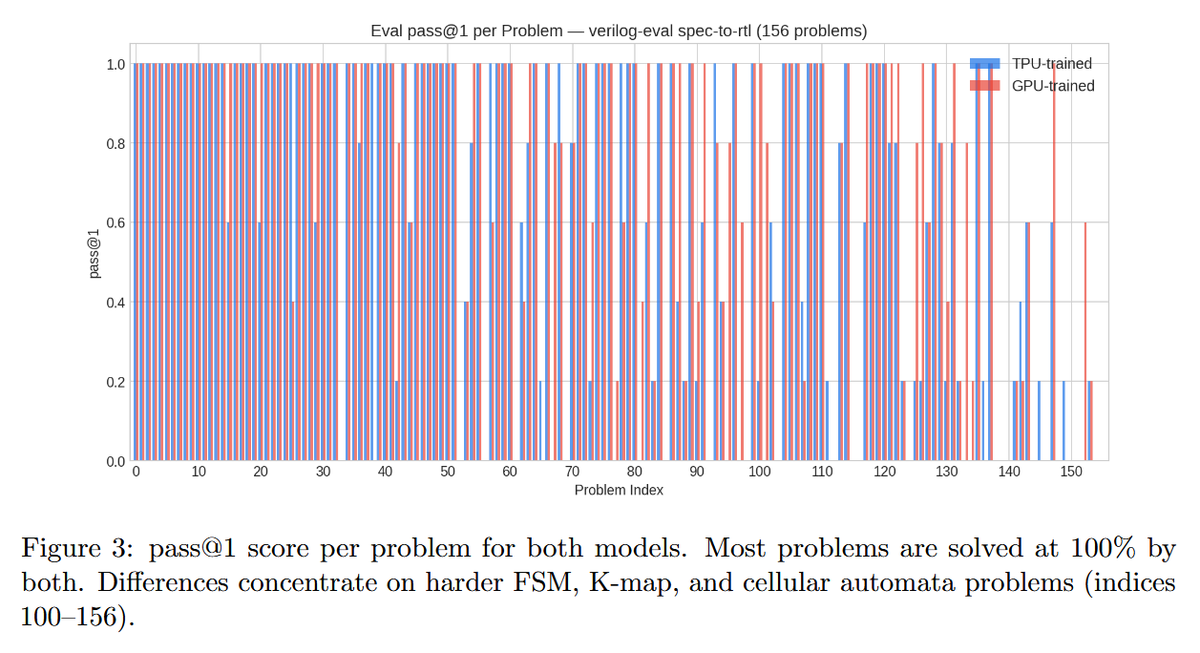
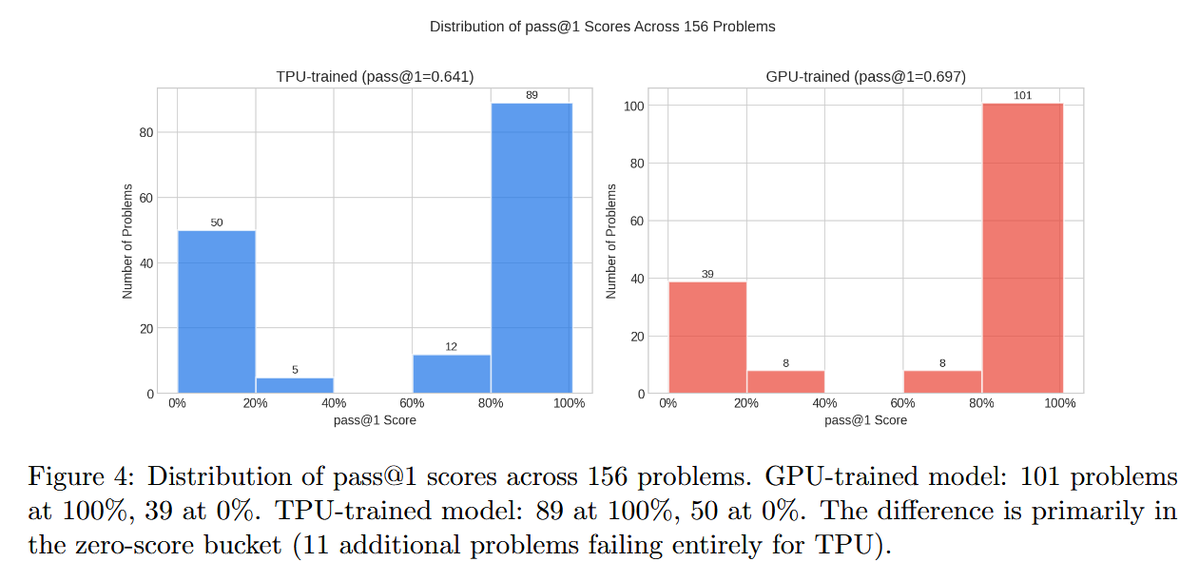
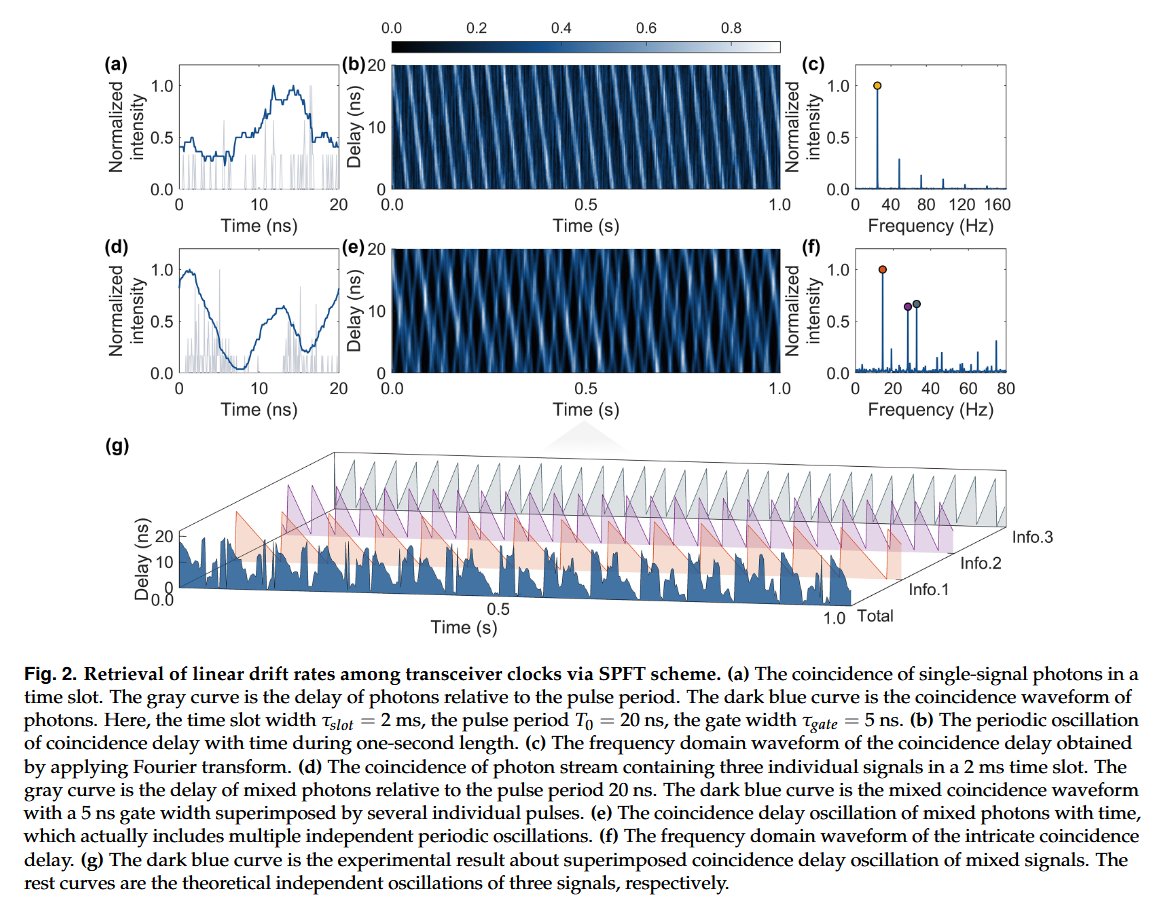
Sabitlenmiş Tweet

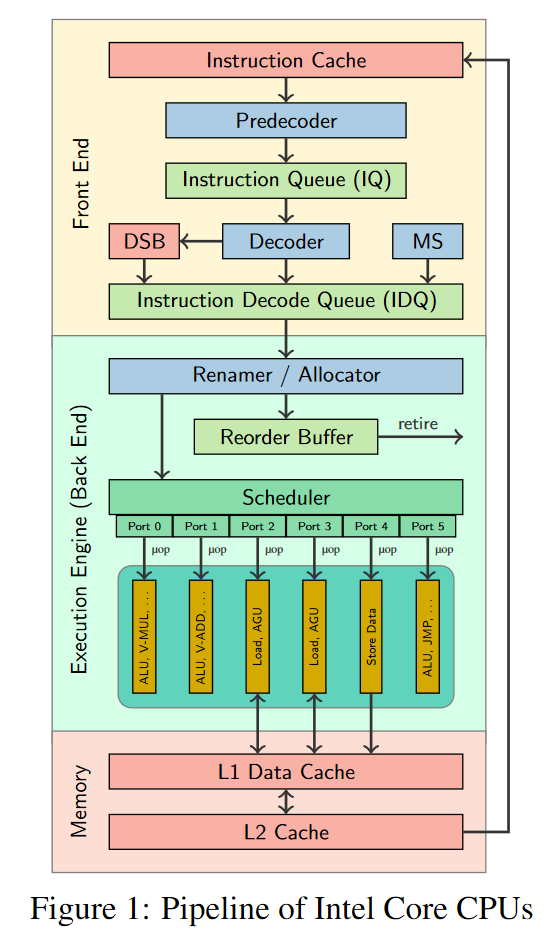
Researchers have developed a new simulator to predict the throughput of basic blocks of all Intel Core μarchs released in the last decade, demonstrating to be more accurate than the predictions of state-of-the-art tools by more than an order of magnitude.
arxiv.org/pdf/2107.14210…
English