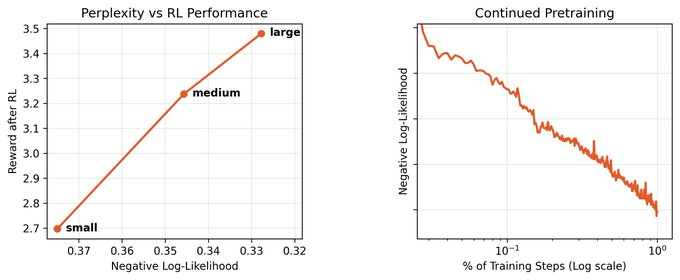
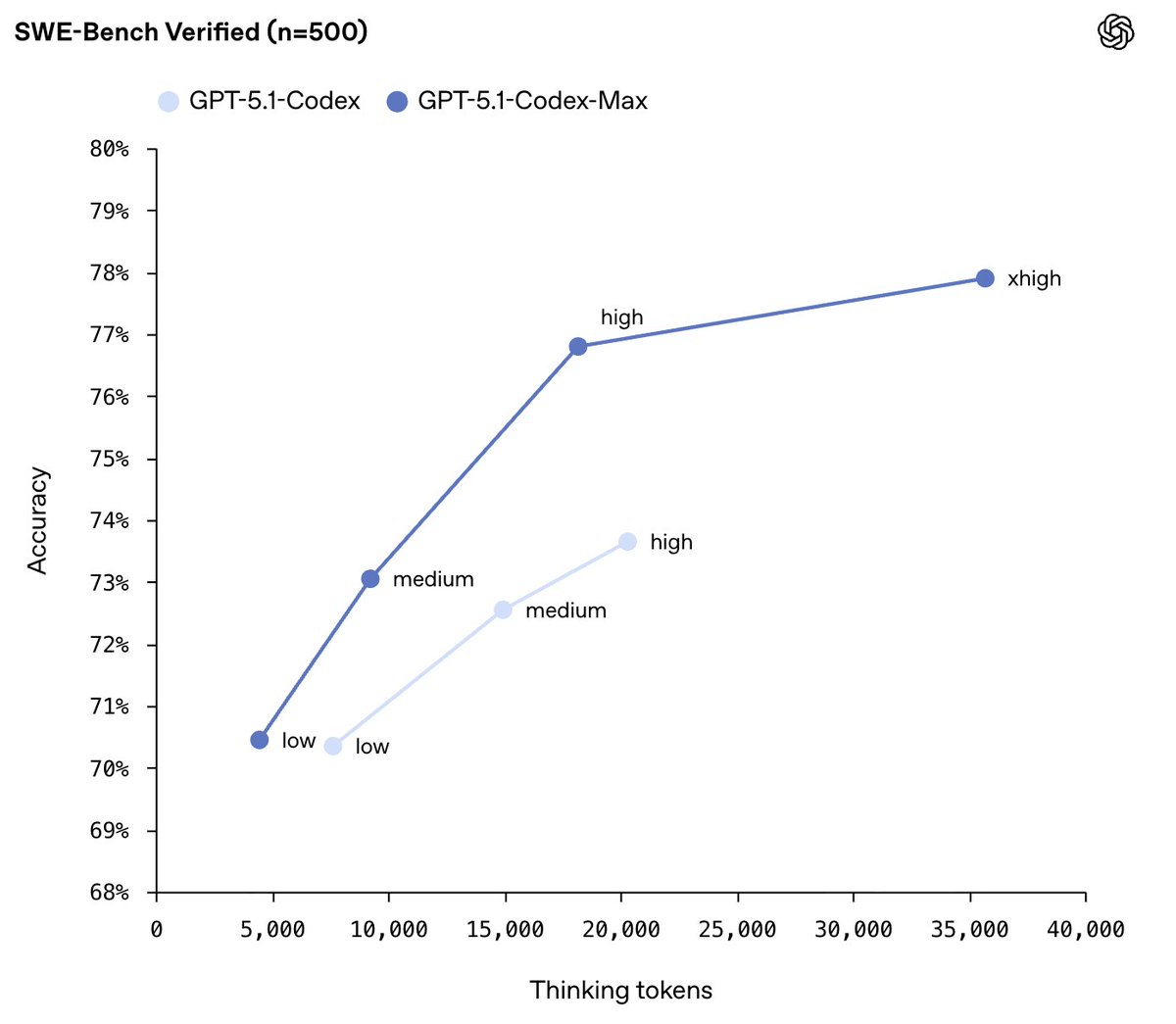
@varun_kr great question! don't think we have definitive answers here, but if you believe that RL is doing some "low-rank" adaptation, should be straightforward to unlearn. of course, you lose all the juice from previous RL, but our RL stack is quite good and makes up for it
English