, family ranchers, and farmers spend generations building something they are proud of, only to come up against an industry that too often protects power over people, profit over principle, and control over transparency. The effects do not stop with the people raising the food. They reach every person purchasing meat because corruption and lack of transparency in the beef industry affect the food system as a whole and the trust families place in what they buy and feed their loved ones.
This fight has cost us deeply. Between personal health struggles and the weight of this battle, we have had to make sacrifices we never wanted to make. We have had to cut back on our restaurants and e-commerce. We have sold cattle to help pay attorney fees. We have carried stress, heartbreak, and pressure that, at times, have felt impossible to explain.
But we are still here, and we are still fighting. We are fighting for our family, for our ranch, for the values we were raised on, and for every small rancher and farmer who has ever felt crushed under a system that was never built to protect them.
So today, we are asking for help. If you believe in family ranches, quality food, hard work, and a more transparent, healthy, and clean food system, please stand with us. One of the best ways you can support us right now is by purchasing our beef at santacarota.com.
We started a GoFundMe for those who want to be part of something bigger than our family alone. If you want to help us keep fighting, please consider donating and helping us fight for farmers, ranchers: gofund.me/5f9dbc127
English

"Writing a book is hard."
Wrong.
Writing a book *without a system* is hard. 😱
Thread: The 5 systems I use to ghostwrite books that convert readers into clients.
English