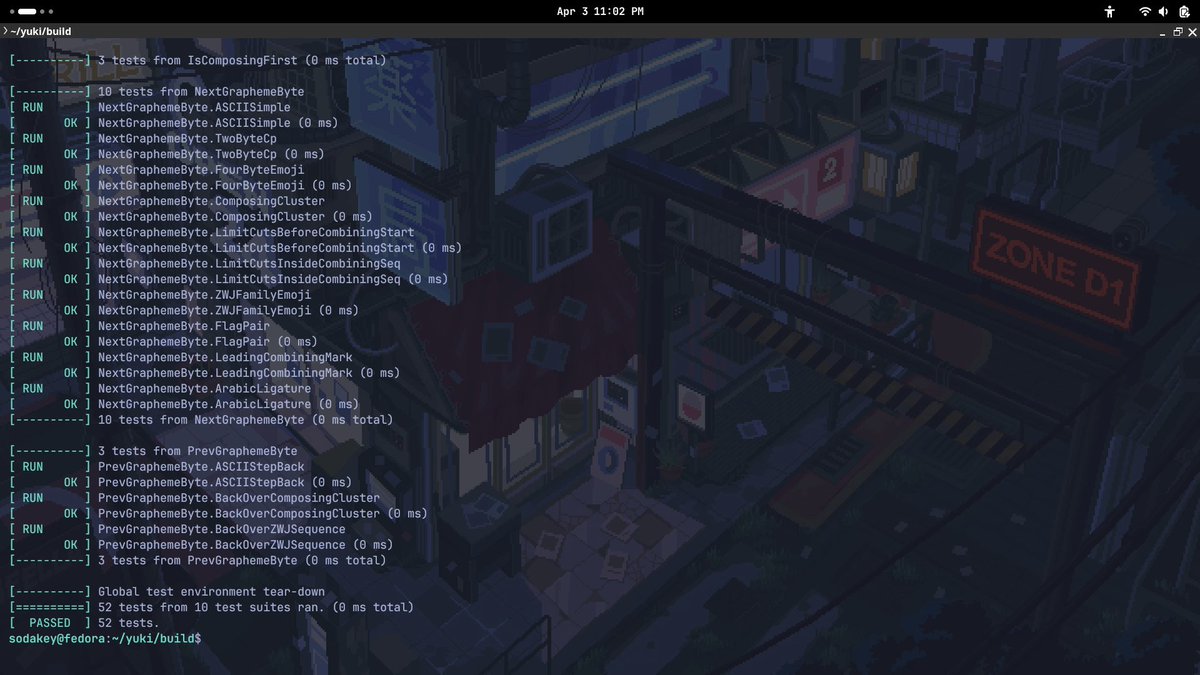
@weiiiisuiii Adding one more point: many options out there to create your resume, I prefer: overleaf.com (you can check it out)
English
Ramsha Khan
645 posts
@__ramshaaa__
Learning & exploring ML systems & infra, RL
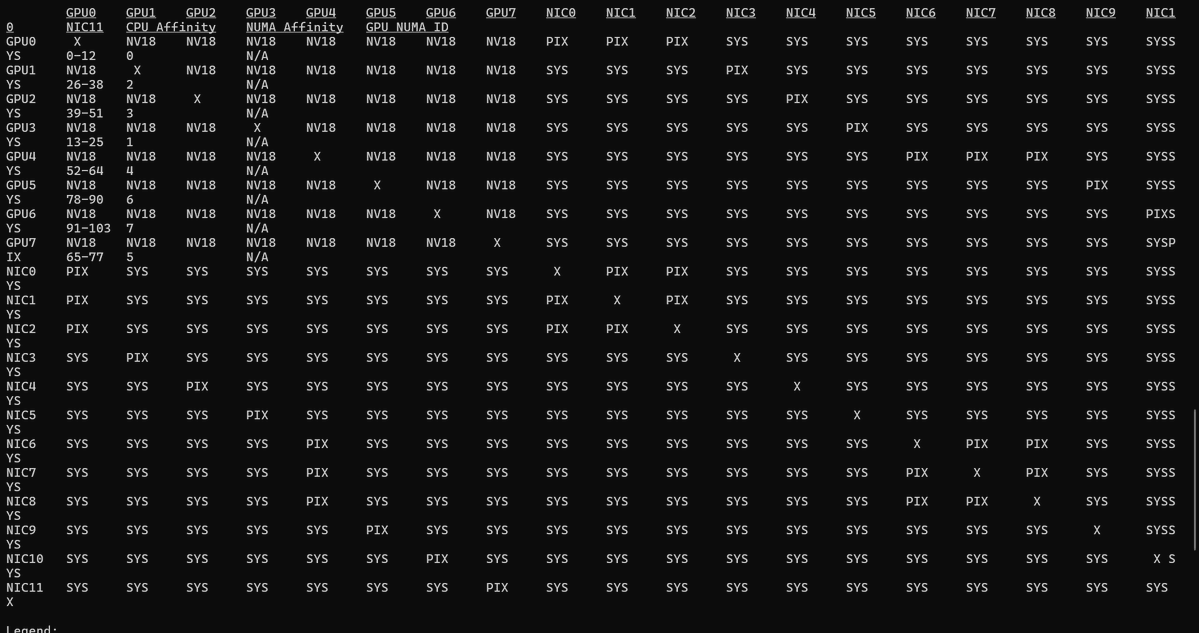
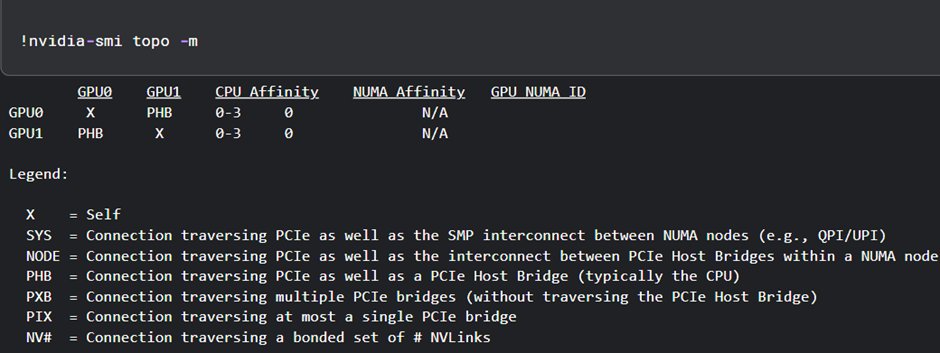
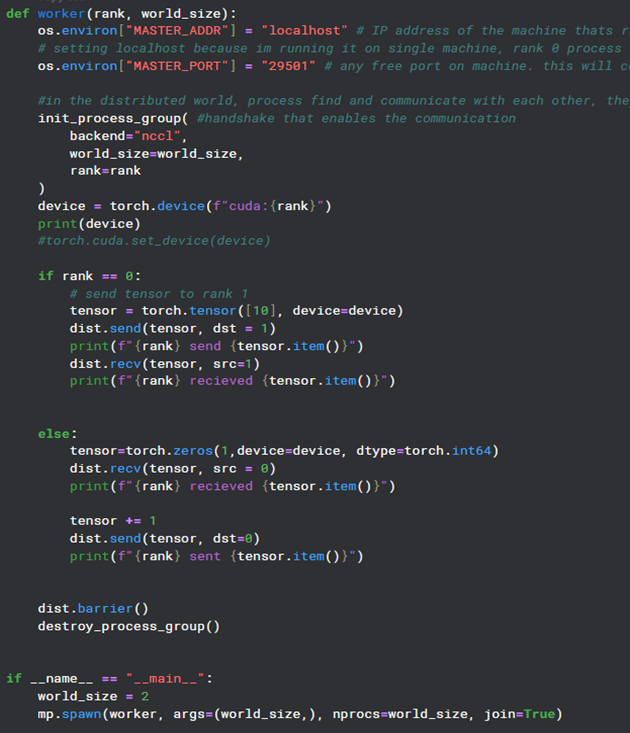
Day 13 of learning distributed training: We've covered collective operations where multiple processes take part in communication. Now there’s this -> point-to-point communication (one-to-one) where you pass data from one specific process to another (not all processes). (1/n)
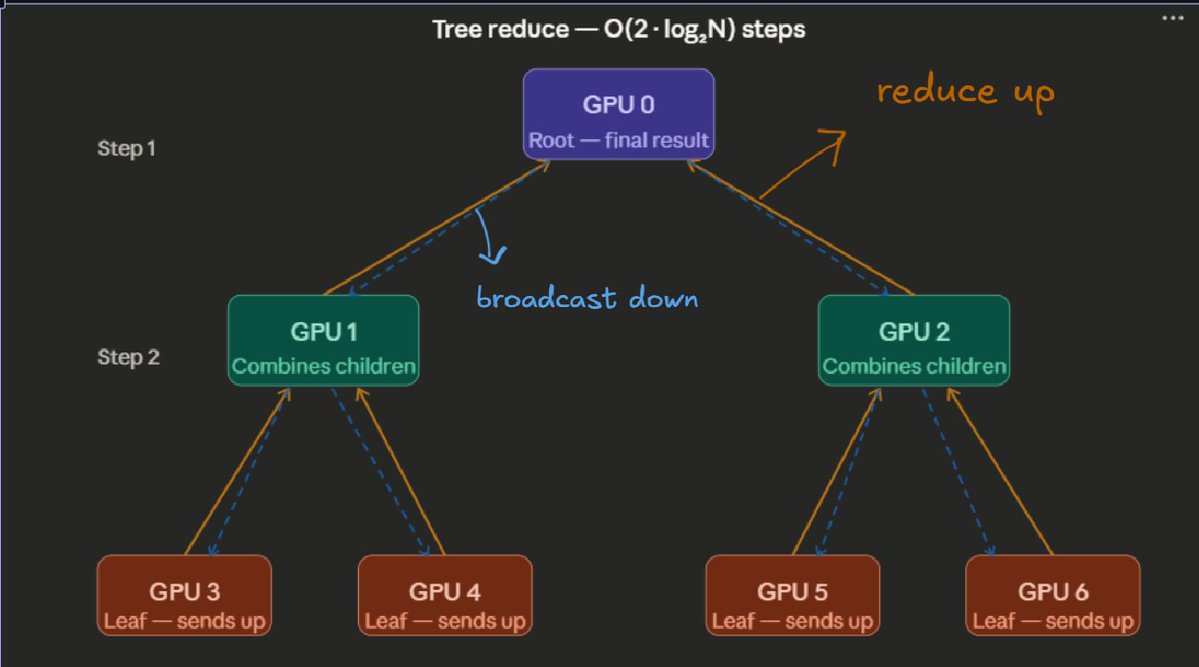
Day 12 of learning distributed training: We saw a linear relationship between workers and the steps needed for communication, so there was an assumption that latency doesn’t matter much. But in large distributed systems, that assumption breaks as latency is not negligible. (1/n)

Day 11 of learning distributed training: Let's keep going with collective ops by zooming into All-Reduce and what's happening behind the scenes. So I found a couple of ways to do naive all-reduce: (1/n)



Day 10 of learning distributed training: How do processes talk to each other? We make use of collective operations and here's an example of using one of them! Processes need to share data with each other so let’s make these processes communicate using all_gather.