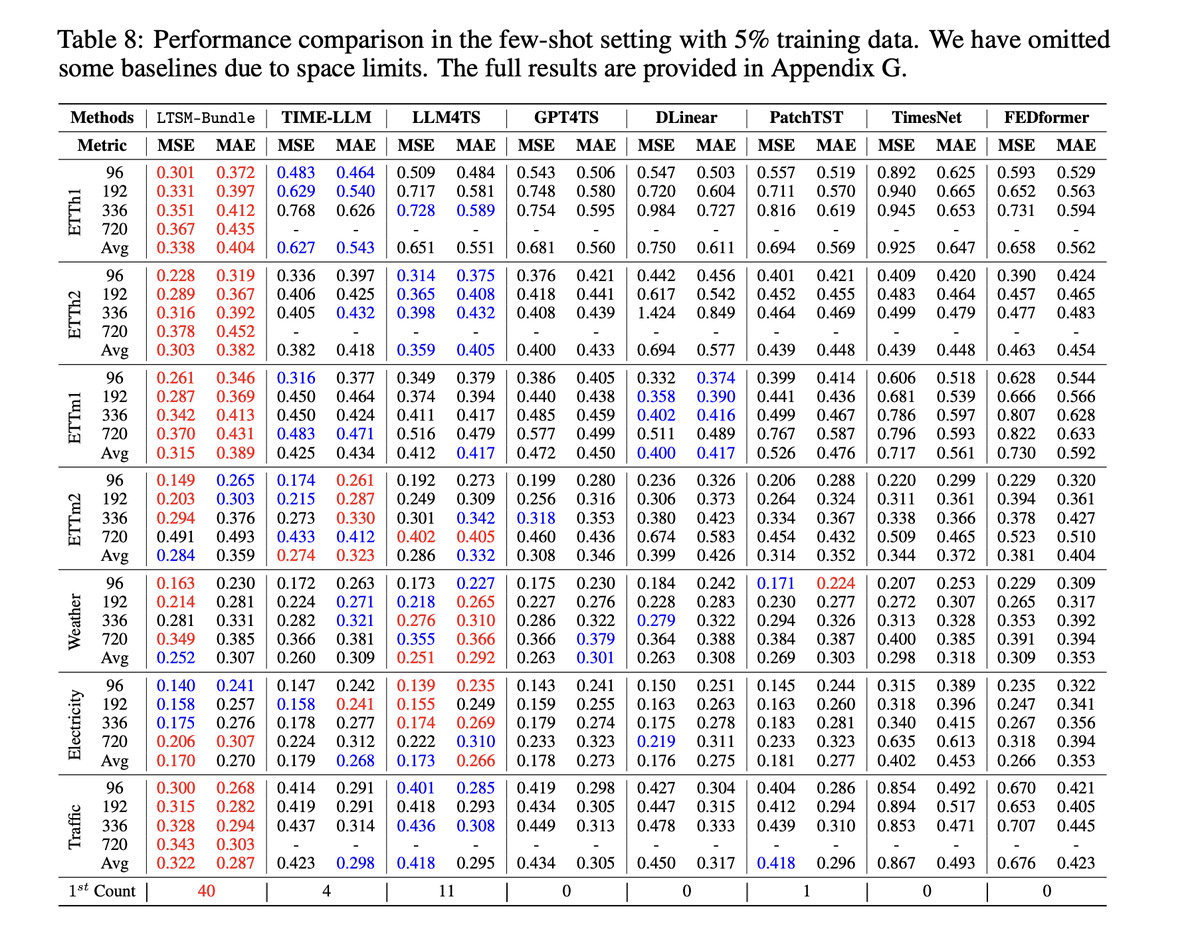
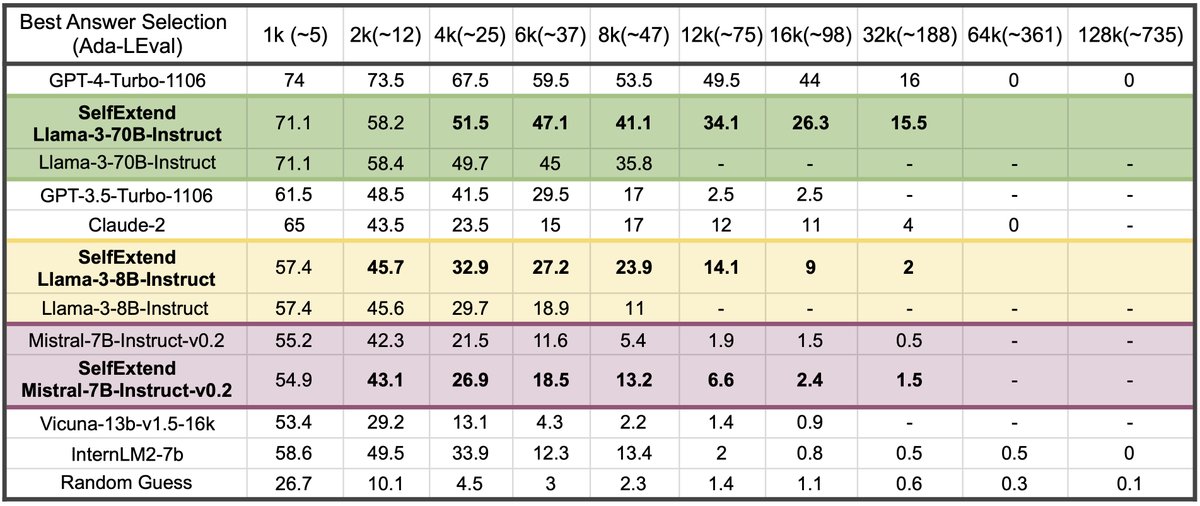
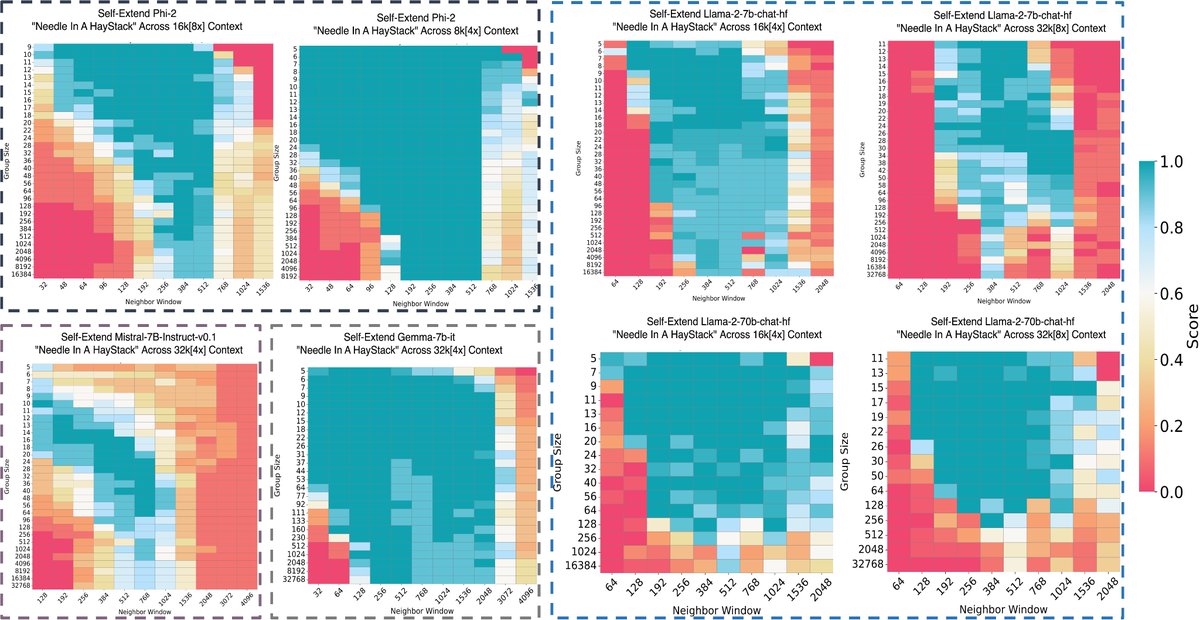
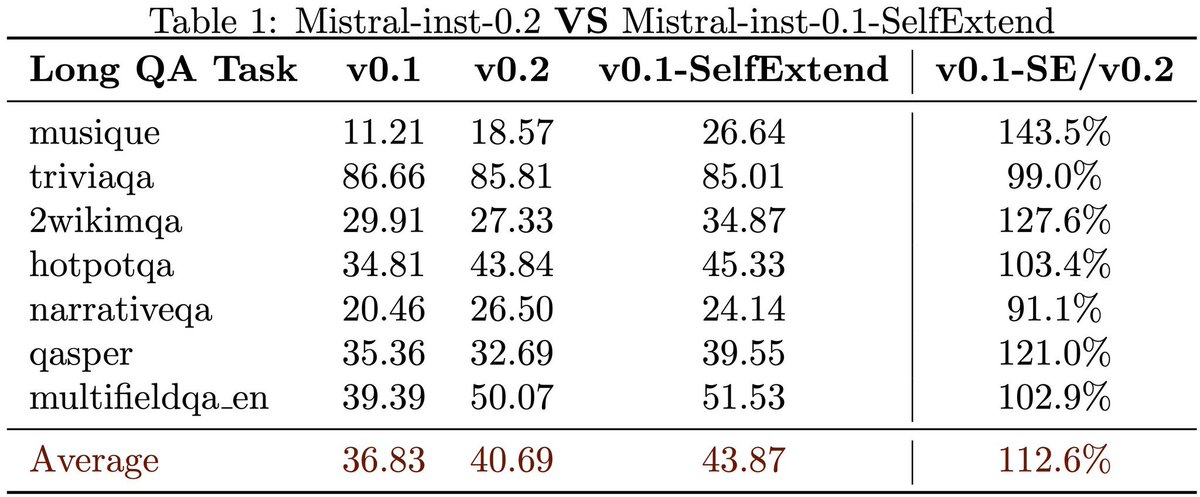
Yu-Neng Chuang retweetledi

🚀 Can LLMs stop overthinking when detailed reasoning isn't needed?
Excited to share our latest work on LLM reasoning: AutoL2S 🧠⚡
📄 Paper: arxiv.org/abs/2505.22662
🤖 Model: huggingface.co/amandaa/AutoL2…
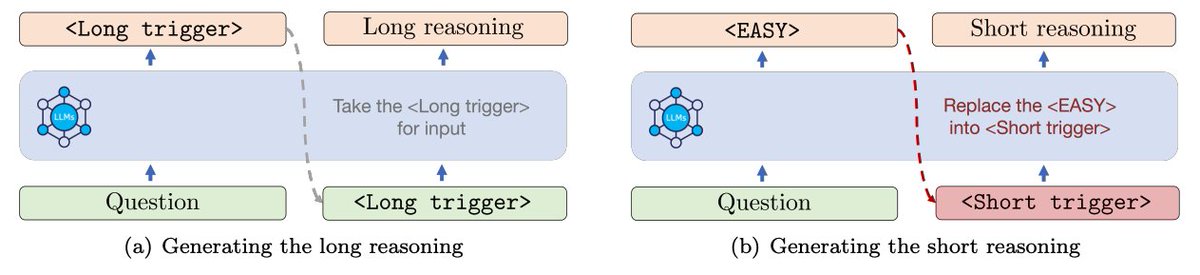
LLMs often overthink—generating unnecessarily long CoTs even for easy questions, increasing cost & latency. We propose Auto Long-Short Reasoning (AutoL2S): A model-agnostic framework that dynamically choose long or short reasoning based on question complexity.
💡 Just add a token—that's all it takes to teach the model when to skip redundant steps.
🖼️ (See below 👇) How AutoL2S switches reasoning strategies using simple markers like and →
📉 Up to 57% reduction in CoT length across four reasoning tasks without performance drop.
Credits to all co-authors: @FengLuo895614 *, @YuNengChuang*, @Guanchu_Gary, Hoang Anh Duy Le, @henryzhongsc , Hongyi Liu, @jiayiy , @YangSui, Vladimir Braverman, Vipin Chaudhary, @huxia
English