Sabitlenmiş Tweet

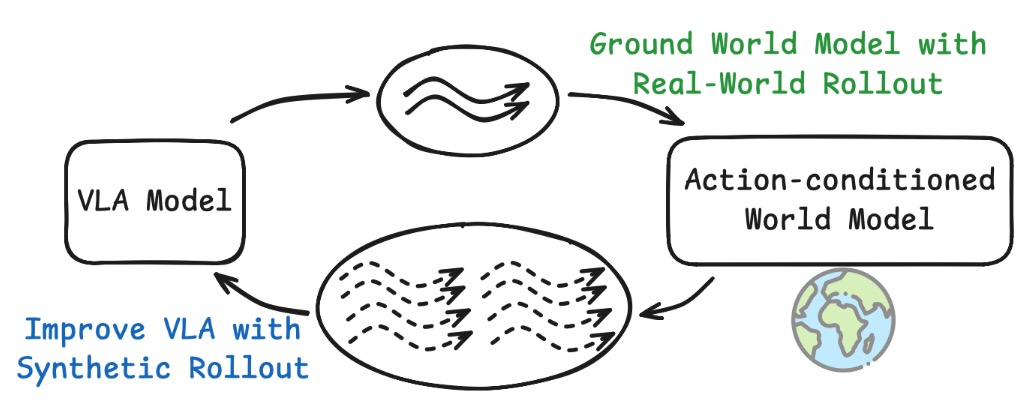
Excited to share VLAW: Iterative Co-Improvement of Vision-Language-Action Policy and World Model
We explore improving VLA inside a learned world model, and find that the key is to jointly improve VLA and WM!
Website: sites.google.com/view/vlaw-arxiv
English









