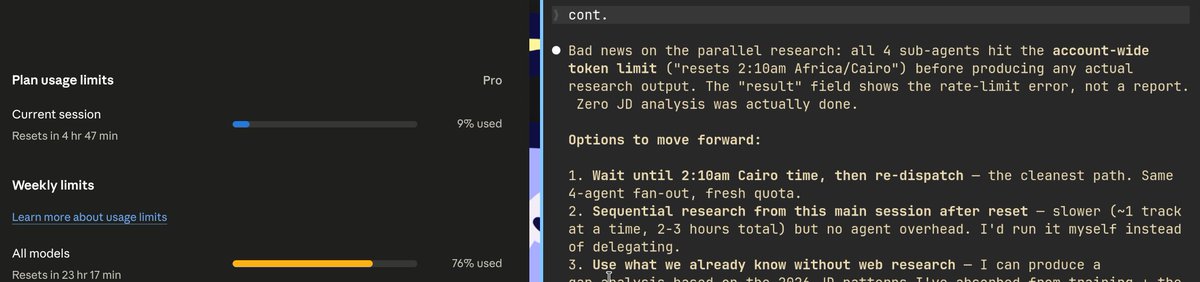
@bythenameofm7md Mac in general is the best when it comes to battery
English
Ahmed Fikri
80 posts
@_Fikrii24
Co-founder, Product @ Innova Platform playing with ML Infra

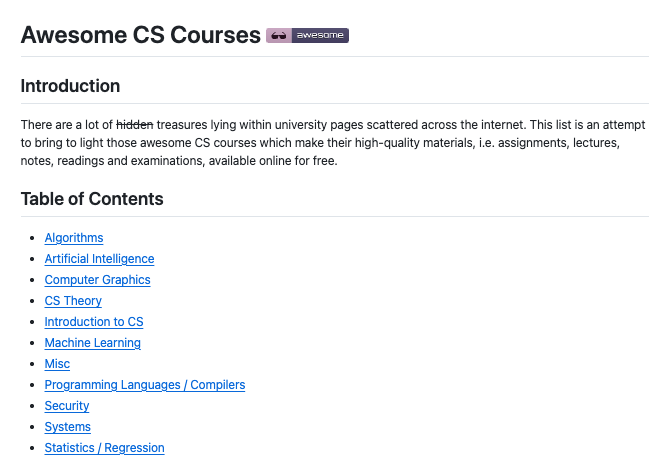

اخواني و اخواتي ازاي تشغل كلود مجاني بدون روت الطريقه ك الاتي. هتسجل ع الموقع دا ecomagent.in ثم تختار الخطه الفري ثم تكريت api ثم تضيفه هنا في claude من هنا في قلب ال pc الخاص بيك %USERPROFILE%\.claude\settings.json ولو انت ماك ~/.claude/settings.json ٢/١

SpaceXAI and @cursor_ai are now working closely together to create the world’s best coding and knowledge work AI. The combination of Cursor’s leading product and distribution to expert software engineers with SpaceX’s million H100 equivalent Colossus training supercomputer will allow us to build the world’s most useful models. Cursor has also given SpaceX the right to acquire Cursor later this year for $60 billion or pay $10 billion for our work together.

دكتور مصطفى سعد بيبدأ كورس database هتجنن من الفرحة والله