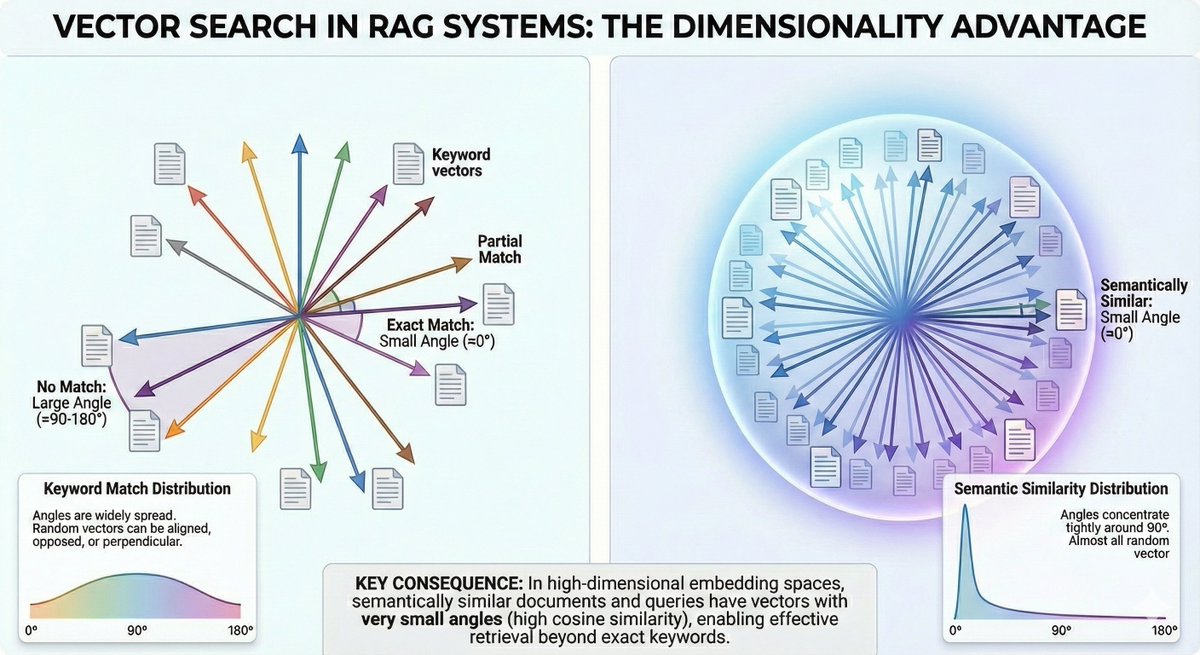
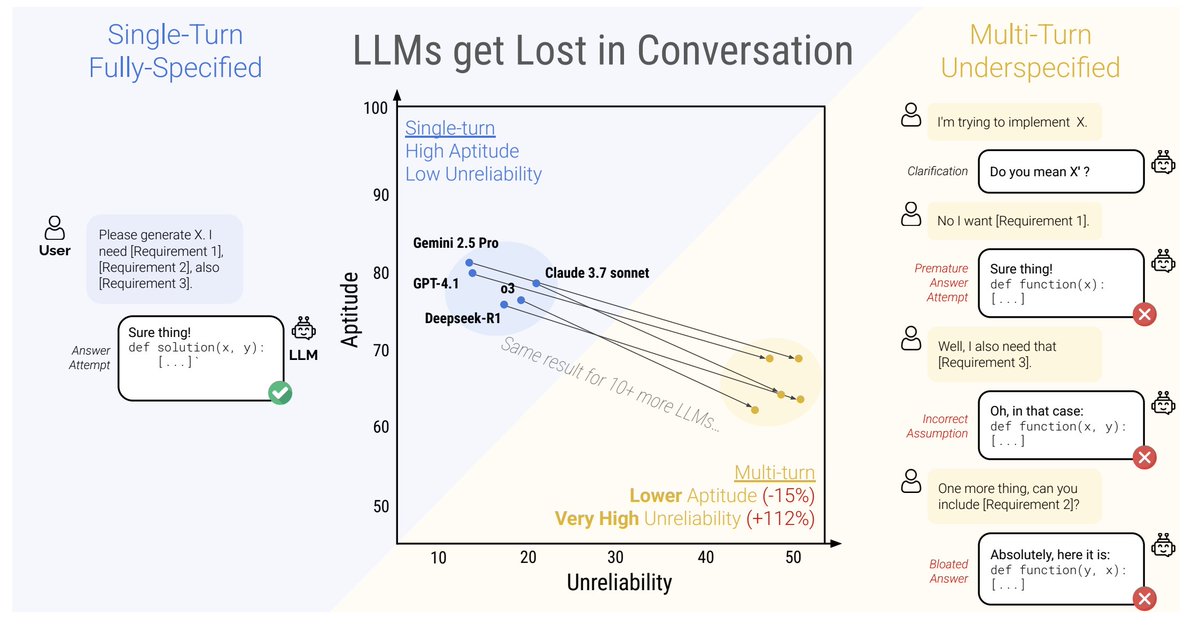
Podcast with @AndrisKulbergs - Prime Minister candidate - Can AI replace politicians? Full episode: youtu.be/DHwvgHEuMnE

YouTube

English
Evalds Urtans
235 posts

@YellowRobotXYZ
Founder, AI Researcher, Public Speaker More videos: https://t.co/0co5SU0SrQ











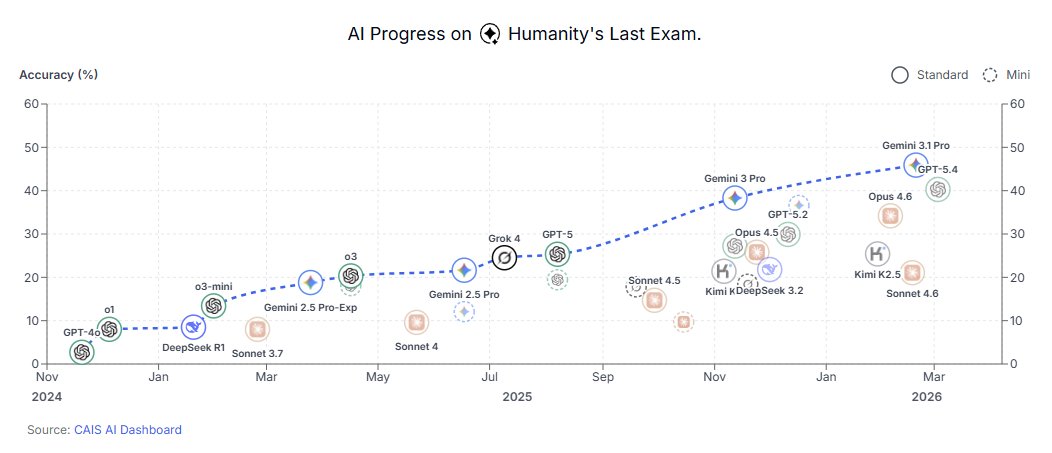

Australian tech entrepreneur Paul Conyngham explains how he used ChatGPT/AlphaFold (spent $3,000 with no biology background) to create a custom MRNA vaccine to treat his dog’s cancer tumors. Unreal.