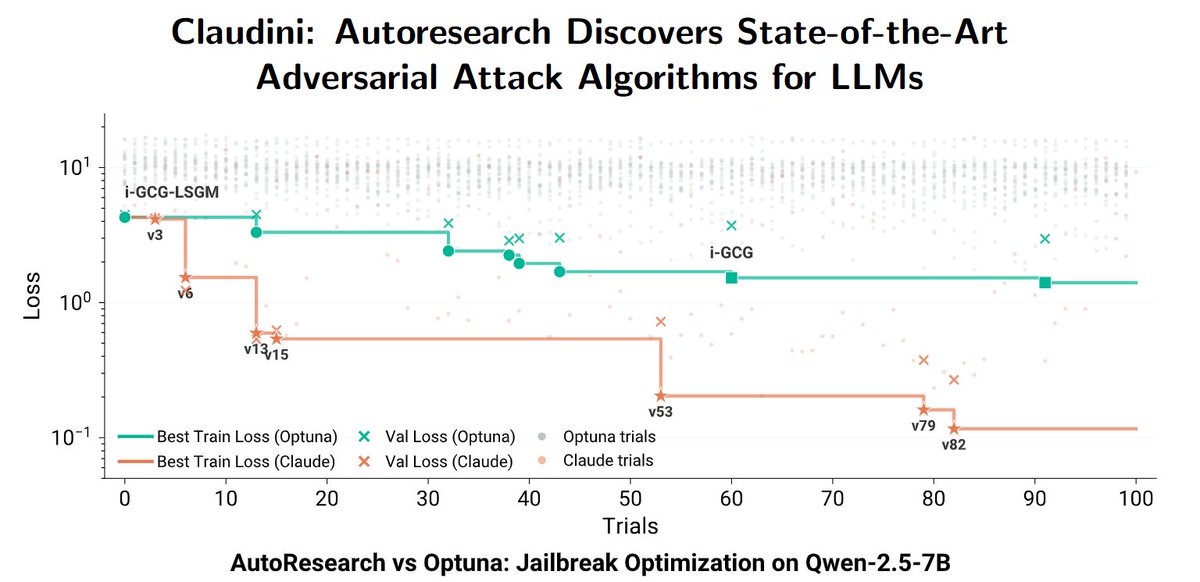
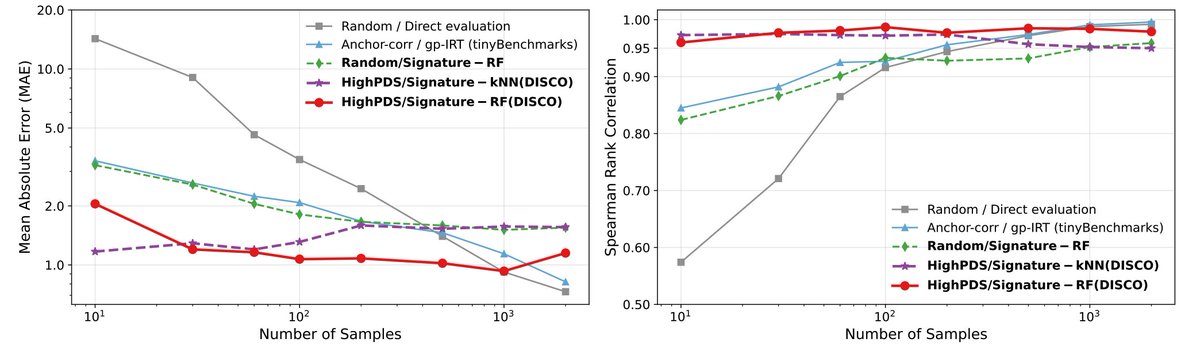
Sabitlenmiş Tweet

🪩 Evaluate your LLMs on benchmarks like MMLU at 1% cost.
In our new paper, we show that outputs on a small subset of test samples that maximise diversity in model responses are predictive of the full dataset performance.
Project page: arubique.github.io/disco-site/
More below 🧵👇

English