Thanks for getting the data to the bucket now let's run analytics on it
English
OLake by Datazip
143 posts
@_olake
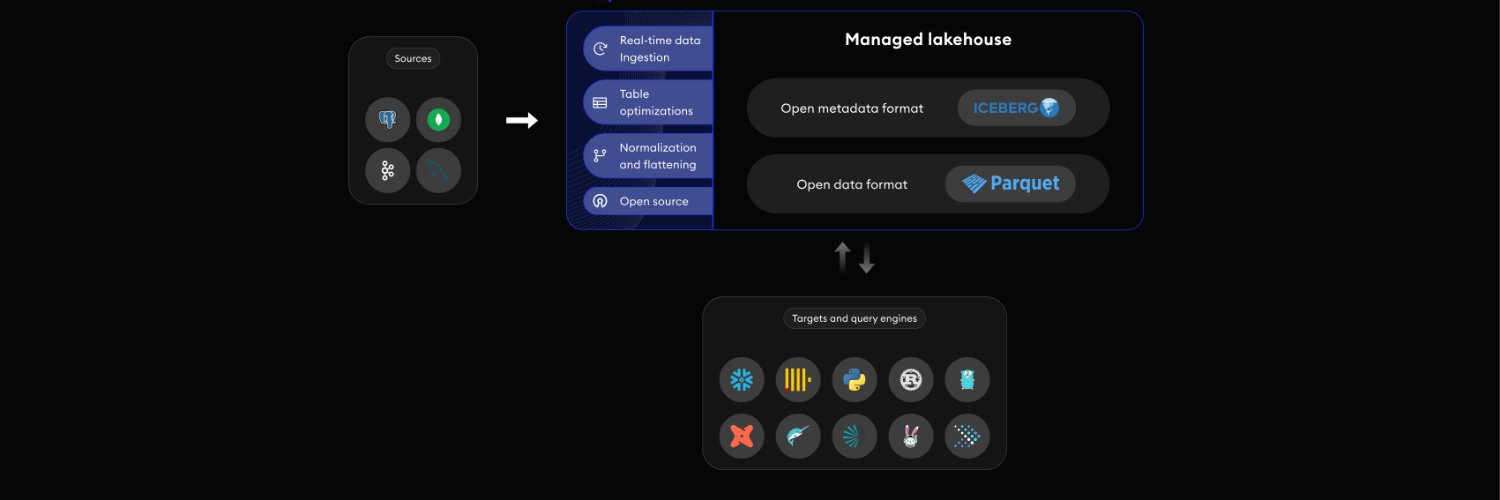
Fastest open-source tool for replicating Databases to Apache Iceberg or Data Lakehouse

I was once genuinely confused about open source. I contributed to two #GSoC organisations, spent weeks writing long proposals, and still faced rejection. Where to start? How to contribute? Is this even for me? If you’ve felt this, you’re not alone.

📍Feb 11 in SF - Lakehouse, AI & Iceberg Meetup Join @_olake, @RisingWaveLabs, @datastrato, @ryft & @dremio to explore how real-time data, AI, lakehouses & Iceberg are powering the next-gen data stack. Tech talks→ drinks→ great convos 🎟️Save your spot: luma.com/g76usnrz
This one’s going straight into my 2026 recap. I’m serving as project admin for @_olake for the second time, and this year we’ve been selected as an organization-level repository at Social Winter of Code (SWOC) 2026. If you’re registered (or planning to be maybe in #GSOC ), this is a solid chance to start contributing early. I’ve seen how consistent, quality open-source work genuinely helps when it comes to internships and early-career roles.I’ve shared a quick walkthrough video covering: How to get started with OLake How to find and choose the right issues How org-level contribution workflows actually work How to approach open source with a long-term mindset We’re also building an active Slack community (link in comments) if you want to engage beyond PRs. If you’re aiming for programs like GSoC or just want to strengthen your open-source profile, the same fundamentals apply. At OLake, we’re building a high-performance data ingestion platform and welcoming contributors who want to learn and grow. DMs are open. 2026 is shaping up to be a strong year for open source.



Preparing for Google Summer of Code (GSOC)? This is a great place to start. One thing I strongly believe in is that GSoC preparation isn’t about waiting for the program to open it’s about starting early and building real open-source contributions that actually show up on your profile as that's where the program managers shortlist your from :) At @_olake , we’ve opened up a set of open-source bounties along with good first issues, specifically designed to help you start contributing in a structured and beginner-friendly way. Here’s how you can get started: 1️⃣ Open-source bounties & good first issues We’ve curated issues that are easy to start with while still being meaningful. The bounties range from $20 to $40 and go up to $100, depending on the contribution and impact. 2️⃣ Tech stack If you’re working with Java or Golang, this can be a great starter repository to gain hands-on experience with production-grade open-source code. 3️⃣ Join our Slack All conversations, discussions, and reviews happen on our Slack. This is where you’ll interact with maintainers and other contributors and get unblocked quickly. 4️⃣ Pick an issue & start contributing Go through the open issues, find the ones that match your skill set and interests, and start working on them. There’s no pressure just steady learning and shipping. 5️⃣ Share your PR on Slack Once you’ve raised a pull request, drop it on Slack. Our developers will review your work, guide you where needed, and help you improve. At the end of the day, Olake is all about open source, collaboration, and building in the open. If GSoC is on your radar, this is a solid way to start building a real and visible contribution history. 👉 Slack link is in the comments. Start contributing #GSOC
Thanks @_olake for sending this

At our @ApacheIceberg Community Meetup in India, we had the chance to connect with some of the most active voices in the ecosystem including Pascal Schulze from @FireboltHQ . We spoke with him about two key things shaping the modern data world: • How companies are leaning into open-source technologies and why Apache Iceberg is becoming a core part of new data stacks • His takeaways from the meetup, the conversations that stood out, and what this growing community means for the future of Iceberg adoption in India More conversations and insights coming soon as we continue to build and support this community together.
Data engineering connects all parts of AI, development and software engineering — probably a data engineer One such great example was our @ApacheIceberg community meetup in India the first official one we’ve conducted. Bangalore being the heart of tech, the meetup brought together data engineers, AI engineers and builders across the ecosystem. And while the pics show it housefull, it was equally full of ideas, conversations and learning. Coffee in hand or lunch on the table everywhere you looked, something meaningful was being discussed. We also had a solid speaker lineup covering everything across the Iceberg ecosystem and how it’s evolving across real use cases. And at the end thanks a lot for joining @_olake in a successful execution. Huge shout-out to all the partners who made this possible: @awscloud @puppyquery @Minio @e6data @FireboltHQ @devrelsquad_ Missed it? 20th December keep your calendars empty.