OpenMOSE
2.5K posts

OpenMOSE
@_m0se_
Rice Farmer, Fish Farmer, Welder(TIG,MIG), Electrician, Programming, Rocm RWKV is all you need. 元高専生です https://t.co/XICxvc5uor https://t.co/NShkwbjoVS
Katılım Şubat 2023
145 Takip Edilen545 Takipçiler

OpenMOSE retweetledi

LLMの長期記憶を「8×8の行列(64要素)」だけで実現するδ-memが提案された(https://arxiv[.]org/abs/2605.12357)。
通常のAttention(注意機構)は入力テキストの長さに対して計算コストが2乗で増える。会話履歴を全部渡し続ける方法はコストが爆発するだけでなく、長文の中に情報を「埋めても使いこなせない」問題も起きやすい。
δ-memのアプローチはシンプルで根本的だ。LLM本体は凍結したまま変更を加えず、外側に小さな固定サイズの行列(連想記憶状態)を持ち、過去の情報をリアルタイムで圧縮しながら蓄積。読み出し時はその内容を元のアテンション計算への「低ランク補正(元の計算に小さな修正信号を加える手法)」として注入する仕組みだ。
更新にはデルタルール学習を採用。「今持っている記憶」と「書き込みたい情報」の差分だけで行列を更新するため、固定サイズのまま効率的に新情報を取り込み続けられる。バックボーンを変更しないため、既存のどのLLMにも後付けで組み込める設計になっている。
8×8の状態だけで出した結果は、平均スコアで凍結バックボーン比1.10倍・最強ベースライン比1.15倍。記憶力重視のMemoryAgentBenchでは1.31倍、長期会話理解のLoCoMoでは1.20倍まで伸びた。
ファインチューニングなし・バックボーン交換なし・コンテキスト拡張なし。「テキストをもっと詰め込む」より「圧縮した潜在表現でアテンションを直接制御する」ほうが記憶として効く、という示唆かもしれない。

日本語
OpenMOSE retweetledi

[論文]攻撃者が一見安全なLLMをHugging-Faceなどに公開し、ユーザーが重みを低精度に変換しメモリを節約する「量子化」を適用すると悪意ある挙動が発動する攻撃手法の提案。量子化は重みを一定数ずつグループ化して処理するが、各グループに極端に大きい外れ値を1つ注入すると、同グループの他の重みがほぼゼロに丸められる。
攻撃者はこのゼロ化を「スイッチ」にして、量子化前は正常に動作し量子化後にだけ悪意ある挙動が発動する二重構造をファインチューニングで仕込む。GPTQやAWQといった実運用で広く使われる高度な量子化手法への攻撃成功は初とのこと。
【要点の整理】
・GPTQ、AWQ、HQQ、SINQなど幅広い量子化手法の多くの条件で高い攻撃成功率を記録。設計上、攻撃者はユーザーがどの手法で量子化するか事前に知る必要がない。ジェイルブレイクシナリオではフル精度版が元モデルより安全に見えるケースもあり、ユーザーを惹きつけうるとの指摘
・ジェイルブレイク(安全ガードの無効化)、過剰拒否(正常な質問まで拒否する状態)、コンテンツ注入(特定語句の出力への混入)の3シナリオで検証。Llama3.1-8B、Qwen2.5-7B、Mistral-7Bの3モデルを使用し、フル精度でのベンチマーク性能もおおむね維持
・先行研究で有効とされたガウシアンノイズ防御は本攻撃には効かず、ノイズを増やすと攻撃成功率より先にモデル性能が崩壊する。重み分布の統計的検定で攻撃レイヤーの検出は可能だが、外れ値の除去による修復は攻撃者が外れ値をさらに大きくすれば破綻するため、異常を検出したモデルは使わないことを推奨している
・ETH-Zurichの研究チーム(先行研究はNeurIPS-2024採択)によるプレプリント(arXiv、2026年5月公開)
Hugging-Faceからモデルをダウンロードしローカルで量子化するワークフロー全体に対し、モデル配布経路を通じたサプライチェーンリスクを幅広い量子化手法で実証した報告。
詳細は以下を参照:
arxiv.org/abs/2605.15152
日本語
最近、個人的にアツい"Key-Value Means" (KVM)
を日本語でまとめました。
見ていただけると嬉しいです。
zenn.dev/openmose/artic…
日本語
OpenMOSE retweetledi

Introducing KeyValueMeans
Our new AI architecture, for choosing between
- Fixed Cost Recurrent State: ie. RWKV, GDN, Mamba
- Quadratic Cost Scaling State: Attention
- & a middle ground in between...
What if Transformer attention, could expand on demand, instead of every token?

English
@sakurayukiai Research in this field is very active. KV indexers, compression, linear attention, and more. But there's no magic.. Each approach has its own trade-offs, so we're currently exploring hybrid approaches.😀
English

@_m0se_ The 98% retrieval score is cool, but the constant memory footprint is the actual unlock here. Unbounded KV cache scaling is basically the final boss of local serving right now.
English
KVM might solve everything. 🔥
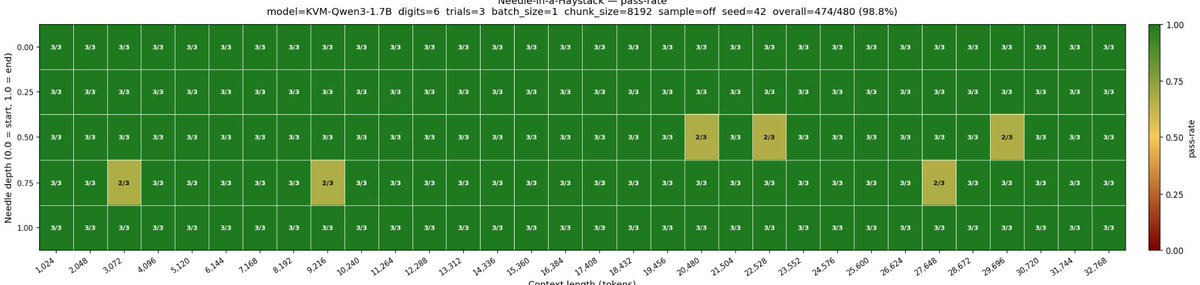
I reproduced KVM via distillation: Qwen3-1.7B → KVM with fixed-size 256-slot state.
NIAH pass-rate: 474/480 = 98.8% up to 32k context.
A Transformer compressed into a constant-memory chunked RNN — and it still nails long-context retrieval.
OpenMOSE@_m0se_
New Method "Key-Value Means" (KVM) A novel block-recurrent attention that unifies softmax attention and linear RNNs — fixed or growing state, no custom kernels, chunk-wise parallel training, subquadratic prefill. huggingface.co/papers/2605.09…
English

New Method "Key-Value Means" (KVM)
A novel block-recurrent attention that unifies softmax attention and linear RNNs — fixed or growing state, no custom kernels, chunk-wise parallel training, subquadratic prefill.
huggingface.co/papers/2605.09…
English

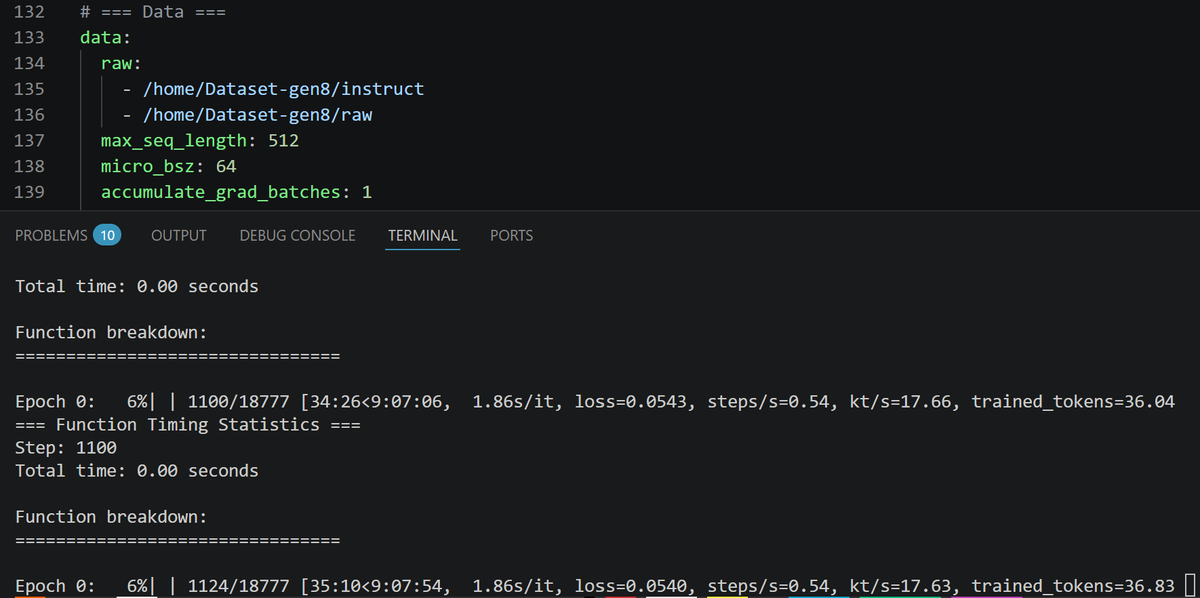
RWKV-Gemma-5B-E2B-Preview-0.1(maybe 0.0.1??)
it's "Architecture PoC" for SWA + RWKV-7 + TICA triple-hybrid on Gemma-4.
End-to-end works, Passkey holds at ~90k — that's all I'm claiming for v0.1.
Real target is the 26B MoE, back to that now.
huggingface.co/OpenMOSE/RWKV-…
English