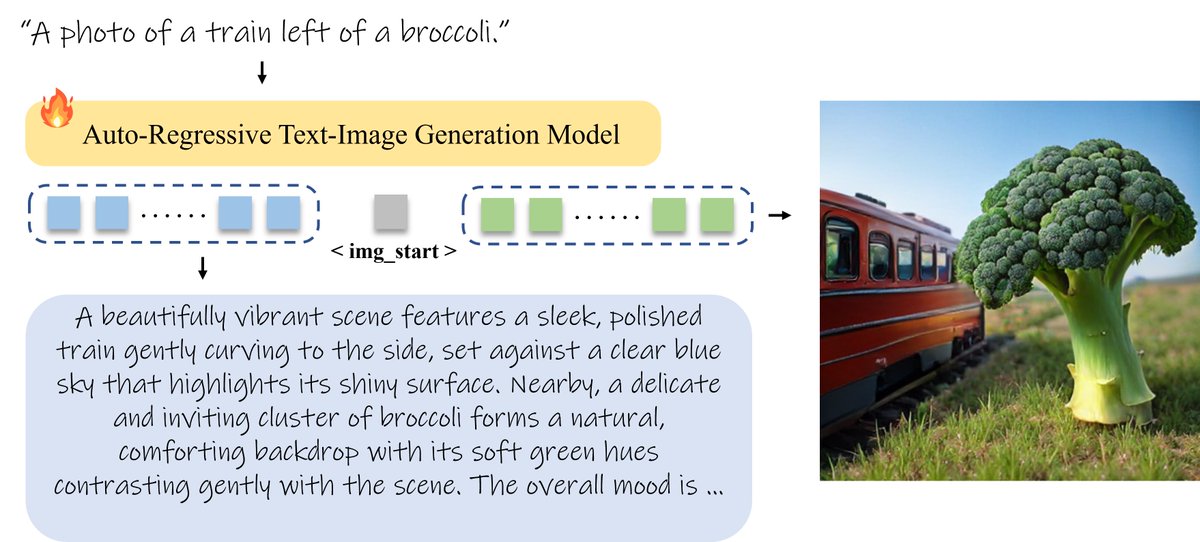
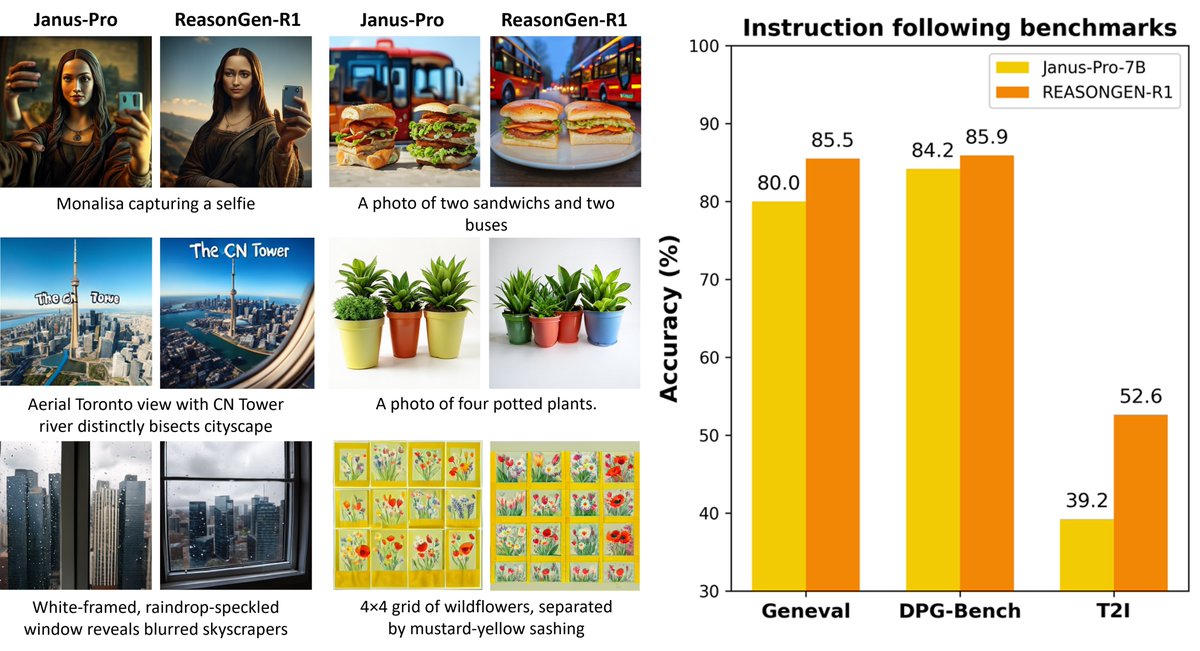
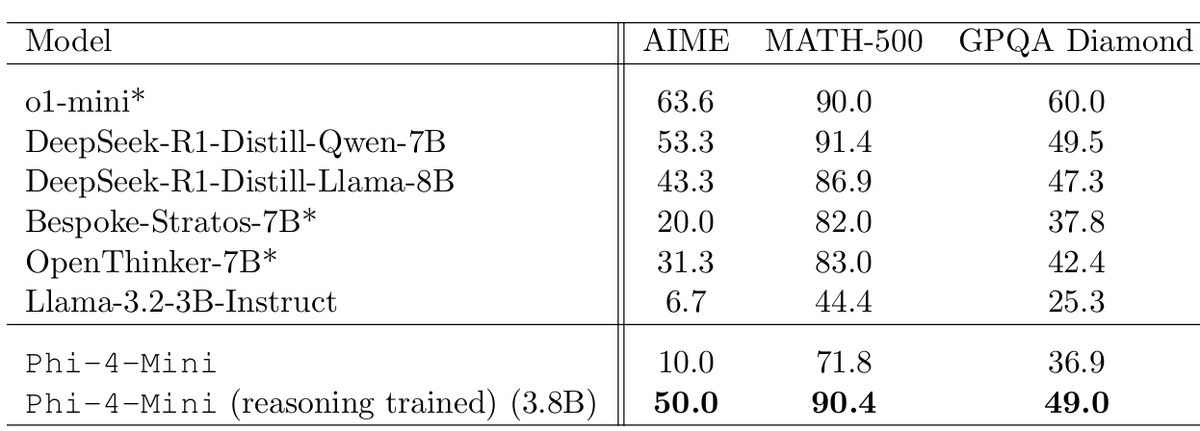
Sabitlenmiş Tweet

🌟 Tired of CLIP's limitations and short input windows?
✨ Meet LLM2CLIP—our secret to making the SOTA CLIP model even more SOTA! By enabling LLMs to act as CLIP's "teacher," we achieve significant performance gains with minimal data and training.
We found that LLMs struggle to distinguish image captions, making CLIP training confusing. But with our caption-to-caption contrastive finetuning, LLMs reveal their text comprehension in output features, becoming the ideal mentor for CLIP. 🧑🏫
LLM2CLIP overcomes CLIP’s weaknesses: limited text understanding, bag-of-words-like behavior, short input windows, and structural challenges with dense, complex captions. With LLM's open-world knowledge, we maximize CLIP’s capacity on dense captions, achieving efficient and robust training across various text retrievals and LLava benchmarks. 🚀
📄 Paper: huggingface.co/papers/2411.04… review and already accept at NeurIPS 2024 SSL Workshop.
🔗 Models & Code: aka.ms/llm2clipReady to give your CLIP a "super private tutor" or use our top-performing CLIP model!
#LLM2CLIP #CLIP #MachineLearning #AI #NeurIPS2024 #ContrastiveLearning #DeepLearning #AIResearch
English