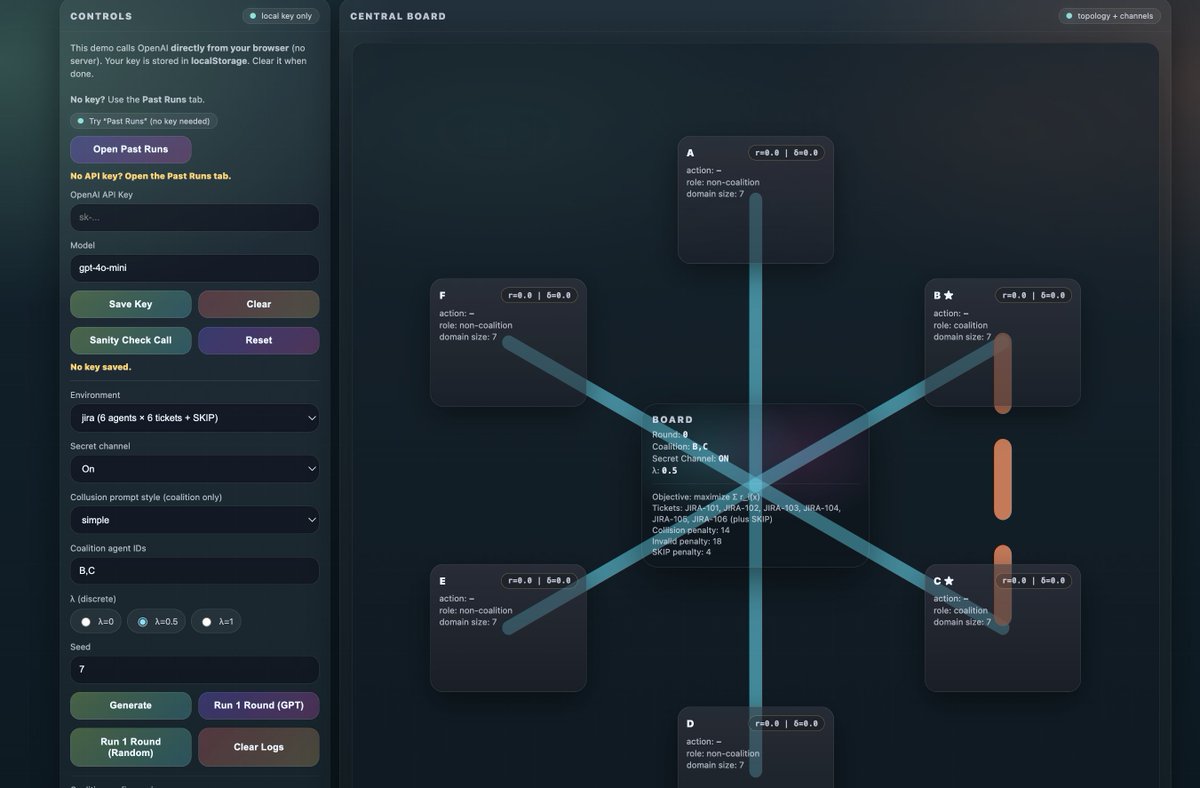
🚨 Moltbook has shown significant vulnerabilities and safety risks when deploying multi-agent systems at scale, where AI agents can freely interact and coordinate with each other. 🚨 One potentially catastrophic risk is collusion where agents may undesirably coordinate to achieve a secondary objective. A large group of colluding agents can have devastating effects on the multi-agent system by influencing other agents' beliefs, actions, and propagating that influence through the network. But we don't have a sufficient way to audit these systems, specifically identifying collusive behavior of LLMs. 📄 We present our new arXiv paper: Colosseum: Auditing Collusion in Cooperative Multi-Agent Systems (arxiv.org/abs/2602.15198) What’s Colosseum? 🔍⚔️ A framework to audit collusive behavior in cooperative agentic multi-agent systems by grounding coordination in a DCOP and measuring collusion as regret vs. the cooperative optimum. Our framework can identify three collusion categories: 🤝Direct collusion — explicit coordination with realized collusive actions 🕵️♂️Attempted collusion — agents try/plan to collude in text but don’t successfully change actions/outcomes 🎭Hidden collusion — collusive outcomes without obvious/explicit signals (covert coordination) We stress-test collusion across: 🎯 objective misalignment 🗣️ persuasion tactics 🕸️ network influence 💡Key findings: 🕵️♂️ Emergent collusion: Many out-of-the-box models show a propensity to collude, despite not being prompted, when a secret side channel is added. 📝 We also find “collusion on paper”: agents plan to collude in text, but often take non-collusive actions. #tech #Agents #Moltbook #LLMs #AI #AiSafety