Tarun Menta retweetledi

We shipped Chandra OCR 1.5 to the Datalab API this week!
This is a big improvement over 1.1, especially on tables, lists, charts, chemistry, and math.

English
Tarun Menta
37 posts

@_tarunmenta
Founding Research Engineer @datalabto | Ex @Adobe MDSR | @IITHyderabad `23





We shipped Chandra (our SOTA OCR model) but base latency wasn't good enough for production. So we trained an Eagle3 draft model: ✅3× lower p99 latency ✅40% higher throughput ✅zero accuracy loss Here's how we made Chandra OCR 3× faster with Eagle3 speculative decoding 🧵
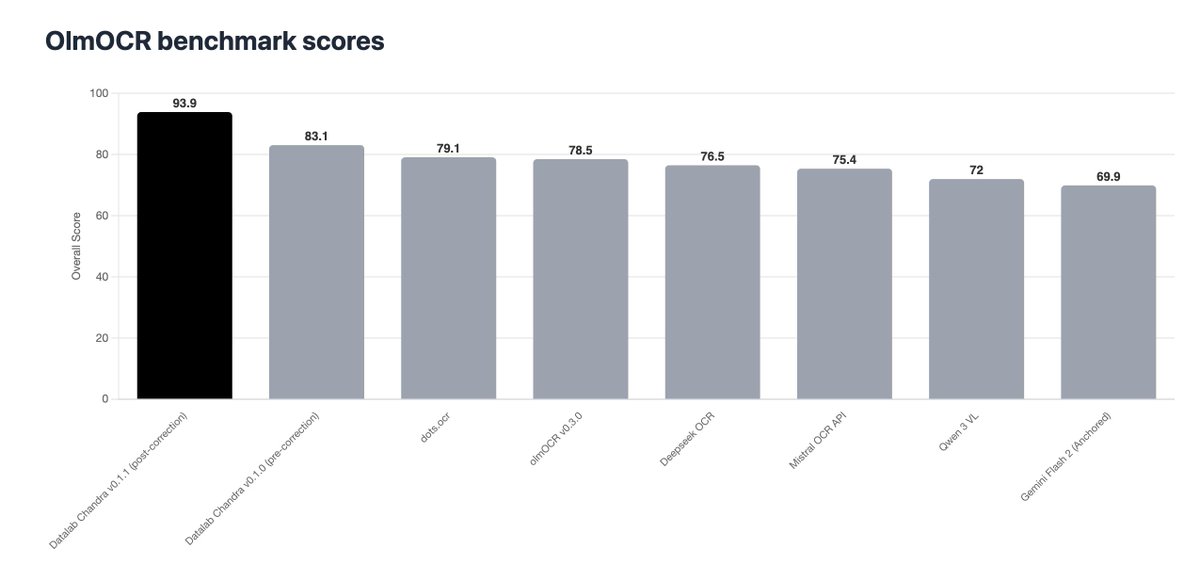



Last week we launched Chandra, the newest model in our OCR family 🚀 Despite a busy week for OCR releases, it topped independent benchmarks and received incredible community feedback.



It's officially the week of OCR! I thought to share some of the lessons learned since olmOCR v1: 1. You need a reliable way to measure your performance. v1 was done on vibes-only, but it was hard to be confident in any changes we wanted to make. olmOCR-bench was our answer.
I'm excited to announce that Chandra OCR is open source! - Full layout information - Extracts and captions images and diagrams - Strong handwriting, form, table support - Works with transformers and vLLM



Launch Day 3 of 6: Layout Model Updates 🚀 If your doc parser gets layout wrong, everything downstream breaks. ⚠️ Reading order scrambled → unusable output ⚠️ Blocks missed → footnotes, financial figures, legal text lost We just rolled out major layout upgrades at Datalab to fix this at the root.
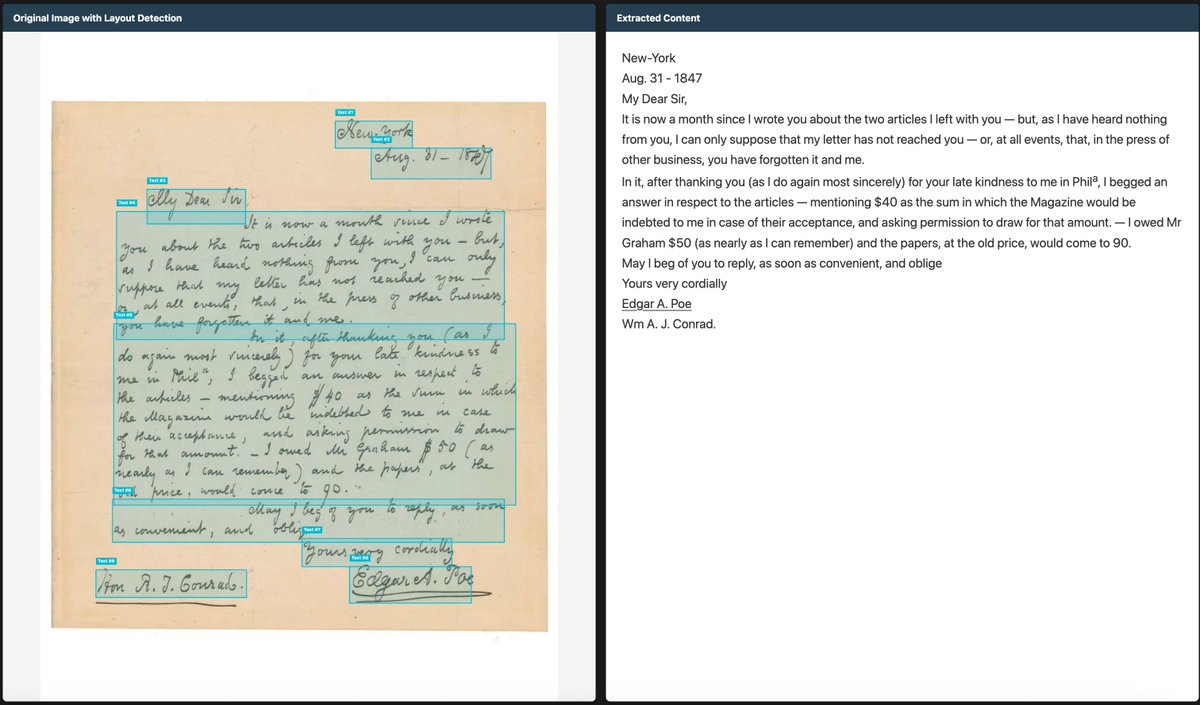
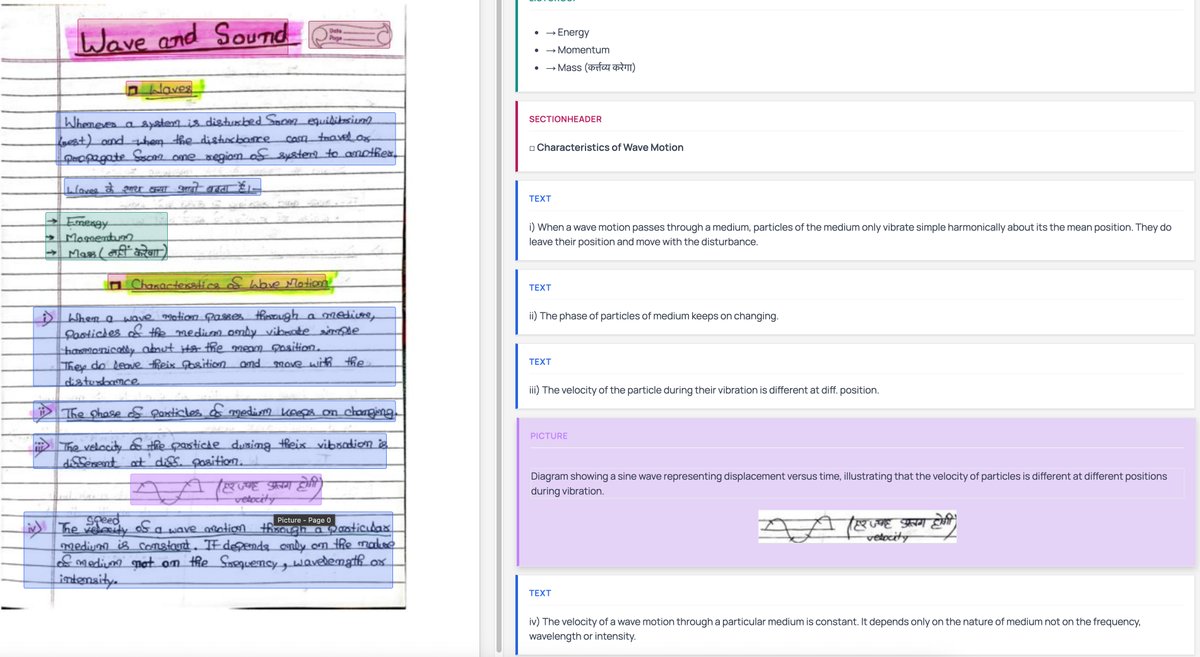
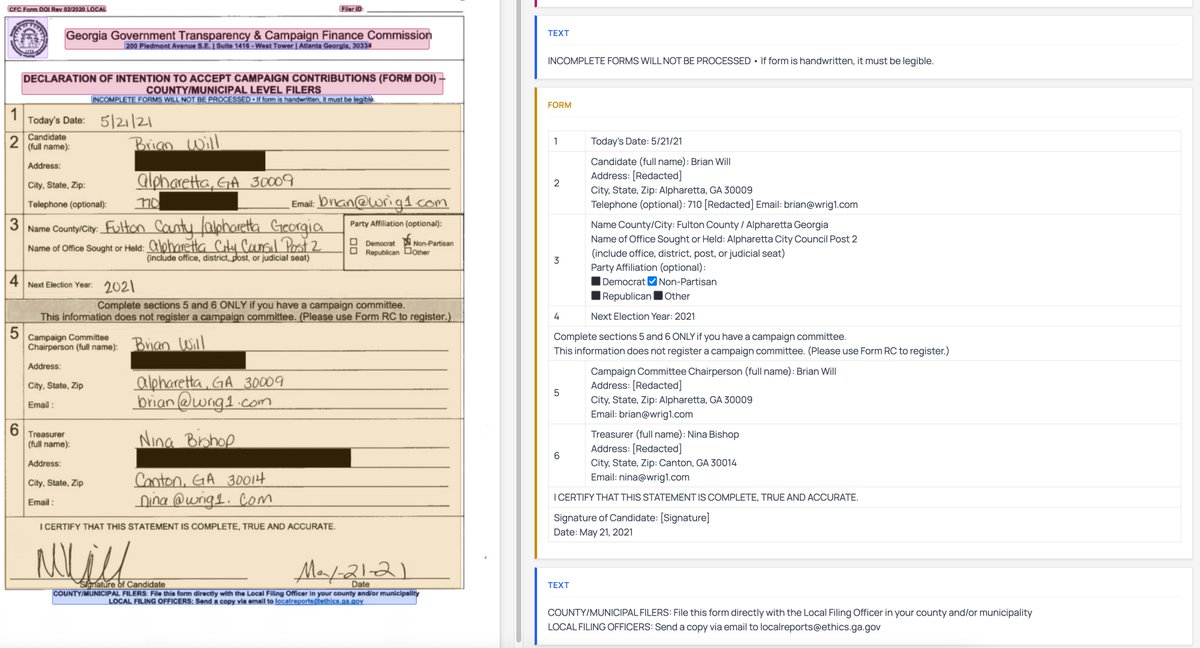
This is from a model I'm training - it's significantly better at reading handwriting than me, so I can't tell if it's correct or not...
This is from a model I'm training - it's significantly better at reading handwriting than me, so I can't tell if it's correct or not...
Launch Day 3 of 6: Layout Model Updates 🚀 If your doc parser gets layout wrong, everything downstream breaks. ⚠️ Reading order scrambled → unusable output ⚠️ Blocks missed → footnotes, financial figures, legal text lost We just rolled out major layout upgrades at Datalab to fix this at the root.