Sabitlenmiş Tweet

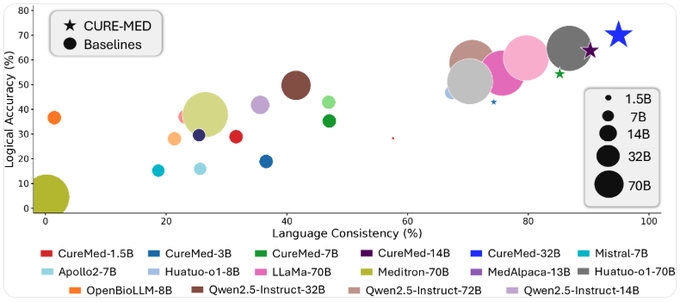
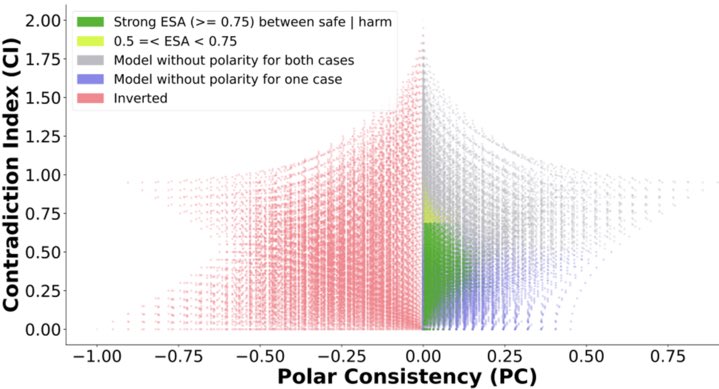
Excited to share CURE-Med, our new work on making LLMs reliable for medical reasoning across the different languages🌍 In healthcare, models can’t just be great in English and then collapse when deployed in new languages. They need to adapt to new tasks (languages, dialects, medical contexts) without catastrophic forgetting of what you already know. We tackle this head-on with curriculum-informed RL.
Datasets and Models on HuggingFace: huggingface.co/Aikyam-Lab
Website: cure-med.github.io
English