UG
81 posts


UG
@UGdaynight
Learning, evolving, compounding. From chaos to structure.


《如何基於 Farcaster 尋找新東西 ·第二彈:藉助自動化 VC AI Agent 尋找打新機會》 今天看到 @zeckxyz 提到 @feyprotocol $fey 打新的十倍收益,恰好是我上個禮拜逛 @farcaster 因同一個信息源 @faircaster 關注到的項目,而且,@11AMdotclub 也發了創始人 Luc de Leyritz @deLeyritzluc 的訪談。 我個人很欣賞 Luc @deLeyritzluc做這個項目的核心理念,以下為結合訪談内容,簡單總結一下這個信息源~ —— 現在場内流動性有限,經常是熱點輪動,最起碼的,跟一個信息源,總要先理解人家的 thesis 和運作原理,避開大環境不利於這種策略的時間段,更進一步,最好能倒推信息源如何一步步優化,再去完善自己處理信息的系統。 1⃣@faircaster 是什麽 Luc @deLeyritzluc 的 RE7 基金專注 「社交」+「消费」的 crypto 項目,Faircaster 是他們創建的 Farcaster 和 Base 上的自治型風投基金(autonomous venture fund),靈感源於他們在 RE7 之前的數據基礎設施實驗(處理信息+基於數據做投資決策),試圖由 AI 來運行這個流程。 簡單理解: 這是一個 AI agent 自動搜尋、篩選、分析、投入資金的 VC,最早在 Farcaster 推出,但是他們的 X 也會同步更新内容。 因此,即使不玩 farcaster,也可以關注他們的 X 賬號 @faircaster (還有 luc 和另一個 co-builder @runn3rrr 也會經常提及生態項目,算是不錯的視角補充~) 2⃣投資偏好: 基本面投資。 因爲 RE7 認爲 Farcaster 生態的一些項目有長期價值,因此主要關注這一點。 → 推論: 當 base 生態處於上升期,這個信息源的作用會被放大,目前關注的人不多,可以考慮作爲重點關注; 當 base 生態處於過熱,且根據跨鏈和 @AerodromeFi 的數據都可以看出流動性在明顯撤退,那麽就需要結合更多交叉信息,謹慎對待這個信息源提及的項目。 3⃣ 技術框架 根據 Luke 說的,我大致整理成了以下示意圖。 根據以上模塊,Faircaster 即時讀取約 75 萬條來自關鍵使用者(創辦人、投資人、優秀交易員)的公開社交數據,每日篩出約 500 個項目,最終挑選少數(目前是 8 個)進行投資,系統 24/7 自動運行,團隊僅在收到模型預警時人工介入,確認執行(也是項目唯一中心化的部分,大概 3% 的部分因爲面對的場景是非標準化,暫時無法完全擺脫人類輔助)。 P.S. 和我自己日常找 alpha 的方式比起來,多了 AI agent 的直接參與,少了鏈上數據的分析,更多還是依賴於人作爲信息樞紐去做信息整合,從最早期打新角度看很合理。 4⃣ 項目實況與(躬身入局的) 團隊機會 目前,@faircaster 的自治型風投基金還算比較早期,規模約 10 萬美金,距離啓動時增長了超過 2 倍,最早的資金來源於早期顧問和 Farcaster 生態的個人投資者,這個基金也有自己的代幣(CA 見項目方 X 的簡介,看了下目前 FDV 是 8 M ),團隊後續希望更謹慎設計代幣經濟,確保早期支持者能夠分享到後續潛在的收益。 注意:這個規模目前并不算大,對於 base,特別是 farcaster 生態來説,其實更適合資金不多的散戶早期找找機會,很難上大倉位~ 如 x402 + base 的項目,我之前去掃鏈,在部分項目前排看到不少 base 深度用戶,日常也就是幾百 U 在玩,偶爾會撞一兩次這種大運~ 團隊中, Luc 負責技術搭建,正在尋求另一位技術合夥人——希望是厲害的工程師,有興趣的朋友可以直接 DM 他 → @deLeyritzluc



CATHIE WOOD: THE WORST IS LIKELY OVER FOR BITCOIN Cathie just laid it out pretty clearly and says the last 2–3 months were basically the aftershock from the Oct 10 flash crash -- a Binance software glitch that forced ~$28B of deleveraging across crypto. Bitcoin took the hardest hit because it’s the most liquid asset. That unwind is mostly done & now the debate has shifted to the 4-year cycle. Are we still in the downside phase? Cathie’s answer: probably not. She sees $BTC likely basing in the ~$80K–$90K range, then moving higher once that consolidation does its job. Institutions aren’t questioning if #Bitcoin belongs anymore -- they’re figuring out how to size it as a new asset class with low correlation. The forced selling looks behind us. What comes next is positioning. 👀



BTW,因爲妹妹們的緣故,確實提前有了一點育兒焦慮,比如開始思考未來應該如何選擇不同的國家組合,更好地教育自己的小孩。 目前,我和圈内最好的女性朋友之一、legend 而且相當 whale 卻無比低調的 Célestine 女士,正在編寫一本育兒相關的 playbook。 所以,本月很歡迎各位朋友分享你關注的問題或者心得(私信已開放),不論你是已有或者準備有小孩,還是不需要通過自己生育但希望有小孩的同性伴侶,都可以發給我你們關注的問題。 我們能做到的就是連接在我們認爲家庭和事業都經營成功的朋友,正在不同國家養育小孩的華人朋友,以及 VC 圈中主要關注 longevity、投醫藥行業的朋友,在很多關鍵問題上打破一些信息差。 至於爲什麽要做這件事,你們也可以當我們是暫時賺夠了,想多少做點對中華民族傳承有益的事吧~~ 畢竟總是空喊著大家要多生孩子卻絲毫不顧育兒給個體帶來的海量問題是根本不可能有什麽用的……🤷🏻♀️

現在最忍無可忍的事情:部分人用 AI 已經用到跟我日常發消息的語言表達潤色上,這些人到底是高看了 AI,還是瞧不起其他人類對語言表達的敏感程度? 遇到這種情況,簡直讓人想死。真的求求了,用 AI 做一些可以發揮 AI 更多天賦的事情吧!咱們講人話不好嗎?




== Vibe Coding 零基础教程 02:自建信息流 == 如何构建自己的信息流和数据库? 我自今年年初就开始用 Hacker News 的高质量数据构建自己的信息流,减少信息茧房。两个月前我上线了 newshacker.me 这个网站,将个人的信息流产品化。 我认为构建自己的信息流是一件极为重要的事情,因为它决定了我的视野和思考广度。因此,我希望把开发 newshacker.me 中积累的经验分享给大家。 1️⃣ 找到高质量信息源并实现自动化 这个世界的信息纷繁复杂,来自媒体、论坛、社交网络等各种渠道。随着网络爬虫的滥用,原本开放的数据也逐渐提高了获取门槛。 如今,有了 Coding Agent,构建自动化信息抓取流程反而比找到真正高质量的信息源更简单。因此,我们可以首先对信息源进行分类,然后逐步实现自动化。 🟢 第一类:提供 API 的服务 例如 Hacker News、GitHub、Reddit 或 Product Hunt 等网站,这些服务通常有面向开发者的 API 接口。你可以使用 Research Agent(如 GPT-5)帮你判断某个网站是否提供 API 及其使用方式,然后开发一个最小可行的程序,从 API 获取数据。 🟢 第二类:提供 RSS 的服务 比如论文期刊或知名媒体,大多提供 RSS 或 ATOM 格式的 Web Feed。这种方式获取数据成本低,AI 可以帮你快速构建 RSS 抓取工具,定期自动获取最新信息。 🟢 第三类:需要网页爬虫 有些内容平台未提供 API 或 RSS,此时可请 AI 利用 Python 的第三方库实现网页爬虫,抓取网页并提取所需数据。如果难度较高或平台限制明显,可考虑下一条的方案。 🟢 第四类:类似推特的平台 推特曾经极为开放,但近年来 API 成本显著增加,目前更推荐通过 AI 辅助,利用 Python 和 Playwright 等工具实现。这一部分难度较高,值得单独展开为一篇教程。 🟢 第五类:付费获取的信息 尽量避免使用解锁 Paywall 插件,更合规的方式是付费订阅后再利用前述方法自动抓取数据。 2️⃣ 将数据存入数据库 上一篇教程已经介绍了如何构建数据库,方案包括本地或云端部署 MySQL 或 SQLite 等数据库。 我个人更喜欢 Cloudflare 的 Worker,每个 Worker 可以设置为定期自动运行,比如每 5 分钟获取 RSS 或 API 数据并存入数据库。你可以让 AI 告诉你如何在 Cloudflare D1 数据库(SQLite)中创建数据库、设计表结构,并指导编写 Worker 脚本。经过几次调试后,你就能快速搭建出可用的数据存储方案。 3️⃣ 持续完善业务逻辑 刚开始编写 Worker 代码时,不可能一步到位。对于新手来说,完整设计所有产品逻辑和规则是困难的,这是正常的。 比如最初设计的规则是「抓取 RSS 并存入数据库」,但你很快会发现数据重复存储的问题。这时需要更新规则为「抓取 RSS 后只存入新增数据」。如何定义「新增」数据,就是一个不断迭代优化的过程。 一开始没想清楚没关系,在实际使用过程中逐步完善逻辑即可,很多成功的产品也是这样不断迭代优化的。 4️⃣ 数据输出和应用 拥有数据后,如何高效使用这些数据呢?这里提供几个快速实现的方案。 最简单的方法是搭建网页进行输出。如果使用 Cloudflare,你可以请 Coding Agent 帮你搭建 Cloudflare Pages,自动从 D1 数据库取数据,以信息流的方式展现。 增加一点难度的话,可以利用 LLM 实现内容翻译。流程是构建一个新的 Worker,定期调用 OpenAI 或 Claude API,翻译数据并存入数据库的相应字段中。 另外,如果你想将每一条新信息自动推送到 Telegram 频道中,也完全可行。只需要创建 Telegram bot 和频道,通过 API 自动实现内容推送,这个流程 AI 同样非常熟悉。 更进阶的玩法,是对多信息源的数据进行整合和聚类。这需要运用大语言模型,并学习结构化输出技巧,以便高效处理和呈现大量数据。这一内容也值得后续专门展开讲解。 5️⃣ 总结 自建信息流的核心,是明确需求、确定信息源、构建自动化抓取流程,并实现数据的高效存储与应用。即便一开始并不完美,通过不断的迭代和优化,你一定能构建出一个属于自己的信息流产品。 希望通过这些内容,帮助你顺利迈出 Vibe Coding 的第二步,开启个性化信息世界的大门。

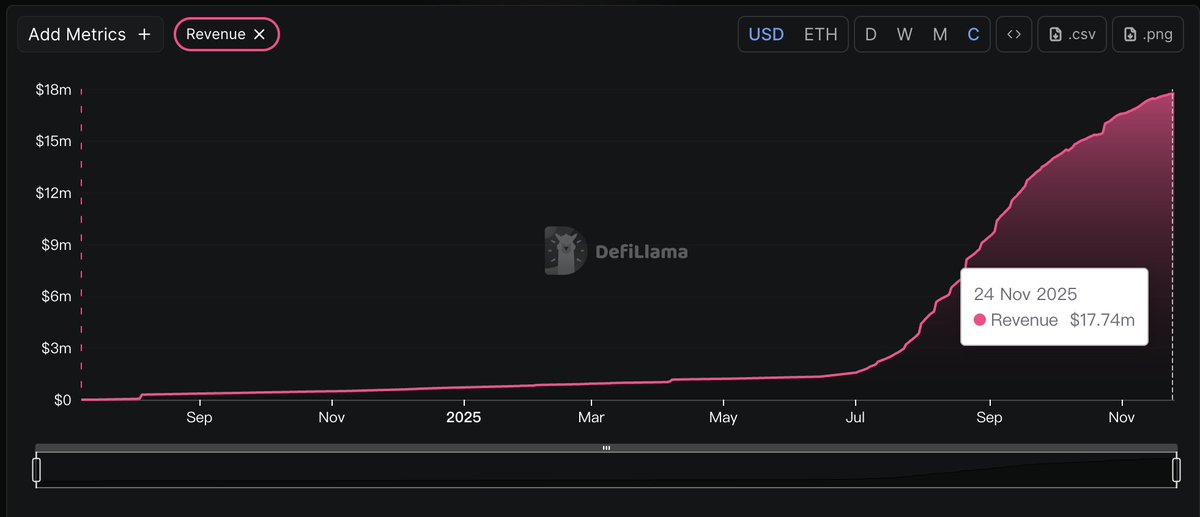
Voting has just opened for one of Spark’s most important governance proposals yet, to adopt a buyback mechanism (SubDAO Proxy Management Plan) What does this mean, and why is this important for the Spark community: 1. Spark accumulates all net revenue into the SubDAO Proxy (treasury), earning over $10 million since TGE in June. Under this proposal, excess funds above what Spark needs for risk capital and OpEx will be used to make SPK purchases according to parameters defined by governance. This mechanism aligns treasury management with the protocol's long-term sustainability. 2. The size of buybacks programmatically increases as the treasury accrues more excess capital. 3. Most importantly, the proposal aims to align protocol operations, treasury management, and community incentives in a transparent and programatic framework. An upgrade built to power Spark's next chapter.

Voting has just opened for one of Spark’s most important governance proposals yet, to adopt a buyback mechanism (SubDAO Proxy Management Plan) What does this mean, and why is this important for the Spark community: 1. Spark accumulates all net revenue into the SubDAO Proxy (treasury), earning over $10 million since TGE in June. Under this proposal, excess funds above what Spark needs for risk capital and OpEx will be used to make SPK purchases according to parameters defined by governance. This mechanism aligns treasury management with the protocol's long-term sustainability. 2. The size of buybacks programmatically increases as the treasury accrues more excess capital. 3. Most importantly, the proposal aims to align protocol operations, treasury management, and community incentives in a transparent and programatic framework. An upgrade built to power Spark's next chapter.
