
Haoxuan You retweetledi

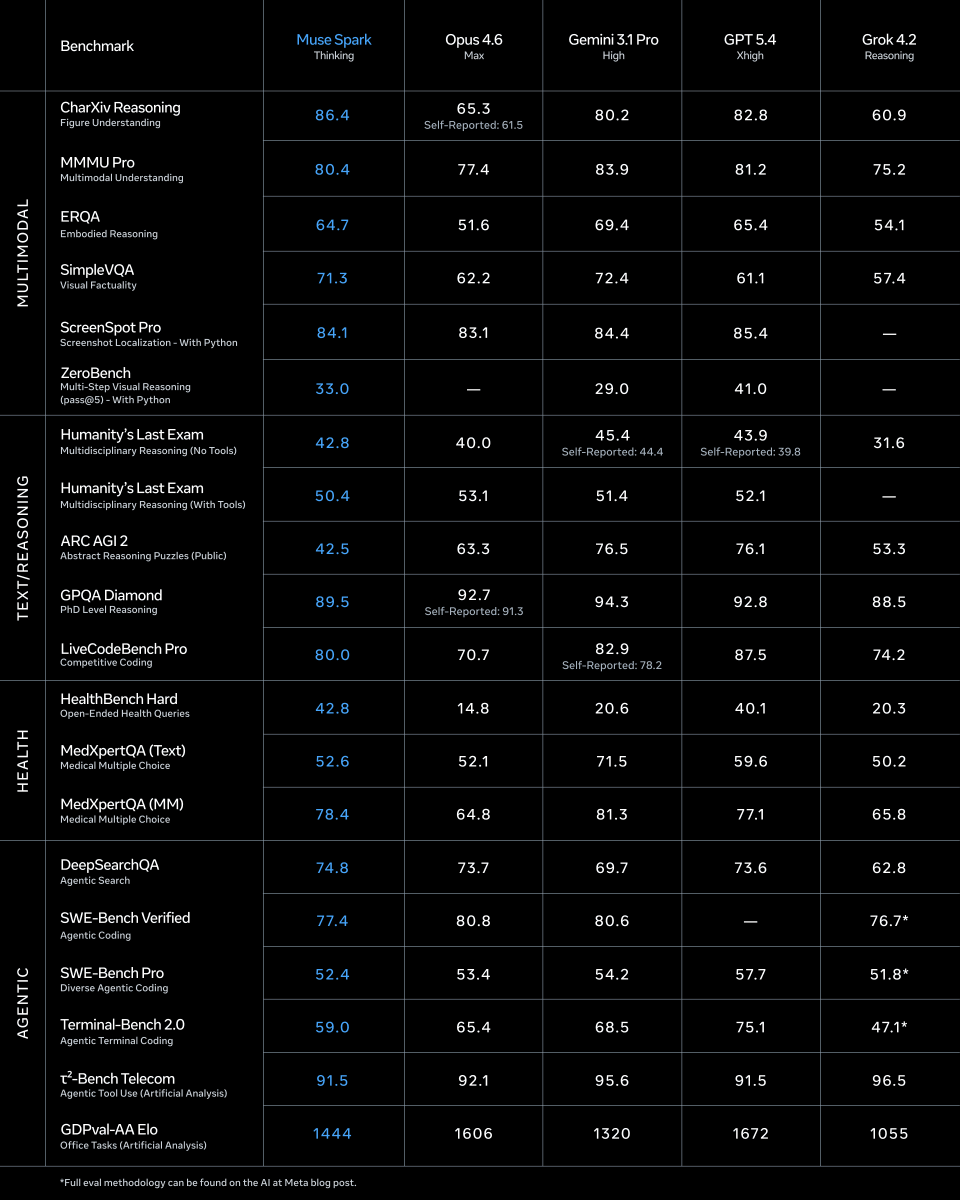
Happy to share Muse Spark, a natively multimodal reasoning model w/ tool-use, visual chain of thought, and multi-agent orchestration! It’s been a fulfilling journey not just building the model, but the team and culture behind it. Now live in product.
ai.meta.com/blog/introduci…
English








