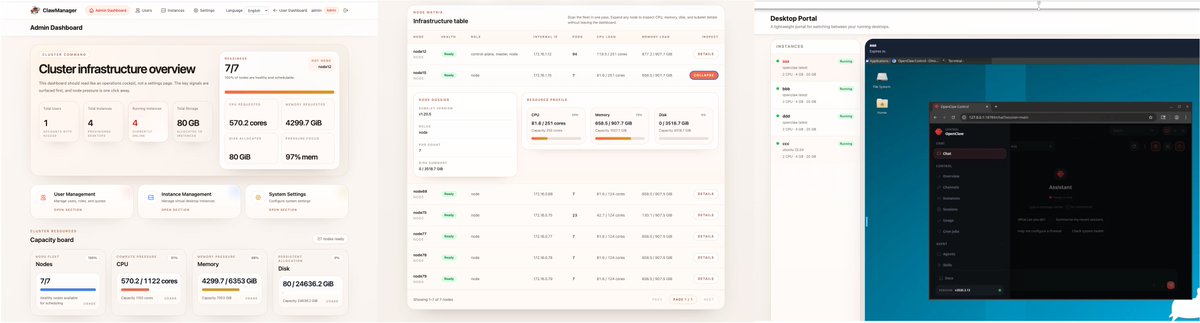
🦞 ClawManager just shipped an AI Gateway update!
🔐 Model Management — regular vs secure model tiers, per-model endpoint & pricing config
📋 Audit & Trace — every request, response, routing decision & risk hit — fully logged and traceable
💰 Cost Accounting — token usage tracked in real time, costs estimated automatically
🚦 Risk Control — auto-block or route to secure model before the request hits
🌐 15 providers supported, including:
OpenAI · Moonshot · MiniMax · DeepSeek · Ollama · OpenRouter · Local · and more
Kubernetes-native. MIT licensed. Open source.
Try it out and drop us a ⭐ if you find it useful!
🔗 github.com/Yuan-lab-LLM/C…
#OpenClaw #AIGateway #OpenSource #Kubernetes

English