吉光片羽@_withthewind_·8h@CanXuchangsha @naokiaoki7 @zmt021 蠢东西@CanXuchangsha破防一顿狂喷,还跑到我别的帖子里喷简中大粪,口口声声要对线然后把我拉黑🤣气急败坏跳脚冒烟的样子真的太典了,标准粉蛆。笑死我了哈哈哈哈,我就喜欢看这种无能狂怒身心受挫的样子。🤣Çevir 中文00010
吉光片羽@_withthewind_·1d@CanXuchangsha @naokiaoki7 @zmt021 不会AI,我来教你。顺便再问你一句:2014年以前,中国国内,有一个拿的出来的新能源车没有?有吗有吗有吗?哈哈哈哈。笑看打脸!x.com/i/grok/share/7…Çevir 中文30047
吉光片羽@_withthewind_·17h@thinkszyg @fi56622380 且听龙吟800回😅我不懂水上水下,但我懂华为。从5G,到光刻机,到今天的折叠,哪次不是“国家意志”背书?每次都是做出5分成绩,让宣传机器硬吹出10分效果。演多了,就滥了。现在就是个2.0版本的苏联,做的事,基本换汤不换药。这些故弄玄虚的国家意志,最终归宿还是历史垃圾堆。Çevir 中文100118
爆裂队长NEXT@thinkszyg·22h@fi56622380 你们啊,分析来分析去,还是格局不够,给你看的都是你能看的,还有水面下的,那还没放出来。你不可不必担心10年后华为怎么样,这是国家意志,不是华为单方面的事。Çevir 中文2052.2K
fin@fi56622380·1d华为τ scaling定律营销策略,无非是more than moore的广义摩尔定律的另一种说法而已 作为芯片架构师,我更感兴趣的,还是芯片密度提升,ppt上41%能耗提升和12.7%性能提升,到底是怎么实现的 看完了论文,感觉华为这次创新,本质上是用设计复杂度高 + 高制造成本 + 超前散热,一定程度弥补了工艺差距 ----------------- 1. 华为芯片堆叠带来的等效密度提升,是虚假宣传还是真的,是不是工艺突破?有没有实打实的好处? 等效密度提升的来源,是两片芯片用hybrid bonding技术绑在一起,投影面积理论上能减小一半,但第一代不是全芯片双层折叠,而是选择性折叠关键logic,所以只有大概53%的芯片面积实现了折叠(密度155->238),等到后面几代折叠面积会逐渐增大,到2030年接近全折叠(密度155->292) 这2026第一代等效密度从 2025 年 155 MTr/mm² 跳到 2026 年 238 MTr/mm²,时钟频率也提升了12.7%,功耗比提升41%,表面上看似乎和工艺突破没有什么区别,但有一点重要区别就是leakage power华为从头到尾没有提,只要工艺节点不变,gate leakage、junction leakage 不会因为 3D stacking 自动改善 2030年到2031年的等效密度突变,大概率是来自于2层堆叠到3层堆叠,正如2025到2026年的等效密度突变,时钟频率突变,来自单层到2层折叠 所以从leakage没提这个事来看,这个2031年等效1.4nm,和工艺节点上的突破没有联系。 本质上是用设计复杂度高 + 高成本 + 超前散热 + 超前部署advanced packaging,一定程度弥补了工艺差距 ----------- 那么这样看起来虚假的等效密度提升,有用处吗?好处在哪里? 有的,设计上topology折叠,原来要跑几毫米的水平走线,折叠后变成了几十微米。降低了super buffer/bus的长度,降低了clock tree的深度(clock depth -42%、clock wire -28%),clock skew也带来了改良(-25%),这对动态功耗的改善是实实在在的。部分critical path的缩短,也让时钟频率的上升更容易 所以ppt roadmap上performance的提升,从2025年到2026年上升了12.7%,大部分都是来自于时钟频率的上升(12.7%) 所以好处基本上是topology拆分电路逻辑设计上带来的提升 既然没有实质上的工艺提升,华为芯片堆叠带来等效密度提升的trade off代价在哪里? 三个代价:散热超前发展,设计复杂度高,制造成本变高 最大的代价就是热密度的同步上升,理论上logic on logic都是CPU execution发热最严重的区域,这部分折叠起来相当于功耗密度直接翻倍,但算上41% power efficiency改善,功耗密度仍只比非堆叠方案高40%左右。所以第一代只能对最关键的部分做折叠,大概只占全芯片面积的53%。 所以散热技术也被逼的超前发展,直接上毫米级的MEMS风扇,做micro-cooling fan。 另外的代价就是设计复杂度的变高,critical path的折叠,哪个部分的logic能折叠,折叠之后又会带来从前端到后端的巨大变化要推翻重来 现有的所有EDA工具也不可能支持3D topology,论文自己也承认,full-scale LogicFolding需要全新的3D-native EDA toolchain,把多层stacked dies当作单一连续设计实体处理。哪些logic能折叠、折叠后的inter-die timing closure怎么做,Physical Design(PD)也是难点 制造成本也会更高,被迫超前部署advanced packaging封装,1.5~2um的hybrid bonding + logic on logic都是很有挑战需要显著更高的成本 以前一层wafer做一次光刻;现在两层wafer分别做光刻再bonding,加上hybrid bonding的overlay控制(论文要求<0.5μm)、TSV、KOZ keep-out zone、冗余修复、良率乘法损失,每颗芯片的制造成本和测试成本都要显著上升 -------------------------- 2. Tau scaling这个说法,scaling的到底是什么,这个scaling技术路线是不是一次性的design topology红利?潜力如何?持续进步的空间在哪里? τ Scaling的核心主张是:用时间常数τ替代几何线宽作为全栈优化目标,在器件、电路、芯片、系统四个层级分别压缩特征延迟 公式本身没有任何新物理。"关注瓶颈延迟"是所有架构师都在做的事情。整个行业都知道互联RC是延迟瓶颈,TSMC每一代工艺都在用low-k dielectrics/semi-damascene等手段降RC。把一个众所周知的优化方向包装成"定律"是显然的营销宣传手段,本质是More than Moore的广义摩尔定律的另一种说法 抛开marketing,华为目前所谓RC delay的改善,本质上是芯片堆叠之后,topology距离缩短,让匹配的effective RC都变小,不是RC工艺常数 至于scaling的意思,是能持续发展的一条roadmap。这里的持续改善路径指的是,全芯片堆叠的层数越来越多,从25~30年的2层堆叠,到31年开始的3层堆叠,以后甚至会考虑4层堆叠 第一代折叠技术甚至不是全芯片双层折叠,而是选择性折叠关键logic,所以只有大概53%的芯片面积实现了折叠(密度155->238),等到后面几代折叠面积会逐渐增大,到2030年接近全折叠(密度155->292)。2031年的roadmap之所以会出现一个阶跃,就是因为那是从2层折叠到3层折叠的时间点。 但需要注意的是,这个scaling方法的边际效应是逐渐缩小的,折叠成双层的收益是100%,2->3层的收益就只有50%,如果2035年再从3->4层堆叠,收益就只有33%了 另外随着堆叠层数变高,上面说到的三个挑战,散热,设计复杂度,成本,都是越来越大 --------------------- 3. 华为的芯片堆叠,是不是TSMC/AMD已经有的hybrid bonding技术?华为做到的是cache on logic,cache on cache,还是logic on logic,logic on logic最大的散热问题是怎么解决的? 是已经有的技术没错,但同时也是把现有技术指标做到了领先也是真的,3D堆叠本身不是新技术,TSMC的hybrid bonding量产还是6um,华为论文给出Kirin 2026的hybrid bonding pitch是1.5μm 我在刚刚看到华为的堆叠消息之后,第一反应也是怀疑和AMD的3D V cache类似,它主要把 SRAM cache 叠在 已经有的L3 cache 区域上,通常会避免直接堆在最热的 CPU execution logic 上,就是避免散热问题,毕竟SRAM 的功耗密度和热点特性与high-activity logic 不一样,如果最热的logic on logic堆叠,散热恐怕会碰到困难 但看了更多数据之后,clock buffer -56%、clock depth -42%、clock wire -28%,这些只有在core内部的clock distribution被重构时才可能发生。纯SRAM stacking不会碰core内部的clock tree。另外如果只是cache on cache,大概率是不需要单独MEMS微型风扇额外散热的,证据普遍都指向logic on logic方式 华为这个技术的精妙之处在于,logic on logic 折叠之后热密度并没有翻倍,而是因为topology的好处,能耗下降了30%,这样热密度只上升了40~50% 而第一代没有完全把整个最热的execution logic 100%堆叠起来,论文也明确说selectively applied along key critical paths,只是大概53%有选择性关键路径会堆叠起来,可能颗粒度都没有那么好,只是IP堆叠在IP上,那么热密度上升也许能维持在20%以内 但这条道路继续前行,超前发展的散热就成了必然,现在是MEMS微型毫米级的主动散热风扇,紧贴处理器传导效率高,和华为手机一样,散热堆料特别足,而且技术领先同行。 以后怕是要把HBM7/8的微流道散热技术提前用起来了,毕竟HBM7/8要上24+层堆叠,华为很可能要在提前用上下个世代的散热技术了 ------------------------- 4. 从架构角度来说,最重要的问题,华为41%的power efficiency(能耗比)提升,到底是怎么实现的?为什么AMD的3D V cache没有这么大的提升? 首先确定41%的定义。论文只说"SoC performance-core power efficiency improved by 41%",没有给出benchmark名称、Voltage/Freq点、温度条件、功耗边界。但PPT roadmap上有一个关键线索:ISO-Power Performance的数字,2025年是2.75,2026年是3.1,提升12.7% 这个时钟频率提升12.7%完全一致,可以理解为,同功耗的性能提升是12.7%,绝大部分是时钟频率提升带来的 至于能耗比上优化的猜测是,LogicFolding缩短critical path → 在固定Vdd下Fmax从2.75GHz提升到3.1GHz → 这意味着在原来的2.75GHz频率下,有了约12.7%的timing headroom → 这个空间在iso-performance模式下可以换成更低的Vdd 另外的能耗比的提升,可能也来自于电路折叠之后,cache hit latency的下降。从业界经验来看,一般L2/L3 cache hit latency下降10%,CPU整体性能会有至少5%的提升 ppt里显示SRAM latency下降30%,估计会有一部分转化为cache hit latency的下降 AMD的3D V cache没有这么大的提升,主要是因为AMD的底层logic die并没有重新设计,3D cache的延迟latency不仅没有减小反而加大,只是增加了cache大小,收益不如latency下降那么明显。 另一方面,clock skew的下降,critical路径变短,造成电路timing变好,意味着华为可以使用更低的vdd(猜测甚至能低7~8%),以及路径缩短所带来的RC的下降(考虑到clock buffer -56%、wire -28%、SRAM pJ/bit -24%这些数字,比如C_eff下降10~15%合理),再加上clock tree的整体缩短和下降,确实是有可能在部分Voltage/Freq点做到同性能下,做到30%的功耗下降的,而30%的功耗下降换算过来就是41%的power efficiency 对比苹果和高通,每一代手机芯片在iso-power下单核性能一般提升10-20%,iso-performance下功耗一般降30-40%,这是V/F曲线的特性决定的,所以从经验上来说,数字是对的上的。 所以这个power efficiency(能耗比)的提升,从现有的数字上来说可以从topology推导出来是合理的,可能真的和工艺节点没有太大关系 ---------------------------- 5. 这个技术路线有没有可复制性,其他家会不会效仿? 短期内不会大规模效仿,因为性价比和风险收益比来说不好。长期来看,这个方向所有人都在走,只是名字不一样 华为做LogicFolding的根本驱动力是制裁,工艺节点被卡在7nm,只能在封装,散热,和设计层面想办法弥补。华为也为此付出了不小的代价:散热成本,设计复杂度,以及制造成本更高(包括良率)。这是一个被逼出来的路线,不是一个自然选择 其他玩家在用TSMC就能做到正常的经济迭代,是没有必要冒着这个风险,去超前迭代散热技术和设计复杂度的 长期来看,Intel的Foveros、TSMC的SoIC、AMD的MI300的3D stacking都在朝同一个方向走。如果继续追最先进节点的经济性持续恶化,那么"固定一个成熟节点+3D topology optimization"的路线会越来越有吸引力 散热方面,MEMS微型风扇和微流道也会成为未来HBM散热的主流 ------------------- 总结一下,华为这次的创新,绝对是值得尊重的,在制裁环境下,用极高的设计复杂度和成本,在一个被锁定的工艺节点上大胆重新设计,榨出了一次大的topology红利,虽然它有天花板。每多加一层的边际收益递减(堆叠1->2层, 2->3层, 3->4层,提升百分比变小),leakage无法解决,散热越来越难,3D EDA工具链更是全新的挑战。 但这个Tau scaling不是一条可以走十年的指数增长路径,每次爬完一个台阶,下一个台阶更难爬,而且台阶更矮收益更小,华为以后想缩小差距,还得再想想靠什么其他的路线Çevir 中文1694731.7K587.7K1.5K
吉光片羽@_withthewind_·1d@XiaoFei6774 @naokiaoki7 @zmt021 @grok 哎哟,现在不跟我掰扯特斯拉有没有开源技术了?哈哈哈。蠢货,马斯克开源之前,你这遍地新能源车几乎全是骗补的,一开源就“新势力”“弯道超车”。什么叫不要脸,你这就叫。别人说实话就是给洋爹撑门面,你这种心态不用问AI我都一清二楚:敏感自卑、猥琐下作。Çevir 中文201245
苏小费@XiaoFei6774·1d@_withthewind_ @naokiaoki7 @zmt021 @grok 早期特斯拉开源的一百多个专利对电动车行业推动有巨大的作用,电动若中国不接,它也发展不起来,后期比亚迪更是开源上千条专利对电动车普及更是重大的贡献,你这种人那嘴脸你自己扪心问自己不丑陋吗?你说你是美国人也罢了,你一个亚洲人天天给洋爹撑什么门面?你要不问一下ai你是什么心态?Çevir 中文100223
吉光片羽@_withthewind_·1d@RennickWater @naokiaoki7 @zmt021 就是,时间一长,牛顿都能抄永乐大典,何况马圣。反正十几年过去了,虽然互联网有记忆,但那时候我在小学抠鼻屎我不记得,所以就不存在。😀Çevir 中文000174
rennick water@RennickWater·1d@_withthewind_ @naokiaoki7 @zmt021 现在居然还有马圣开源这套陈年话术的哈哈哈哈哈哈给我笑麻了。上个世纪的遗民Çevir 中文100194
吉光片羽@_withthewind_·1d@CanXuchangsha @naokiaoki7 @zmt021 对,都2026年了还不承认牛顿三大定律是抄的永乐大典,简直是数典忘祖!😀至于开源了什么,你不会去问下grok ?不会?当然,我早说了,互联网有记忆,但蠢货没有!哈哈哈哈哈Çevir 中文00044
多伦多方脸@torontobigface·1d墙内媒体财新网批评华为的逻辑折叠技术 财新网引用业内人士看法 综合性能、功耗上仍无法抹平制程之间的代差差距,不能将其简单理解为到3nm的物理制程跨越 该晶体管密度计算公式采用的是GCP(Gate Contact Pitch,栅极接触间距)指标,其计算结果较业内常用的CPP(Contacted Poly Pitch,栅极间距)要更大,且将3D堆叠的晶体管密度也计入了结果中Çevir多伦多方脸@torontobigface华为在最近表示,自己已经发明了一个叫做逻辑折叠(LogicFolding)的技术 这个技术预计可以让华为,在2031年生产1.4纳米芯片 而台积电此前曾表示,将于2028年开始量产同类产品 中文24427433170.8K70
苏小费@XiaoFei6774·1d@_withthewind_ @naokiaoki7 @zmt021 它开源了啥?汽车要开源什么?宁德时代的电池是特斯拉开源开的?物理层面的开源?电机是开源开的?车机是开源开的?智驾是开源开的?非要给自己找个洋爹Çevir 中文200338
吉光片羽@_withthewind_·1d@CanXuchangsha @naokiaoki7 @zmt021 你也配科普,你怎么不自己变成V3牛逼一把给我们看呢?傻逼。哈哈哈Çevir 中文10054
can xu@CanXuchangsha·1d@_withthewind_ @naokiaoki7 @zmt021 你们这是真的蠢得无可救药,好好的给你这种蠢批科普特斯拉的作用你就知道开源开源,傻逼Çevir 中文10063
吉光片羽@_withthewind_·1d@ethan_stev1020 @naokiaoki7 @zmt021 互联网有记忆,但是你们很可能没有,因为那个时候你们这一代粉红还在幼儿园小学里吃鼻屎。Çevir 中文000194
勾栏听曲@ethan_stev1020·1d@_withthewind_ @naokiaoki7 @zmt021 你说说马斯克开源了什么技术?比亚迪造新能源车的时候特斯拉还不知道在哪呢?国人调侃两句你真以为中国新能源车发展是靠马斯克了?Çevir 中文100244
吉光片羽@_withthewind_·1d@Tailang76710217 @naokiaoki7 @zmt021 各国走的技术路线不一样,欧洲日本有着雄厚的内燃机技术积累和路径依赖,还有环保因素,船大难掉头,自然和中国这种内燃机永远搞不出来只能另辟蹊径的情况不一样。你制度人种优势从来只是在抄袭和牛马血汗成本这一块。跟你们这种满脑子鸡血的脑残谈逻辑真是对牛弹琴。Çevir 中文101259
至死是少年@Tailang76710217·1d@_withthewind_ @naokiaoki7 @zmt021 特斯拉开源了,欧美日的车企咋不学特斯拉呢?除了特斯拉现在欧美日电车领域被中国新能源车企摁在地上摩擦,应该是中国的制度和人种优势吧?哈哈哈哈,现在外网的简中只需要情绪,不需要逻辑,脑残。Çevir 中文101394
can xu@CanXuchangsha·1d@_withthewind_ @naokiaoki7 @zmt021 说实在的,希望你们这些反贼们能有点脑子,要是一个个都你这么蠢我对线都没什么意思了,每天看你们发的这种东西只能让我发笑,简直比视频号那种老年用户群体的见识和逻辑还让人无语Çevir 中文100111
招财猫@xianzhe9527·1d华为又整出一个以“韬(τ)定律”替代“摩尔定律。 简单来说,就是不用死磕光刻机了。 光刻机是全世界在半导体方面最核心的技术,然后我们一直攻克不了,对吧。 所以不用死磕光刻机了,靠 3D 堆叠、系统架构、互联优化,照样可以提升性能,照样可以搞。 就类似于 DeepSeek 不需要最牛逼的芯片,我照样可以通过各种优化,整出最牛逼的模型。 那么我想问拥有更先进制程的美西方在韬定律加持下,岂不是起步就比我们更有优势?Çevir 中文97711693.3K21
苏里格@szslg·1d华为下一代手机Mate 90,搭载的芯片是9050,这款芯片由中芯国际加工,通过3D IC堆叠方案实现了突破。目前测试结果非常超预期,性能比苹果高端的A18芯片(24年9月发布)要强,跟台积电用3nm先进制程做的N31芯片性能差不多。(中信建投 于芳博)Çevir 中文1041111159.8K15
吉光片羽@_withthewind_·1d@CanXuchangsha @naokiaoki7 @zmt021 啊对,时间一长就可以不承认了,牛顿三大定律都是偷学《永乐大典》了。😁互联网有记忆,但蠢货没有脑子。Çevir 中文306721
吉光片羽@_withthewind_·1d@naokiaoki7 @zmt021 当年没有马斯克技术开源,国内新能源车有一个算一个,全是骗补!那时候已经有互联网了,互联网是有记忆的!Çevir 中文200313.4K
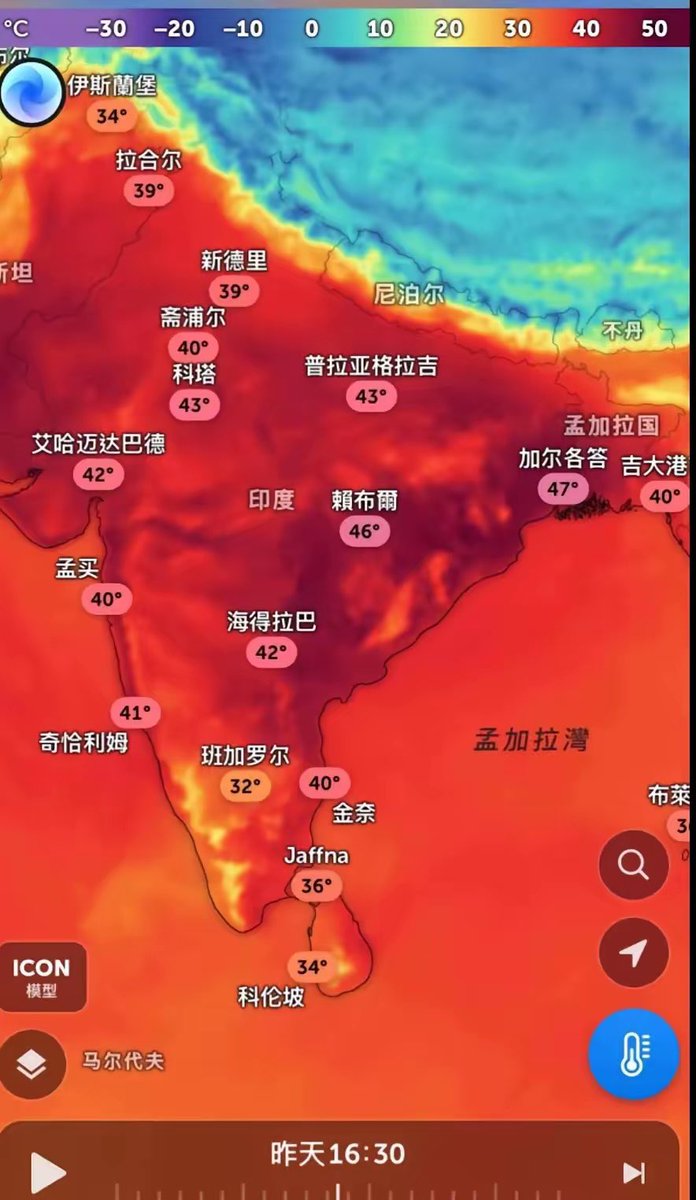
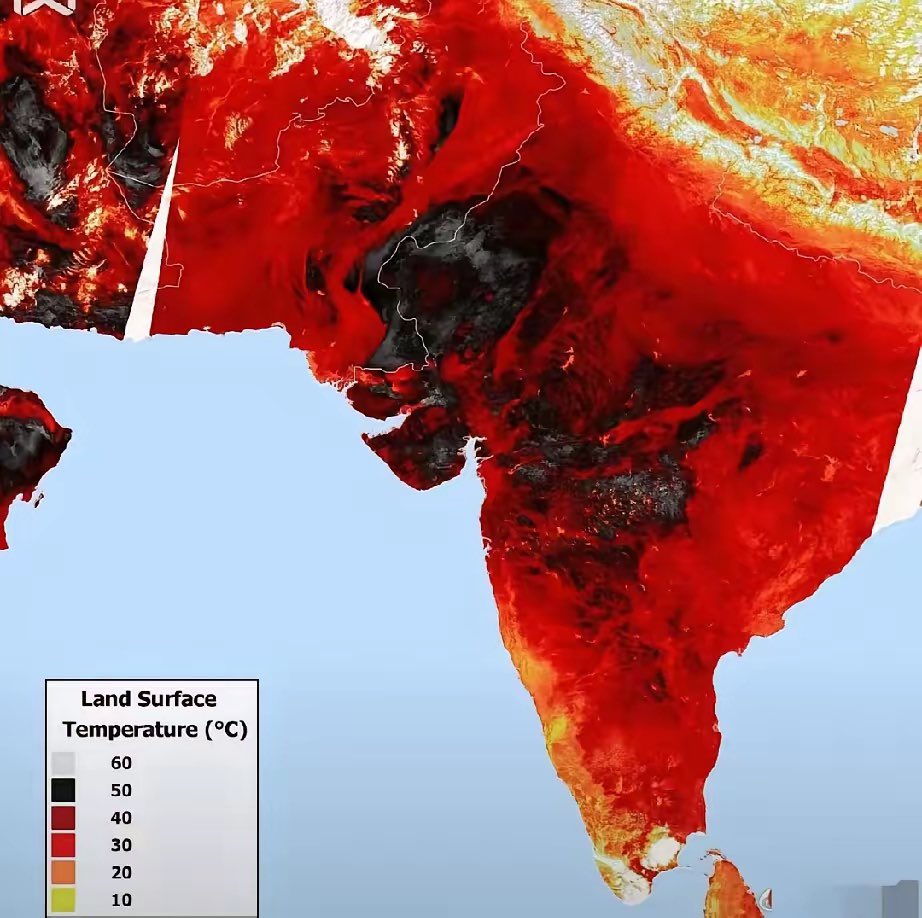
吉光片羽@_withthewind_·3d@Kongkongda5882 没有喜马拉雅,印度会凉爽很多,西藏和中国西北也会温暖湿润很多,这算什么伟大呢?如果有什么功在当代利在千秋的人类超级工程,两国合伙在山脉中间打一个大的走廊出来,肯定算一个。Çevir 中文2002927.8K
空空道人@Kongkongda5882·3d再次证明了喜马拉雅山脉的伟大不是只在高度 印度现在简直就是一个巨大熔炉、最高气温已经突破47度了 这是什么概念、一个健康的成年男性如果暴露在这种环境下没有防护措施的生存窗口只有1-2个小时 而这种极端天气却活生生被喜马拉雅山脉给挡了下来、果然呀喜马拉雅山的伟大绝对不仅仅是因为它足够高!Çevir 中文2411421.6K754.7K358