
W. Nakabayashi
724 posts

W. Nakabayashi
@WidVelv
At times, what defeats a person is not a strong enemy but one’s own heart.
Katılım Ocak 2022
77 Takip Edilen40 Takipçiler


Todo welfare state chega num ponto em que a conta não fecha mais.
Na França, aposentados ganham mais do que a população em idade ativa.
É insustentável demograficamente: cada vez menos jovens trabalhando para sustentar cada vez mais idosos bem pagos.
O Brasil vai pelo mesmo caminho, com um agravante: estamos repetindo o modelo antes de ter a riqueza que a França acumulou.

Português
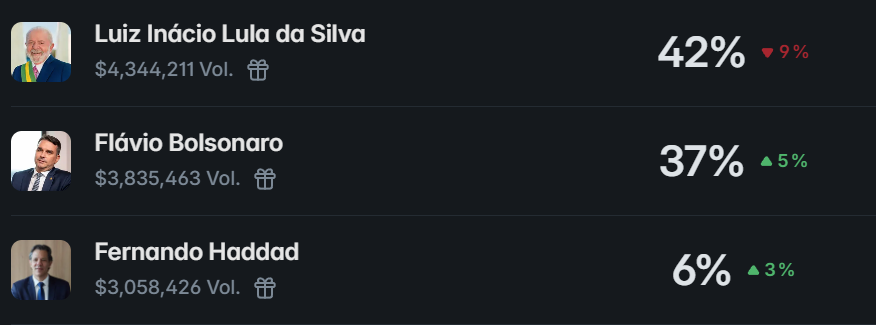
@RobertoReis Só confio nisso aqui 👇
Preciso olhar novamente nas seguintes datas: 05/04 e 05/09
Português

Quem fala em Lula IV não tem a menor noção do que está dizendo.
Não entende a dinâmica eleitoral. Só enxerga a foto do momento. Só se baseia no que a imprensa fala.
Na mesma época, em 2022, Lula tinha os mesmos 9 a 10% de vantagem nas pesquisas.
E havia um detalhe gigante:
em São Paulo, o maior colégio eleitoral, o governador João Dória era desafeto de Bolsonaro. Um dos piores rompimentos do “mito”.
Hoje, o governador de São Paulo é Tarcísio de Freitas. O cenário é outro.
Mesmo assim, com a máquina na mão, Lula não consegue ampliar a distância nas pesquisas.
De lá para cá, a rejeição aumentou, e o desgaste do presidencialismo de coalizão cobrará a conta.
Além disso, em 2022, os outros candidatos à presidência eram de esquerda e centro esquerda: Ciro, Tebet e Marina Silva.
Isso inclinou o pêndulo eleitoral a favor de Lula no segundo turno.
Se apenas 1% desse eleitor do meio mudar de lado para nomes atuais de centro direita, é caixão para Lula.
Hoje temos Aldo, Renan, Zema e Ratinho (todos anti-Lula) somando 16% já, sem sequer serem conhecidos.
É uma onda de direita.
A desorganização é temporária.
Para finalizar:
em 2022 o presidente dos EUA era Biden. Agora é Trump. Isso também pesa.
E a grande sacada é simples: partido de centrão não gosta de A ou B. Vai para onde houver mais ministérios, mais verba, mais espaço.
E, nesse jogo, a direita tem muito mais liquidez a oferecer do que um governo Lula IV.
É só esperar…
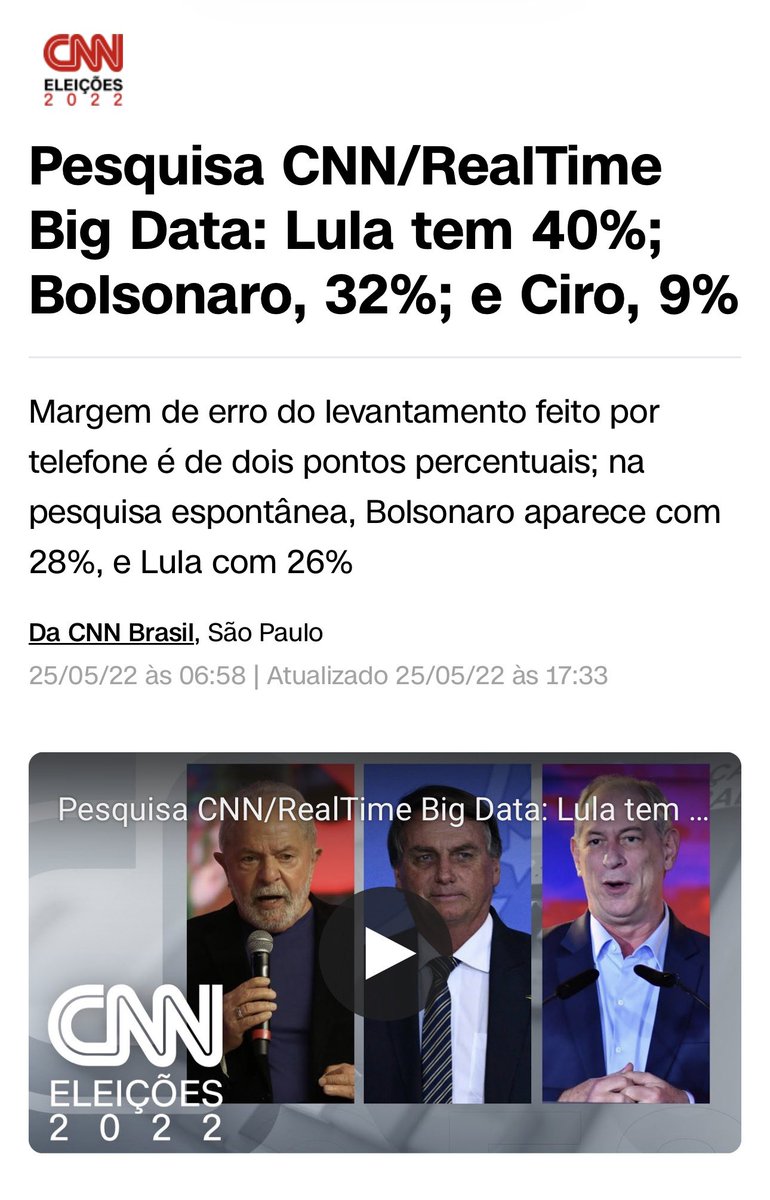
Eleições em Pauta@eleicoesempauta
🇧🇷 REAL TIME BIG DATA: Pesquisa para presidente. 🔴 Lula (PT): 39% 🟢 Flávio Bolsonaro (PL): 30% 🔵 Ratinho Junior (PSD): 10% 🟠 Romeu Zema (Novo): 3% ⚫ Aldo Rebelo (DC): 2% 🟡 Renan Santos (Missão): 1%
Português

To all the serious traders still using this app:
What if you actually came back after this holiday weekend sharper than you left
No charts, just deliberately leveling up your trading routine and process.
Here are a few pointers from today's trading routine doc
Happy Easter 🐈

English
@JJJJames16 Porque será que inverteu desde 2023? Tem alguma ideia James?
Português
@JJJJames16 Qual sua visão James, um dead cat bounce ou mudança estrutural bullish agora?
Português



Alguém me dá sugestão de fone de ouvido com cancelamento de ruído que seja maravilhoso, extremamente leve e que não seja aquele tipo demoníaco de enfiar dentro do ouvido?
Português
@JJJJames16 E eu procurando qual era a noticia para esse preço 😅
Português
@pedroaccorsi_ Como dizer que está comprado em Brava sem dizer que estar comprado em Brava ☝️
Português

Um negócio que me deixa incrédulo é empresa de commodity ficar travando preço.
A base do negócio literalmente é se expor à commodity — e a empresa não quer?
São anos esperando um ciclo de alta. Aí, quando o ciclo vem, não conseguem aproveitar porque travaram o preço lá embaixo.
Português
@igor_mundstock O bear market dos bonds está só no inicio, boa sorte para quem holda títulos longos.
Português

Os ventos mudaram, pois com o US02y acima da taxa de juro do Fed o mercado parece começar a precificar a necessidade de juros maiores no futuro.
A combinação de alta de juro e choque do petróleo pode caracterizar um cenário estagflacionário ou até recessivo e isso explica porque metais, metais básicos e ações corrigem.
James Picerno@jpicerno
Powell’s Pause: A Gamble Wrapped in Uncertainty: capitalspectator.com/powells-pause-…
Português

@_ffferreira O mercado de derivativos está segurando a vol, irá ver algo bem interessante a partir de abril. Triple-event já terá passado: decisão de juros nas majors em FX> USD, EUR, JPY, GBP, CAD, SEK e CHF. Derivativo: OPEX quad / fluxo: o ETF rebalancing.
Português

O que me surpreende mais não é apenas a quantidade de eventos que já tivemos esse ano (Venezuela, guerra no Irã, choque no petróleo, problemas no crédito privado nos EUA e Brasil, risco de disrupção crescente da IA).
Mas sim como os mercados seguem resilientes frente à tantos impactos exógenos em tão pouco tempo.
Podemos olhar isso sob o prisma do copo meio cheio (“Isso é ótimo sinal, porque uma vez acalmando o cenário, mercados voltam para as máximas), ou do copo meio vazio (“Mercado segue muito complacente e com riscos de uma correção maior frente aos inúmeros choques, do petróleo sendo o principal deles”).
Pelo sim, pelo não, preferimos seguir com a guarda elevada, sem tomar riscos desmedidos, e mantendo uma boa diversificação.
Como eu sempre falo: “não é hora de tentar ser HERÓI”
Quem pensa em fugir apenas para o caixa - em um cenário como esses - pode acabar perdendo grandes oportunidades adiante.
Português
@BigCheds It is incredibly beautiful!! Every movement is a trap for the hopeful ones.
English


Lembrando que o PPI de fevereiro nem refletiu a valorização dos itens de energia de março, vai piorar ainda mais. Ano passado Trump dizia que petróleo barato era bom para o americano, agora diz que petróleo caro fará o país ganhar muito dinheiro.
Igor Mundstock@igor_mundstock
Se Trump não desistir desse conflito a tempo, ele será responsável por dois choques inflacionários em menos de doze meses: tarifas (bens) e petróleo (energia). A inflação, medida pelo PCE, permanece mais próxima de 3% do que da meta do Fed.
Português


O cara casou com uma mulher gata que até lembra a Sydney Sweeney (ela não é IA, viu? Acompanho o casal…rs), mas o melhor são os comentários:
“Eu te entendo, amiga. Trabalhar de CLT é ruim.”
“Como o senhor conseguiu? Tem curso?”
“Por quê, amiga?”
O povo não para pra pensar que certamente ele deve cuidar muito bem dela e a faça feliz? Que diferença faz ela ser mais bonita que ele? Sinceramente? Casal bonito é aquele que se escolhe todos os dias, que se ama e que vive bem a dois.
Português
@igor_mundstock Nice! Poderia trazer essa tabela para nós 1 vez por trimestre ou semestre? vlw
Português
Mapas de calor transformam dados em cores, permitindo visualizar padrões, mudanças e intensidade. Reparem o estresse visível nos dados de crédito, inadimplência e endividamento do Brasil, a política monetária restritiva está ferindo a economia.

Português
@TXMCtrades I also remember your theses about a new trend in the bond market. After a long time of bull, it is now time for a bear market.
English

@femisapien_z Com o passar do tempo está se tornando mais claro os prováveis vencedores: Google e Anthropic.
CansadoGPT perdendo folego e agora o Grok com underperformance.
Português
This is a perfect example of mediocrity and irrelevance. Every other major model, when updated, jumped to the top.
Artificial Analysis@ArtificialAnlys
xAI has released Grok 4.20 for API access in beta, and it scores 48 on the Artificial Analysis Intelligence Index with reasoning enabled Compared to @xAI’s previous Grok 4 flagship, Grok 4.20 Beta 0309 is an intelligence upgrade, achieving +6 points on the Intelligence Index. It launches with a longer 2M token context window (up from Grok 4’s 256K context window, matching Grok 4.1 Fast’s 2M), and significantly lower pricing ($2/$6 vs Grok 4’s $3/$15). Grok 4.20’s performance lags behind the current intelligence frontier, but it performs strongly on instruction following and features a notably low hallucination rate, beating all other models we’ve tested on AA-Omniscience for hallucination. xAI released 3 variants: reasoning, non-reasoning, and multi-agent. We’ve evaluated the reasoning and non-reasoning modes, and are considering the best approach for testing the new multi-agent functionality, which parallelizes over multiple agents behind the scenes in one API call. Key takeaways: ➤ Improved intelligence over Grok 4: Grok 4.20 Beta 0309 (Reasoning) scores 48 on the Artificial Analysis Intelligence Index, +6 from Grok 4 and +9 compared to Grok 4.1 Fast. This score falls short of the current intelligence frontier at 57 (Gemini 3.1 Pro Preview and GPT-5.4) ➤ Low price for the level of intelligence: Grok 4.20 is priced at $2/$6 per 1M input/output tokens, representing a decrease compared with Grok 4’s $3/$15 API rates. The reasoning variant cost $484 to complete the evaluations in the Artificial Analysis Intelligence Index, which is a reduction of ~70% compared to Grok 4, driven by lower pricing and lower token use ➤ Leading non-hallucination rate: Grok 4.20 scores 78% in the AA-Omniscience non-hallucination metric. This is the best result we have seen yet for this metric, and reflects the model only answering around one fifth of the time when it did not know the answer ➤ Fast inference performance: xAI is serving Grok 4.20 at 267 tokens per second - similar to what we see for gpt-oss-120b across providers and on the Pareto frontier for speed versus intelligence ➤ Mixed improvements in tool use: Grok 4.20 improved on the tool calling performance of Grok 4 in some evaluations, scoring 97% on Tau2-Telecom. However, its score of 1,062 on GDPval-AA, our benchmark of general agent performance on real work tasks, is well behind frontier peers and sits approximately in line with Grok 4.1 Fast
English


Can someone explain to me what this token does and how the hell it maintains an $8.3 billion market cap?

English
@femisapien_z Não culpo ele, famoso post somente para engajamento. As coisas levam tempo, mesmo com o aparente progresso acelerado. Não chegamos nem na ASI e o cara falando de singularidade. 😅
Português
No entanto recentemente 2 papers importantíssimos foram publicados:
1. AI's hallucinate by design (cdn.openai.com/pdf/d04913be-3…)
commentary here: blogs.library.duke.edu/blog/2026/01/0…
2. AI's share a hivemind: arxiv.org/abs/2510.22954
Which IMHO is the anthithesis of "singularity".
Researches don't know how to solve these problems. Elon, as is expected, is projecting.
English

‘Elon Musk acabou de dizer que já estamos na Singularidade e, sinceramente, olha só o que aconteceu somente HOJE:
> Yann LeCun captou US$ 1 bilhão para construir IA que entende a realidade
> Meta comprou uma rede social onde humanos nem conseguem postar
> Nvidia publicou um blueprint mostrando que eles dominam todas as camadas da IA
> Claude lançou agentes que fazem o trabalho do seu programador sênior por US$ 15
> Economistas disseram que 20% dos empregos de escritório vão desaparecer em breve
> Startups britânicas pararam completamente de contratar humanos
> Ações de TI indianas desabaram porque IA escreve código mais barato que outsourcing...
É só uma terça-feira normal.
Ray Kurzweil previu que a Singularidade chegaria em 2045. Elon acabou de dizer que ela já está aqui. E depois de ver o que rolou nas últimas 12 horas, não sei se ele está errado.’
Por @TukiFromKL
Português