Sabitlenmiş Tweet

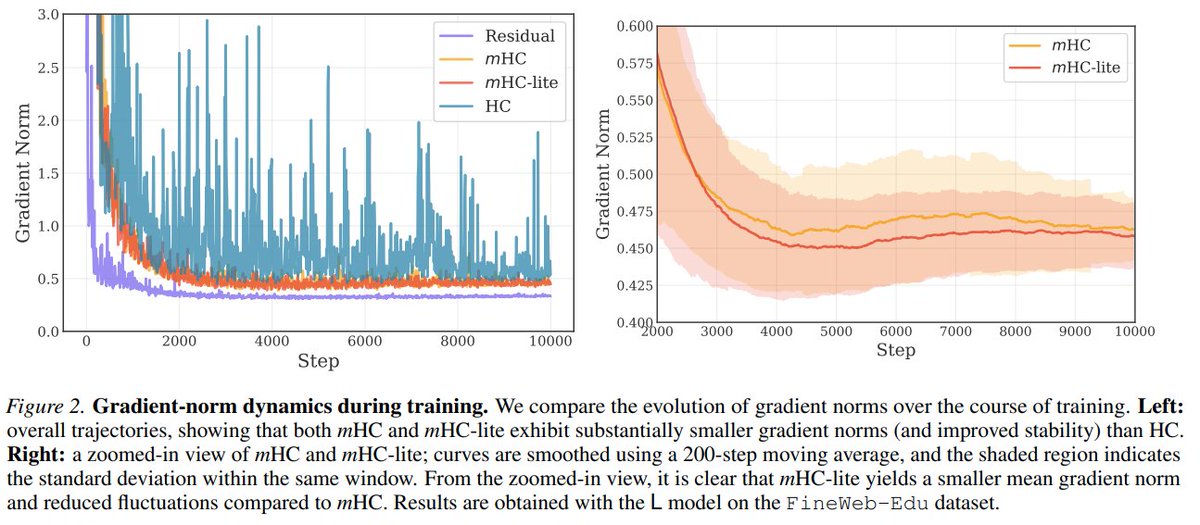
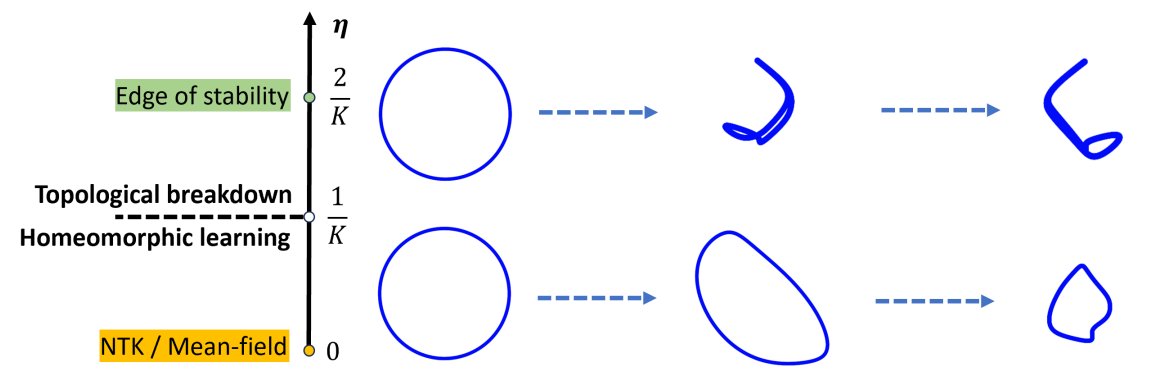
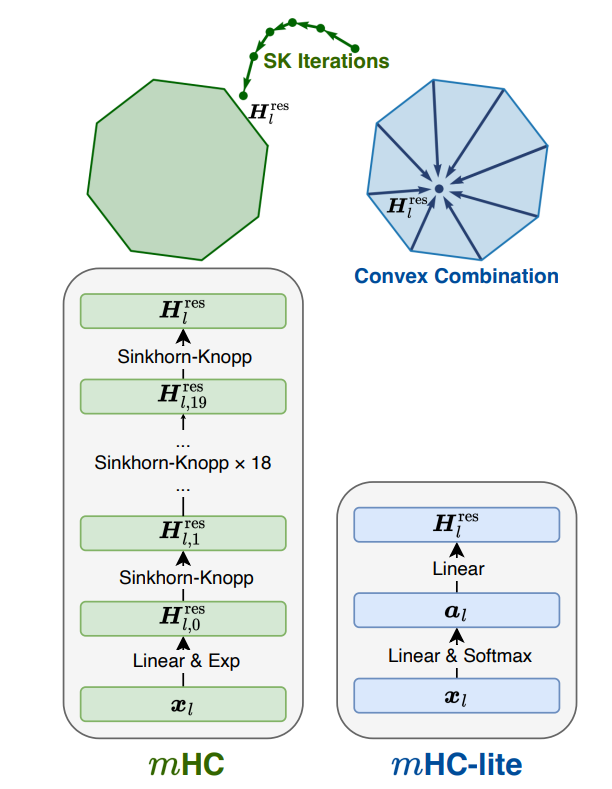
DeepSeek's recent mHC (Manifold-Constrained Hyper-Connections) proposes to stabilize residual hyper-connections via 20 Sinkhorn-Knopp (SK) iterations. However, this approach requires heavily customized CUDA kernels and, does not guarantee the quality of stabilization due to approximation errors.
Check our new paper: "mHC-lite: You Don't Need 20 Sinkhorn-Knopp Iterations". Based on the Birkhoff-von Neumann theorem, we introduce a neat solution that can be realized with standard operators while guaranteeing exact stability.
English