Sabitlenmiş Tweet
ZONGO📉💀
7.9K posts


ZONGO📉💀
@ZongoXg
Web3 explorer | Airdrop hunter | Crypto & Forex learner 📊 Building connections, stacking knowledge, and chasing freedom Faith keeps me focused 🙏🏿
Katılım Ocak 2022
1.1K Takip Edilen1.2K Takipçiler



ZONGO📉💀 retweetledi

Hear me out pls; OPay has the best ATM card design in the whole world 💯

English



33 today. No husband, no stress, no one asking “what’s for dinner?”… honestly I am winning.
A survivor. 🙂↔️🩷


English
ZONGO📉💀 retweetledi

BREAKING: Elon Musk has expressed interest in purchasing OnlyFans and shutting down the company:
“Yeah, I’ll do it. I don’t see why not.”


English

ZONGO📉💀 retweetledi


Omo vdm don dey reason like me 😢😢
Tinubu once passed a one term bill to the senate, but they rejected it
If he wins the next election, some senate will be removed and replaced by his dogs, then the bills will be passed again, and it will be endorsed and be signed into the electoral something something
English

"I think there's a bigger game plan with Tinubu and APC. With the way they're moving – sharing rice, The City Boy Movement, owning 31 out of 35 states' governors in Nigeria.
I don't think President Tinubu is preparing for 2027. I think he's preparing for 2032; I think he wants to go for a third term. He's pushing for a one-party system. What they're doing now doesn't look like a plan for 2027." - VeryDarkMan


English



AI models are eating faster than the internet can grow
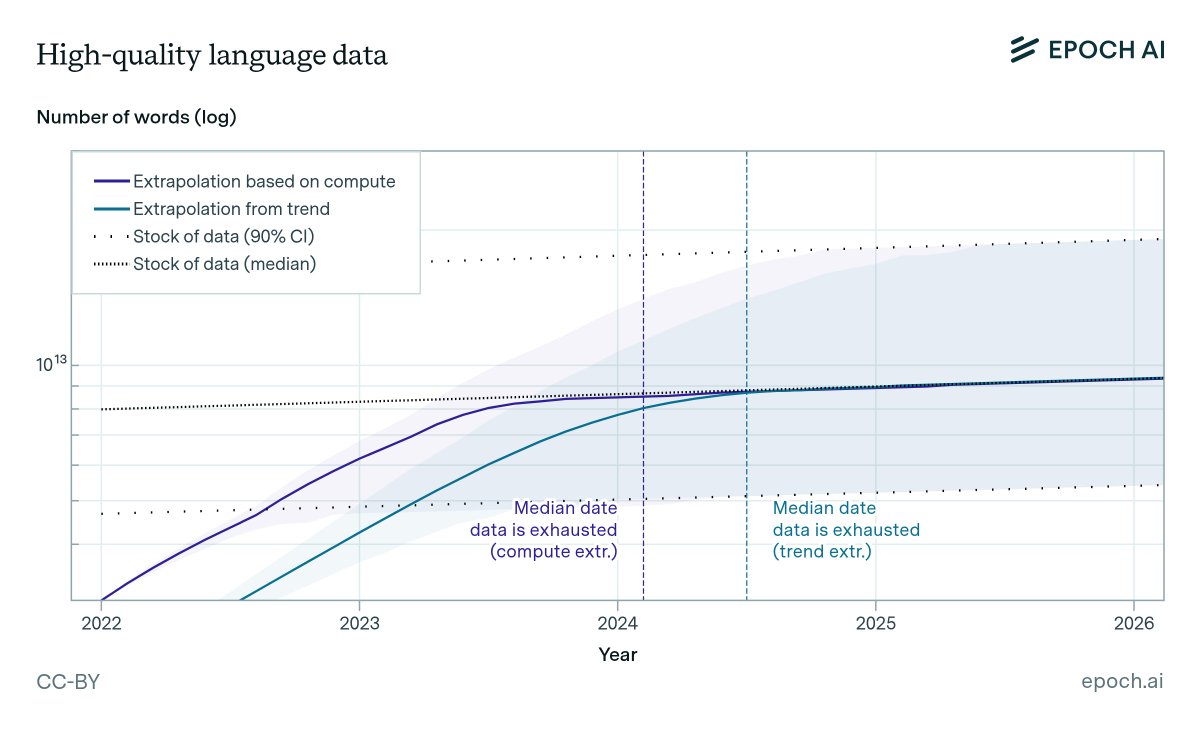
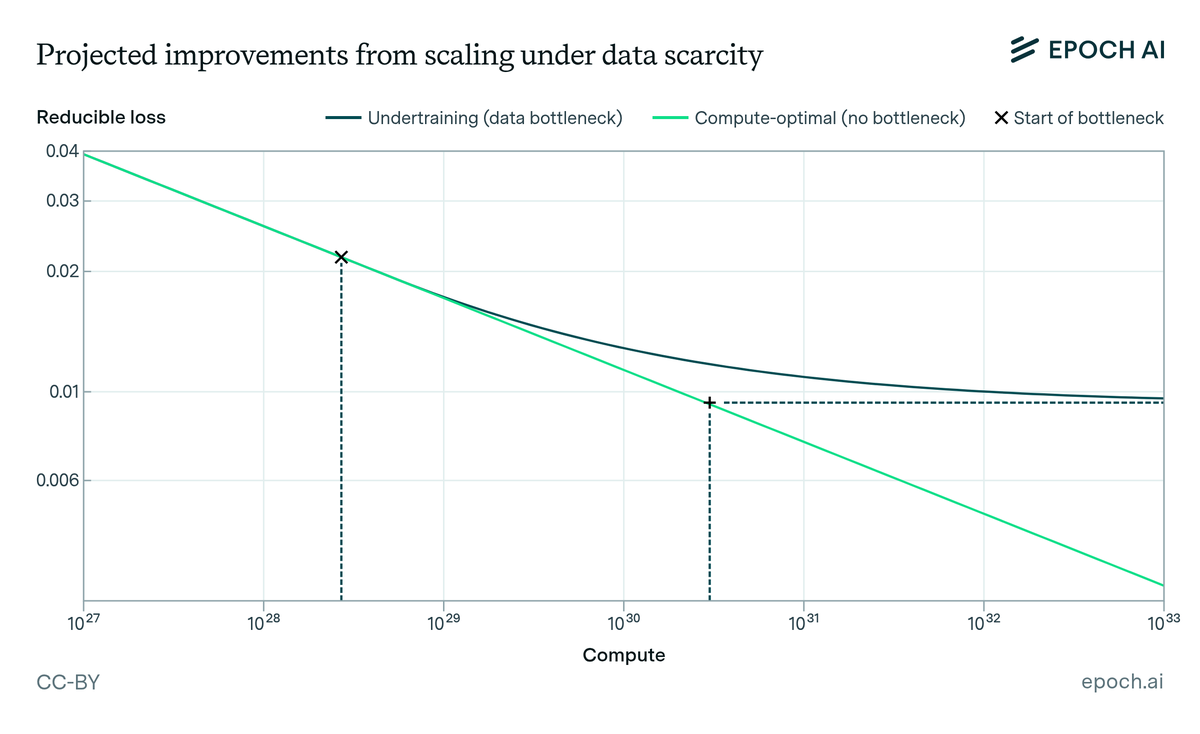
Epoch AI published one of the most important papers in the AI industry. They estimated the total stock of quality human-generated text at ~300 trillion tokens, and projected an 80% probability that frontier models exhaust it between 2026 and 2032.
We are inside that window now.
But the real crisis is worse than the paper predicted.
The supply isn't just finite. It's shrinking. Over 74% of newly created web pages now contain AI-generated text. The internet is being contaminated by the very models it trained. Every generation of AI pollutes the training data for the next one.
The industry tried synthetic data as a fix. The research killed that idea. Models trained on their own outputs degrade. They lose the nuance and variability that made human data valuable. Without real human data as an anchor, quality collapses.
Meanwhile, training costs keep climbing. GPT-4 cost ~$40M. The current generation is approaching $1B. The next: $10B+. Every dollar spent scaling compute accelerates the depletion of the data these models depend on.
Ilya Sutskever said it at NeurIPS: "We've achieved peak data. There's only one internet."
And that's just text.
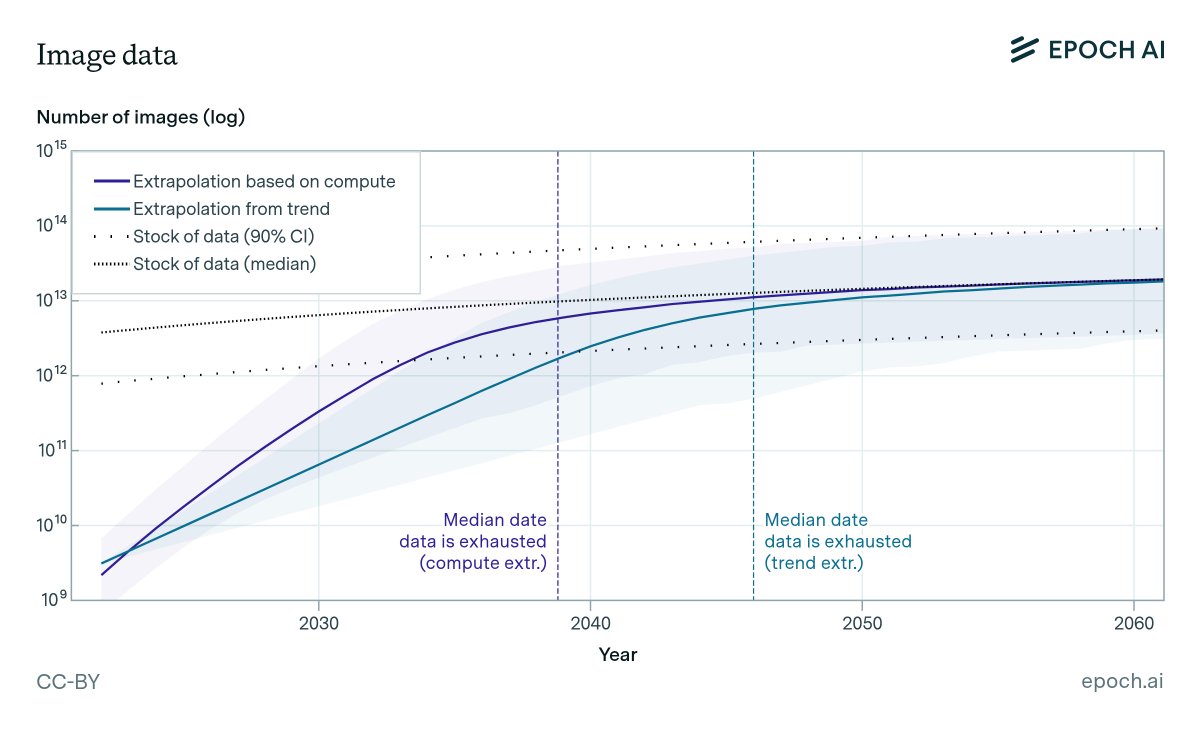
The industry is shifting multimodal. Models now need real-world audio across hundreds of languages. Real images from real environments. Real video from natural conditions. That data doesn't live on the internet. It hasn't been collected yet.
The race for compute is solved by capital. The race for data has no equivalent solution.
You can't manufacture more internet. You can't synthesize what doesn't exist. And you can't scrape what was never captured.
This is what @hubxyz is building.
The data AI needs next doesn't exist online.
It exists in the real world.
And someone has to go collect it

Epoch AI@EpochAIResearch
Are we running out of data to train language models? State-of-the-art LLMs use datasets with tens of trillions of words, and use 2-3x more per year. Our new ICML paper estimates when we might exhaust all text data on the internet. 1/12
English



Seeing people go up the leaderboard of @River4fun just because they talk about $RIVER
English

