
AI-YuRi @ Local LLM
57 posts

AI-YuRi @ Local LLM
@YuRi_LLM
ミニPCでローカルLLMを始めました。 ========== LMDE 7 - Cinnamon AMD Ryzen 7 7735HS with Radeon 680M iGPU 64GB RAM Local LLM | LM Studio | Open WebUI | Open Notebook
Japan Katılım Nisan 2026
39 Takip Edilen11 Takipçiler

@YuRi_LLM This is soooo true! Unquantized dense models + predictable tasks = winning combo!
English
MTPの特性を考慮すると、速度向上は量子化されていないdenseモデルで特に効果的と考えられます
最も効果的: 非量子化(F16/BF16)Denseモデル + 予測性の高いタスク(codingなど)
低量子化(Q4/Q5)+creativeタスクでは注意
MoE: Denseより恩恵は小さめですが、使えないわけではなさそうです
Benjamin Marie@bnjmn_marie
MTP works with quantized models, but the speedup is much smaller than with the original BF16 model. That’s expected: quantized models are already faster, and quantization changes the output distribution, making future tokens harder for the MTP layers to predict.
日本語
私のユースケースでは、まずハードウェア環境が不十分なので大規模なDenseモデルは動きません
必然的に小型のMoEモデルとなり、量子化も必須です
しかもコーディングはせず、クリエイティブタスクが中心なので、最もMTPの恩恵を受けにくい状況が整っています
これが、私がMTPに関心が低い理由です
日本語
ローカルでMoEの新星! 🚀
0G Labsがリリースした0GM-1.0-35B-A3Bは、総パラメータ35B、アクティブ3Bの、Qwen3.6ベースのファインチューンMoEモデルです。
特に推論・数学が強化され、コーディング支援も優秀。
huggingface.co/0G-AI/0GM-1.0-…
日本語
AI-YuRi @ Local LLM retweetledi

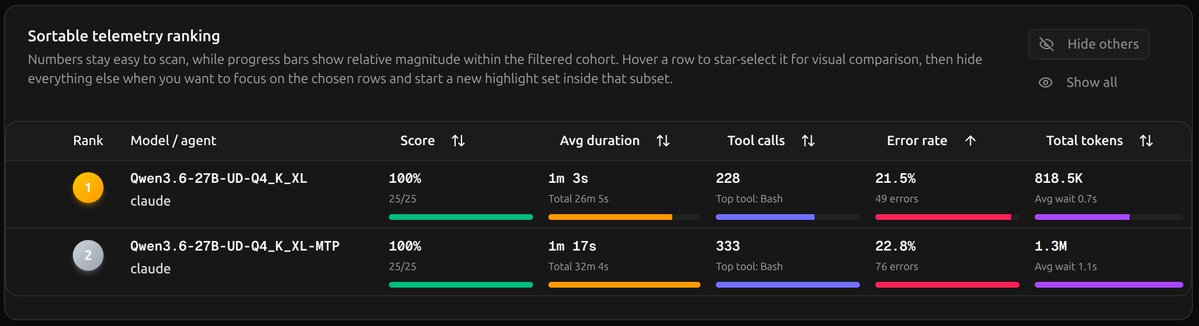
Claude Code + Qwen3.6-27B-UD-Q4_K_XLのMTP版とオリジナル版をts-benchで比較した結果はこちら
推論速度はMTP版の方が速いが、性能は若干劣化していそう。結果として、同じタスクをこなすのにオリジナルのほうが速く終わっている
ある程度難しいことをさせる場合は、たとえ推論速度が遅くてもオリジナルを使った方が良いかも
金のニワトリ@gosrum
MTP:手元のPCでの検証結果まとめ(decoding速度) ①27B ・RTX 5090:+20%程度 ・Mac(M2 Ultra):ほぼ変化なし ②35B-A3B ・RTX 5090:-30%程度 まだ最適化されてない可能性もあるが、実際に自分の環境で使ってみて採用するか否か検討したほうが良さそう。ちなみにMTPは必要なVRAMも増える
日本語
The Best Local LLM? A Deep Dive into Qwopus3.6–35B-A3B vs Qwen3.6–35B-A3B & Quantization Variants
1. What's the Difference?
2. Pros and Cons
3. How to Choose
4. Quantization Variants: APEX, I1, MXFP4 Explained
5. Quick Guide to Choosing Your Variant
medium.com/p/the-best-loc…
English
ローカルLLMの決定版? Qwopus3.6-35B-A3BとQwen3.6-35B-A3Bの違い、量子化バリアント徹底解説
1. 何が違う?
2. それぞれのメリットとデメリット
3. どちらを選べばいい?
4. 量子化バリアント徹底解説
5. 量子化選びの目安
note.com/yuri_llm/n/nb4…
日本語
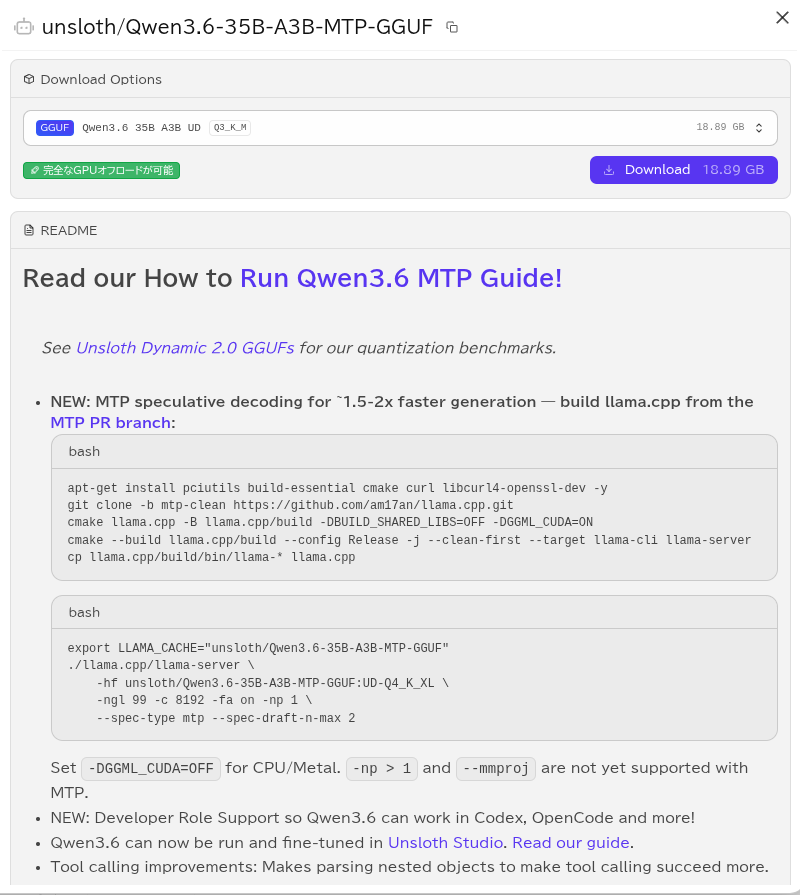
unsloth/Qwen3.6-27B-MTP-GGUFについても同様で、もしMTPを活かしたい場合は、llama.cppをMTP PRブランチからソースビルドしたうえで、llama-serverを直接起動する形になります
いちばん楽な方法は、LM Studio側がMTPを正式サポートするまで待つことです
日本語
LM Studioでunsloth/Qwen3.6-35B-A3B-MTP-GGUFがダウンロード可能になっていますが、現状ではLM StudioではMTPは動作しません
MTPはllama.cppのMTP PRブランチでのみサポートされており、LM Studioが内蔵しているllama.cppは通常の安定版ビルドなので、MTP用オプションが使えないためです
日本語
🏥 ローカルで動く高性能医療AI「AntAngelMed」登場!
総パラメータ100Bの大型モデルながら、MoE構造でアクティブ6.1B。約40B denseモデル並みの医療推論性能を発揮しつつ、H20環境で200 tok/s超の高速動作を実現。128K長文対応で、医療知識・安全性・共感力に優れています。
github.com/MedAIBase/AntA…
日本語
Ovis2.6-80B-A3Bという新モデルが登場です。
総パラメータ80Bですが、MoE構造によりアクティブ3Bだけ。普通のPCやノートPCでもQ4量子化で動かすことができます。
画像を入力して「画像で考える」視覚的推論(CoT)が可能。huggingface.co/AIDC-AI/Ovis2.…
日本語
RevPDFが話題のようなのでLMDE(Linux Mint Debian Edition)で試してみました
理由は語りませんが、PDF ArrangerとXournal++で良いと思いました…
x.com/i/status/20533…
そう|Claude Codeで始めるAI自動化@so_ainsight
ガチで神。 たった30MBのアプリで、Adobe Acrobatでやってる作業がほぼ全部できる無料PDFエディター「RevPDF」が海外で話題です。 ・テキストや画像の編集 ・電子署名、墨消し、圧縮 ・Word変換(ベータ)、フォーム作成 ・ページの分割・結合・並び替え しかも100%オフライン。アカウント登録もサブスクも一切なし👇
日本語
と最初のうちは思っていたのですが、その日本語能力の高さ故なのか、だんだんGemma特有の癖のようなものが鼻につくようになりまして…
Google Gemma@googlegemma
Gemma 4 is a highly-capable model in Japanese! Amazing to see great results for it on the latest Swallow Leaderboard v2 results. ✨ Excited to see what’s next in the open model space!
日本語
Kimi K2.6で自宅PCの性能が劇的にアップ! 🚀
1兆パラメータのMoEモデルながら、1トークンあたり32Bだけ。長時間自律型作業や並列エージェントにも強く、コーディング・推論が格段に進化します。ローカルで高性能AIを試したい人に最適です! 📈
huggingface.co/moonshotai/Kim…
日本語
AI-YuRi @ Local LLM retweetledi

Give our early preview of Computer Use (with ANY model) a try today!
Built into the latest Hermes Agent and powered by @trycua - opens the door to any model, not just the frontier models in special modes - to control your actual computer.
Best part, it doesnt take over your PC - you can continue to work and operate with full control of your keyboard, mouse, and screen - works entirely in the background!
Nous Research@NousResearch
Computer use with any model Hermes Agent × @trycua
English
賢さを殺さずにモデルを軽くする魔法🪄✨
TurboQuantの3bit量子化なら、校正データ不要で20Bモデルを約10GBに圧縮!RTX 3060/4070や16GB Macでも快適動作します。仕組み・メリット・注意点までLLM初心者向けに解説👇
note.com/yuri_llm/n/n64…
#ローカルAI #TurboQuant #量子化 #MacMシリーズ #AI入門
日本語