
Steven Walton
2K posts

Steven Walton
@WaltonStevenj
Ph.D. from University of Oregon | Visiting Scholar @ Georgia Tech | Studying Computer Vision | SHI Lab | 🦋 https://t.co/jW5YkexBMX
Eugene, Oregon Katılım Mart 2021
623 Takip Edilen365 Takipçiler

Who knew @SouthPark was so prophetic?
youtube.com/watch?v=sDf_Tg…
If you want to listen to the songs it made...
flowmusic.app/session/90d9d4…

YouTube

GIF
English
Now I wish it was "mass surveillance" rather than "mass *domestic* surveillance" but it's clear that @AnthropicAI is aligning to /their/ *moralities* while @OpenAI is aligning to *legality*. These are not the same and the latter is blatantly a lower guardrail.
It's insulting
English
But we can just read both their statements. Compare these two.
@AnthropicAI: no domestic mass surveillance, even if it's legal
@OpenAI: as long as it's legal ¯\_(ツ)_/¯
That's the big difference.
anthropic.com/news/statement…
openai.com/index/our-agre…


English
This is a farce. To claim "more guardrails" is frankly unbelievable. Why would @AnthropicAI be called a supply chain risk but then @OpenAI gets a contract with stricter conditions.
If guidelines are stricter then what's the claim? DOD killing your competition for you?
OpenAI@OpenAI
Yesterday we reached an agreement with the Department of War for deploying advanced AI systems in classified environments, which we requested they make available to all AI companies. We think our deployment has more guardrails than any previous agreement for classified AI deployments, including Anthropic's. Here's why: openai.com/index/our-agre…
English
@diyerxx @sarahookr Errors like these don't invalidate the utility of benchmarks but they do limit how useful they are to evaluation.
My point is, you can't evaluate simply by looking at the numerical result. Analysis is the hard part, not the easy part
English
@diyerxx @sarahookr You can also explore more yourself, here's another obvious example. But there's even problems with some classes. Label 836 is "sunglass" and 837 is "sunglasses".
huggingface.co/datasets/mrm84…
English

Got burned by an Apple ICLR paper — it was withdrawn after my Public Comment.
So here’s what happened. Earlier this month, a colleague shared an Apple paper on arXiv with me — it was also under review for ICLR 2026.
The benchmark they proposed was perfectly aligned with a project we’re working on.
I got excited after reading it. I immediately stopped my current tasks and started adapting our model to their benchmark.
Pulled a whole weekend crunch session to finish the integration… only to find our model scoring absurdly low.
I was really frustrated. I spent days debugging, checking everything — maybe I used it wrong, maybe there was a hidden bug.
During this process, I actually found a critical bug in their official code:
* When querying the VLM, it only passed in the image path string, not the image content itself.
The most ridiculous part? After I fixed their bug, the model's scores got even lower!
The results were so counterintuitive that I felt forced to do deeper validation. After multiple checks, the conclusion held: fixing the bug actually made the scores worse.
At this point I decided to manually inspect the data. I sampled the first 20 questions our model got wrong, and I was shocked:
* 6 out of 20 had clear GT errors.
* The pattern suggested the “ground truth” was model-generated with extremely poor quality control, leading to tons of hallucinations.
* Based on this quick sample, the GT error rate could be as high as 30%.
I reported the data quality issue in a GitHub issue. After 6 days, the authors replied briefly and then immediately closed the issue.
That annoyed me — I’d already wasted a ton of time, and I didn’t want others in the community to fall into the same trap — so I pushed back. Only then did they reopen the GitHub issue.
Then I went back and checked the examples displayed in the paper itself.
Even there, I found at least three clear GT errors.
It’s hard to believe the authors were unaware of how bad the dataset quality was, especially when the paper claims all samples were reviewed by annotators. Yet even the examples printed in the paper contain blatant hallucinations and mistakes.
When the ICLR reviews came out, I checked the five reviews for this paper.
Not a single reviewer noticed the GT quality issues or the hallucinations in the paper's examples.
So I started preparing a more detailed GT error analysis and wrote a Public Comment on OpenReview to inform the reviewers and the community about the data quality problems.
The next day — the authors withdrew the paper and took down the GitHub repo.
Fortunately, ICLR is an open conference with Public Comment. If this had been a closed-review venue, this kind of shoddy work would have been much harder to expose.
So here’s a small call to the community:
For any paper involving model-assisted dataset construction, reviewers should spend a few minutes checking a few samples manually. We need to prevent irresponsible work from slipping through and misleading everyone.
Looking back, I should have suspected the dataset earlier based on two red flags:
* The paper’s experiments claimed that GPT-5 has been surpassed by a bunch of small open-source models.
* The original code, with a ridiculous bug, produced higher scores than the bug-fixed version.
But because it was a paper from Big Tech, I subconsciously trusted the integrity and quality, which prevented me from spotting the problem sooner.
This whole experience drained a lot of my time, energy, and emotion — especially because accusing others of bad data requires extra caution.
I’m sharing this in hopes that the ML community remains vigilant and pushes back against this kind of sloppy, low-quality, and irresponsible behavior before it misleads people and wastes collective effort.
#ICLR #ICLR2026 #NeurIPS #CVPR #openreview #MachineLearning #LLM #VLM

English
Steven Walton retweetledi

well someone has been preaching this at us for like 6+ years
glad we are past the 'feel the agi' phase and back to building toward human-level intelligence
Dwarkesh Patel@dwarkesh_sp
“The thing that happened with AGI and pretraining is that in some sense they overshot the target. You will realize that a human being is not an AGI. Because a human being lacks a huge amount of knowledge. Instead, we rely on continual learning. If I produce a super intelligent 15 -year -old, they don't know very much at all. A great student, very eager. [You can say,] ‘You go and be a programmer. You go and be a doctor. Go and learn.’ So you could imagine that the deployment itself will involve some kind of a learning trial and error period. It's a process as opposed to, you drop the finished thing.” @ilyasut
English



In 2025, the DeepSeek “Sputnik" shocked the world, wiping out a trillion $ from the stock market. DeepSeek [7] distills knowledge from one neural network (NN) into another. Who invented this? people.idsia.ch/~juergen/who-i…
NN distillation was published in 1991 by yours truly [0]. Section 4 on a "conscious" chunker NN and a "subconscious” automatiser NN [0][1] introduced a general principle for transferring the knowledge of one NN to another. Suppose a teacher NN has learned to predict (conditional expectations of) data, given other data. Its knowledge can be compressed into a student NN, by training the student NN to imitate the behavior of the teacher NN (while also re-tarining the student NN on previously learned skills such that it does not forget them).
In 1991, this was called "collapsing" or "compressing" the behavior of one NN into another. Today, this is widely used, and also referred to as “distilling" [2][6] or "cloning" the behavior of a teacher NN into that of a student NN. It even works when the NNs are recurrent and operate on different time scales [0][1]. See also [3][4].
REFERENCES (more in Technical Note IDSIA-12-25 [5])
[0] J. Schmidhuber. Neural sequence chunkers. Tech Report FKI-148-91, TU Munich, April 1991.
[1] J. Schmidhuber. Learning complex, extended sequences using the principle of history compression. Neural Computation, 4(2):234-242, 1992. Based on [0].
[2] O. Vinyals, J. A. Dean, G. E. Hinton. Distilling the Knowledge in a Neural Network. Preprint arXiv:1503.02531 [stat.ML], 2015. The authors did not cite the original 1991 NN distillation procedure [0][1][DLP], not even in their later patent application.
[3] J. Ba, R. Caruana. Do Deep Nets Really Need to be Deep? NIPS 2014. Preprint arXiv:1312.6184 (2013).
[4] C. Bucilua, R. Caruana, and A. Niculescu-Mizil. Model compression. SIGKDD International conference on knowledge discovery and data mining, 2006.
[5] J. Schmidhuber. Who invented knowledge distillation with artificial neural networks? Technical Note IDSIA-12-25, IDSIA, Nov 2025
[6] How 3 Turing awardees republished key methods and ideas whose creators they failed to credit. Technical Report IDSIA-23-23, 2023
[7] DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. Preprint arXiv:2501.12948, 2025

English
Btw, there are more mistakes. Can you find them?
There's some more obvious ones (at least one "physically impossible" one) and a few that are far more subtle.
Regardless, Nano Banana is very impressive. Mistakes like these are hard to catch, so keep an attentive eye out.
English
It is also a good example of why researchers are arguing about "understanding".
Does it understand?
- It got the right answer, so it must!
- The steps were wrong, so it actually doesn't!
Or maybe something more complex is going on...
We still don't know
English
Very impressive, but also wrong.
There's 2 mistakes in the first physics problem on the LHS.
It did the derivative wrong, but fixed its mistake with another mistake! (better explanation in alt text)
ChatGPT looked at the end, not the answer.

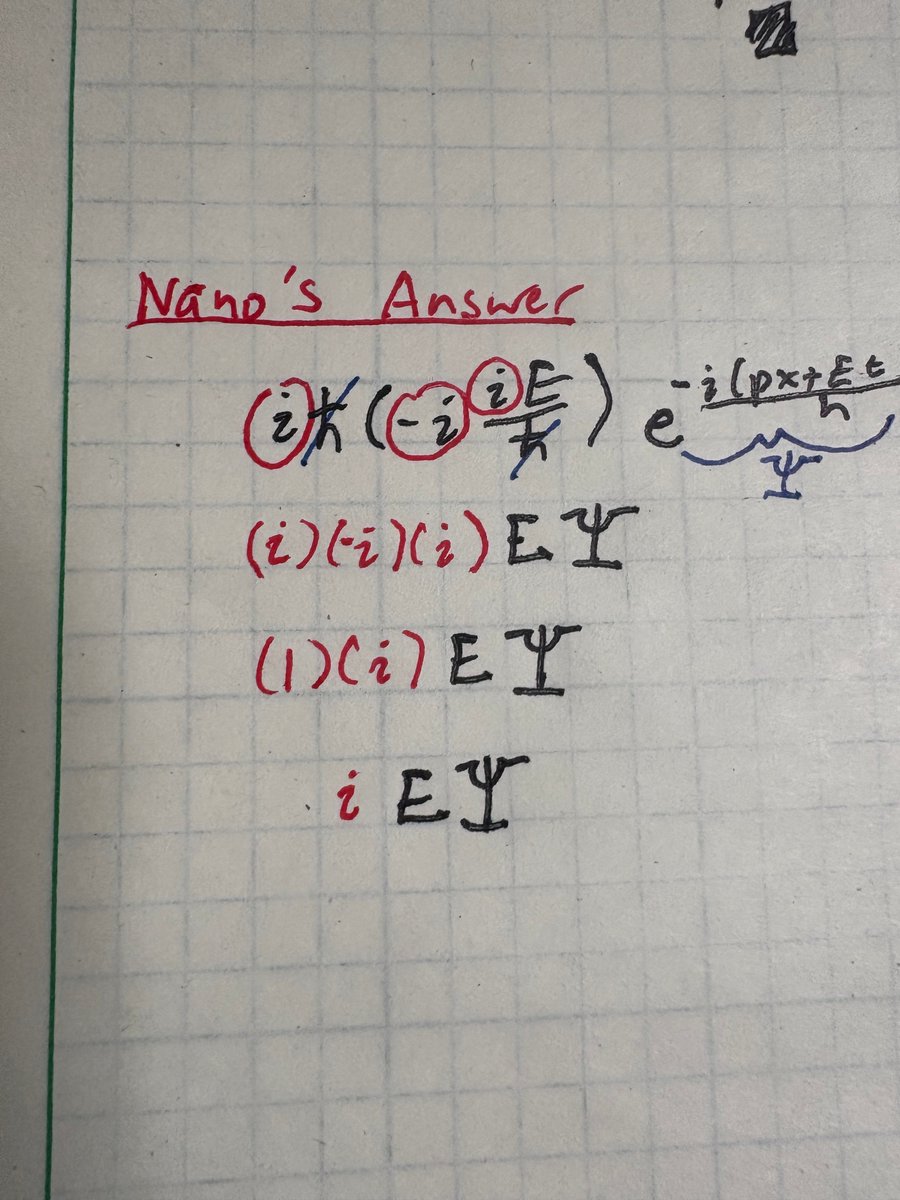
Andrej Karpathy@karpathy
Gemini Nano Banana Pro can solve exam questions *in* the exam page image. With doodles, diagrams, all that. ChatGPT thinks these solutions are all correct except Se_2P_2 should be "diselenium diphosphide" and a spelling mistake (should be "thiocyanic acid" not "thoicyanic") :O
English

@simonw @mitchellh @doodlestein That's absolutely mindboggling. I mean I can `vimdiff` or `git diff` thousands of lines on a machine with outdated hardware without breaking a sweat.
Something went terribly wrong and these "solutions" look like patches kicking a can down the road. Talk about tech debt...
English

@mitchellh @doodlestein I'm sad that the "let's rewrite GitHub in React" lobby finally won out, it used to be SO performant
English

GitHub feels like a product that isn't used by the people that work there. That can't POSSIBLY be true, I know. I just hit issues everyday that really make me wonder... how can this bug exist? More likely engineers aren't empowered to fix things and are bogged down by red tape.
English
@doodlestein @jwkicklighter @mitchellh The problem here that @jwkicklighter is pointing out is that this doesn't just "get work done." This type of solution adds more complexity and this gets compounded upon again and again.
Your attempts to make things simple have only increased complexity, not decreased ir.
English

@jwkicklighter @mitchellh Ok whatever, you can be an idealist on your machine, other people need to get work done. It’s a good suggestion if he actually wants to avoid wasting his time on a broken site he doesn’t control.
English
@keenanisalive Sure, you can make accurate predictions without causal models or consistency but those will always be brittle and can't generalize. I just don't see how it can generalize without causality and consistency.
English
@keenanisalive What does "accurate physics" mean? Which physics?
I feel "world model" often gets used in a weird way as if there is only one world and one physics. I think building causal relationships and consistency seems more important than which world is actually being modeled.
English

I don't have a strong opinion about whether video models “understand the world.”
But I do think the first bar should be checking whether you can recover consistent geometry from video—not whether it makes accurate predictions of physics.
(“Accurate physics” is not even well-posed unless the geometry defining the physical experiment is well-defined.)

English