How to create a ssh key 🗝️
Open terminal and enter:
ssh-keygen -t ed25519 -C "your@email.com"
-t: Encryption algorithm
-C: Comment/label
RSA: Old, based on factoring large numbers, may have future risks.
DSA: Old US government algorithm, no longer recommended.
ECDSA: New, uses elliptic curves for security.
Ed25519: New, added in OpenSSH, promising but not universally supported.
For example you can connect to GitHub without supplying your username and personal access token at each visit. When you connect via SSH, you authenticate using a private key file on your local machine.
On windows the "ssh-keygen" command is executed by the Linux distribution running within WSL. Keys generated in Linux filesystem.
On macOS Terminal "ssh-keygen" invokes Unix-based tool in macOS environment. Keys generated within macOS.
🖥️🍏
#SSH#Security#TechTips"
@cherniav Sensorless for bad environment, although I saw a new algorithm for zero speed full torque in the STM ecosystem. Not for 431, I think. Also, the software isn’t working in different language versions of Windows. st.com/content/st_com…
do NOT try to use sensorless FOC algorithms if you need to build a motor controller that actually works in any reasonable amount of time
we do these things not because they are easy, but because we thought they would be easy
If you want to drive the community they need to listen you. But for now the other community can to despise you because of false believes in your community and lack of vision. This is a safety breach because a lot of companies can use this.
When the engagement load is not on the persons media quality is really downs. We are like the our own media companies in change other ones news. As grok grows it will be better
Transformers are taking every domain of ML by storm! I think it is becoming more and more important to understand the basics, so pay attention because Attention is there to stay!
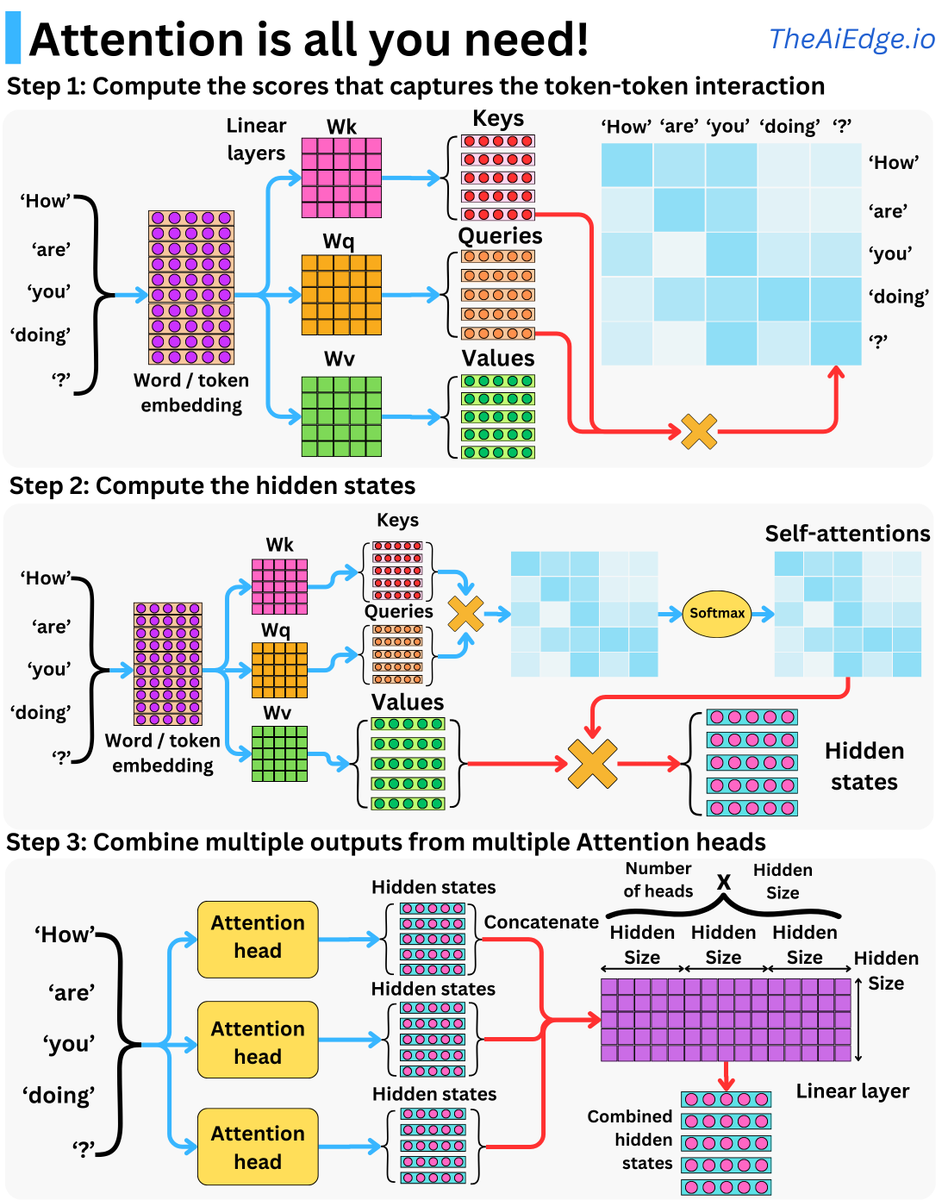
At the center of Transformers is the self-attention mechanism, and once you get the intuition, it is not too difficult to understand. Let me try to break it down:
As inputs to a transformer, we have a series of contiguous inputs, for example, words (or tokens) in a sentence. When it comes to contiguous inputs, it is not too difficult to see why time series, images, or sound data could fit the bill as well.
Each has its vector representation in an embedding matrix. As part of the attention mechanism, we have 3 matrices Wq, Wk, and Wv, that project each of the input embedding vectors into 3 different vectors: the Query, the Key, and the Value. This jargon comes from retrieval systems, but I don't find them particularly intuitive!
For each word, we take its related Key vector and compute the dot products to the Query vectors of all the other words. This gives us a sense of how similar the Queries and the Keys are, and that is the basis behind the concept of "attention": how much attention should a word pay to another word in the input sequence for the specific learning task? A Softmax transform normalizes and further accentuates the high similarities of the resulting vector. This resulting matrix is called the self-attentions!
This results in one vector for each word. For each of the resulting vectors, we now compute the dot products to the Value vectors of all the other words. We now have computed hidden states or context vectors!
Repeat this process multiple times with multiple attention layers, and this gives you a multi-head attention layer. This helps diversify the learning of the possible relationships between the words. The resulting hidden states are combined into final hidden states by using a linear layer.
The original Transformer block is just an attention layer followed by a set of feed-forward layers with a couple of residual units and layer normalizations. A "Transformer" model is usually multiple Transformer blocks, one after the other. Most language models follow this basic architecture. I hope this explanation helps people trying to get into the field!
--
👉 Don't forget to subscribe to my ML newsletter newsletter.TheAiEdge.io
--