Yichuan Deng retweetledi

📢📢📢 Releasing OpenThinker3-1.5B, the top-performing SFT-only model at the 1B scale! 🚀
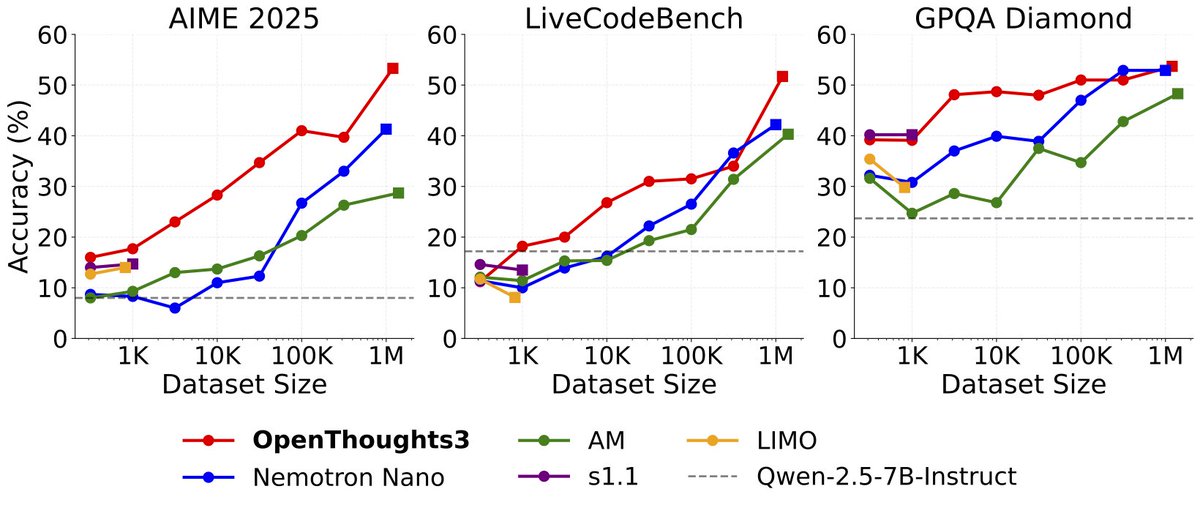
OpenThinker3-1.5B is a smaller version of our previous 7B model, trained on the same OpenThoughts3-1.2M dataset.

English
Yichuan Deng
5 posts


@YCEthanDeng
Ph.D. Student in CS @uwcse, previous undergrad at School of the Gifted Young @ustc




github.com/mlfoundations/… I’m excited to introduce Evalchemy 🧪, a unified platform for evaluating LLMs. If you want to evaluate an LLM, you may want to run popular benchmarks on your model, like MTBench, WildBench, RepoBench, IFEval, AlpacaEval etc as well as standard pre-training metrics like MMLU. This requires you to download and install more than 10 repos, each with different dependencies and issues. This is, as you might expect, an actual nightmare. (1/n)