Sabitlenmiş Tweet

👀Your small LMs (SLMs) are… not that fast?
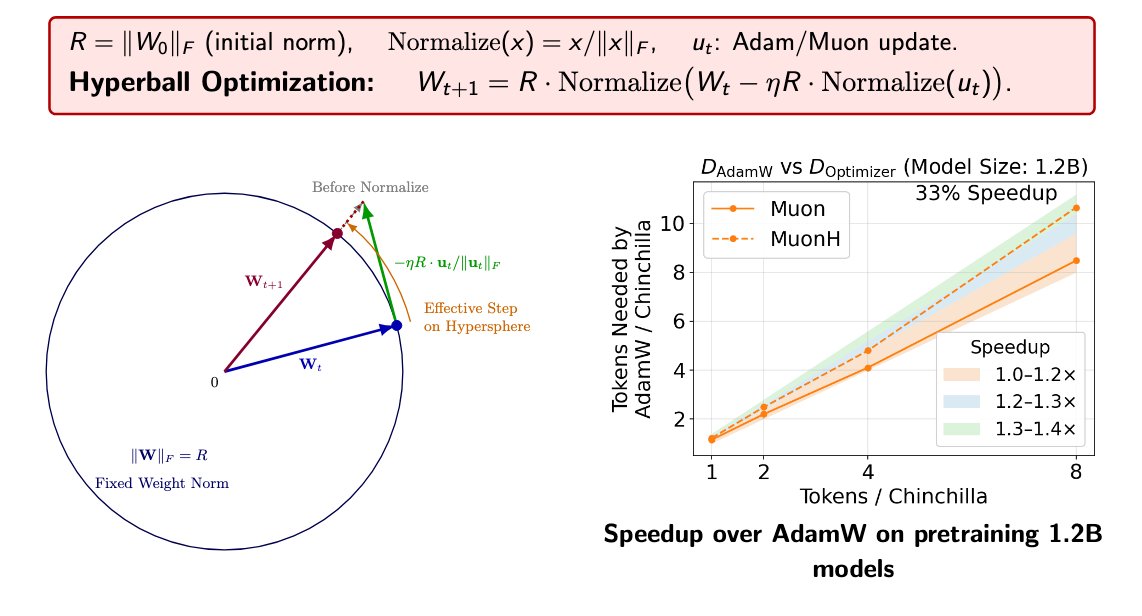
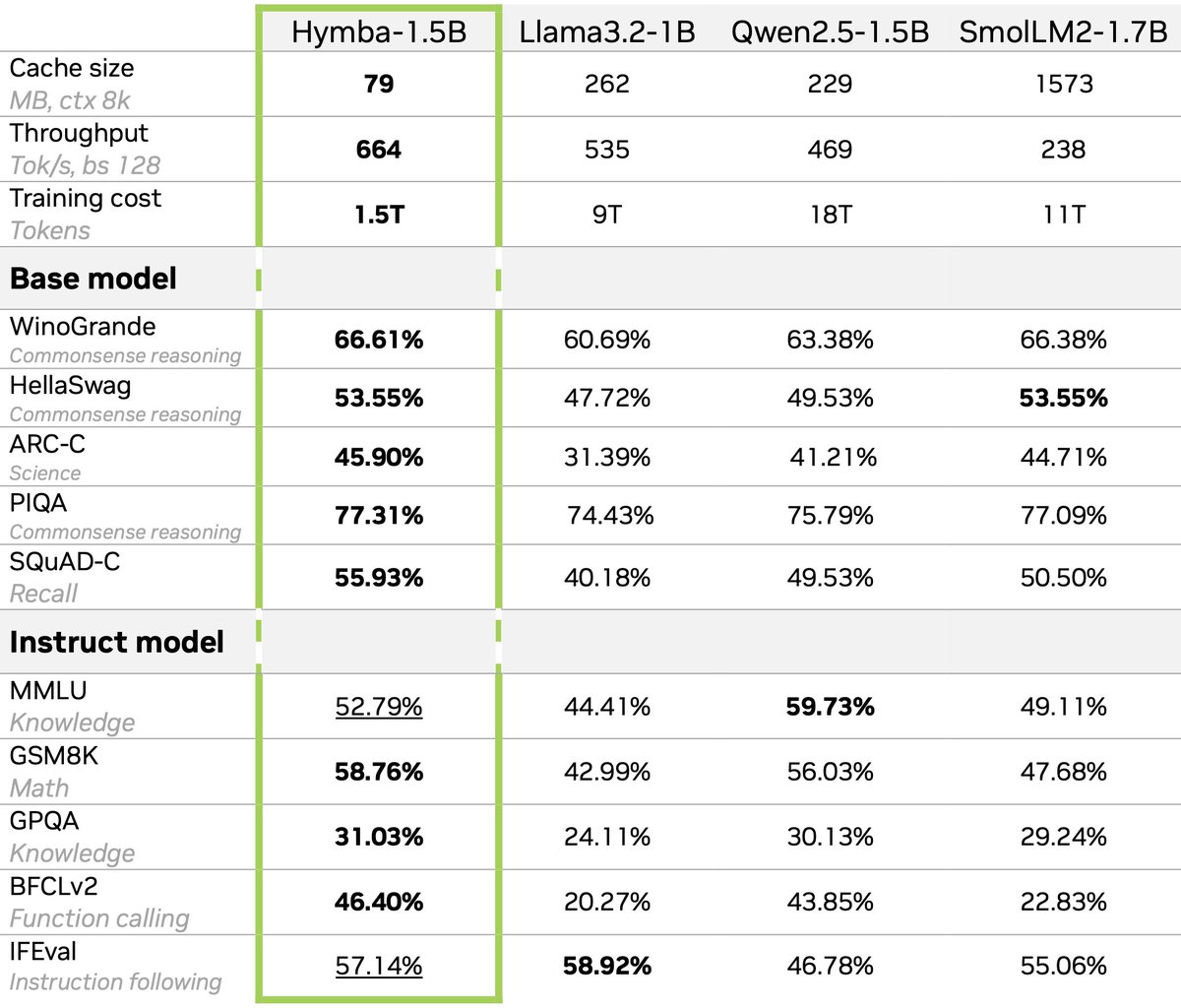
🚀At NVIDIA Research, we release 𝐍𝐞𝐦𝐨𝐭𝐫𝐨𝐧-𝐅𝐥𝐚𝐬𝐡 (NeurIPS 2025), a hybrid SLM family designed around real-world latency and trained from scratch with 1B/3B sizes, achieving SOTA accuracy, latency, and throughput.
🌟𝐍𝐞𝐦𝐨𝐭𝐫𝐨𝐧-𝐅𝐥𝐚𝐬𝐡 𝐡𝐚𝐬 𝐛𝐞𝐞𝐧 𝐢𝐧𝐭𝐞𝐠𝐫𝐚𝐭𝐞𝐝 𝐢𝐧𝐭𝐨 𝐓𝐑𝐓𝐋𝐋𝐌 𝐟𝐨𝐫 𝐩𝐫𝐨𝐝𝐮𝐜𝐭𝐢𝐨𝐧-𝐠𝐫𝐚𝐝𝐞 𝐢𝐧𝐟𝐞𝐫𝐞𝐧𝐜𝐞 with up to 41K tokens/second on a single H100 GPU! Try it following the instructions in our HF repo.
Will share more details at NeurIPS’25 (poster on Thursday, 11am–2pm)!
𝐏𝐚𝐩𝐞𝐫 𝐋𝐢𝐧𝐤: arxiv.org/pdf/2511.18890
🤗 𝐇𝐅 𝐦𝐨𝐝𝐞𝐥𝐬:
Nemotron-Flash-1B: huggingface.co/nvidia/Nemotro…
Nemotron-Flash-3B: huggingface.co/nvidia/Nemotro…
Nemotron-Flash-3B-Instruct: huggingface.co/nvidia/Nemotro…

English