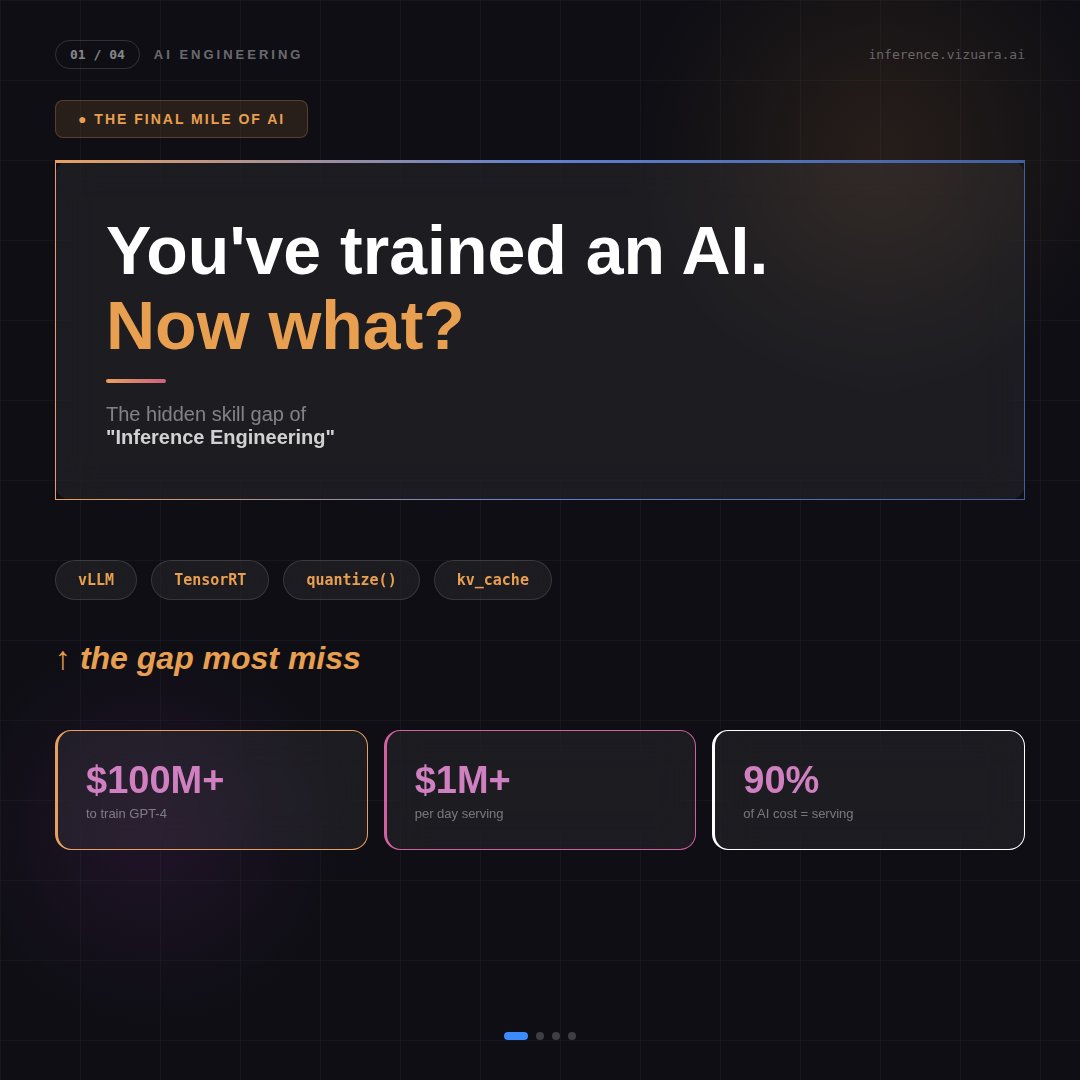
DeepSWE hits 42.2% on SWE-bench using massive compute.
Dr. Rajat Dandekar’s pod teaches the same GRPO algorithm on a laptop in 30 minutes. Build RL environments, training loops, and evaluation from scratch. Same method, 18,000× less compute.
lnkd.in/dz99wpEU
GIF
English