
Aitor Bediaga
10.5K posts

Español

Os comento algunos resultados preliminares:
1/ He parseado 126.065 PDFs del BORME desde 2009 hasta hoy. ¿Por qué 2009? Porque ahí cambió el formato del boletín. Antes de eso la estructura es diferente y requiere otras técnicas, pero 2009-2026 cubre la inmensa mayoría de empresas activas hoy.
2/ El problema del cruce: el BORME no publica el CIF de las empresas. Solo el nombre y los datos registrales (tomo, hoja, inscripción). Así que para cruzar con licitaciones toca hacer matching por nombre normalizado: quitar acentos, unificar formas jurídicas (S.L. = SL = Sociedad Limitada), eliminar paréntesis, guiones, etc.
Resultado: de 5,9M de adjudicaciones en el PLACSP, 3,8M cruzan con alguna empresa del BORME. Un 64%, que representa 1.482 mil millones de euros en contratos (67% del importe total). El 36% restante son autónomos (personas físicas que no aparecen en el Registro Mercantil), UTEs, y empresas constituidas antes de 2009.
3/ ¿Y las homónimas? Sin CIF, "CONSTRUCCIONES GARCIA SL" en Madrid y en Sevilla son la misma empresa para nosotros. Para medir el problema, analicé los NIFs del propio PLACSP: el 95% de los nombres normalizados corresponden a un único CIF. La homonimia existe pero es baja.
4/ Con ese cruce he buscado 5 tipos de anomalías:
Empresa recién creada: constituida menos de 6 meses antes de ganar un contrato público. Salen 16.337 adjudicaciones.
Capital ridículo: empresa con menos de 10.000€ de capital social ganando contratos de más de 100.000€. 71.461 adjudicaciones.
Multi-administrador: la misma persona aparece como cargo en más de una empresa. 1.052.326 personas. Este flag todavía está crudo — lo interesante será cruzarlo con PLACSP para ver si esas empresas compiten en las mismas licitaciones.
Disolución post-adjudicación: la empresa se disuelve menos de un año después de ganar el contrato. 9.928 adjudicaciones.
Adjudicación en concurso: empresa en situación concursal recibiendo contratos públicos. 9.655 adjudicaciones.
Ninguno de estos flags es una acusación. Crear una SL con 3.000€ de capital es perfectamente legal. Que un administrador esté en 5 empresas también. Son señales que, acumuladas o combinadas, merecen una segunda mirada.
5/ Lo que falta: cruzar los multi-administradores con licitaciones concretas, analizar cambios de cargos alrededor de las fechas de adjudicación, incorporar contratos menores, y buscar fuentes complementarias de CIF para mejorar el matching.
Vamos a ello.
Gerard@Gsnchez
A puntito de acabar de parsear los ∼126K PDFs del BORME... ~9M de actos societarios y ~14.5M de cargos extraídos con pdfplumber + regex sobre 17 años de Boletín Oficial del Registro Mercantil. Pronto cruzaremos esto con licitaciones públicas 👀
Español
@AlbertoMar_CT @Gsnchez Si luego vas a compartir los resultados derivados del acceso sin problema.
Español
@Gsnchez @twitEnriqueSL Hola. Yo tengo actualizado el scraper del BORME. Y además he identificado el 90% de las empresas con su NIF. Me escribes y comentamos.
Español
@twitEnriqueSL No la conocía, se puede descargar todo masivamente ahí? A mi lo que me interesa son los cruces con las licitaciones.
Español
Caso hipotético (o no): una empresa se constituye en marzo de 2019. Cero empleados, cero web, cero historial. A los seis meses se lleva un contrato público de 400K€ como único licitador. A los tres meses se disuelve.
Plot twist: su administrador es el mismo que el de otras dos sociedades que licitan al mismo organismo. Misma dirección fiscal las tres.
Hasta ahora no había forma automatizada de detectarlo cruzando fuentes públicas.
Me he descargado ∼64.000 pdf (2001-2026) del BORME para cruzar el Registro Mercantil con la contratación pública española.
El objetivo es construir un grafo real de relaciones societarias y detectar patrones que hoy pasan desapercibidos. Detectar empresas vinculadas dependía de heurísticas: fuzzy matching por nombre similar o NIFs consecutivos.
Pasamos de "estas dos empresas se llaman parecido" a "estas dos empresas comparten administrador y se constituyeron con tres días de diferencia".
Os subiré el scraper y el parser cuando los tenga afinados.

Español
@Josebaseba @microlinkhq @Kikobeats He probado con una web que aún no he podido scrapear hoka.com y funciona muy bien y muy rápido.
Español

@abediaga @microlinkhq @Kikobeats Eso es, justo.
Es una capa de abstracción por encima de cualquiera de esas dos soluciones.
Y para muchos es un dolor mantenerlo escalable.
Español
Ahora las buenas noticias, tengo nuevo objetivo vital:
No he tenido que buscar porque ya sabía a donde tenía que ir.
Empiezo a trabajar como CPO en @microlinkhq con @Kikobeats
Se alinearon los astros, nos aliamos y vamos a empujar juntos.
Con mi entrada duplicamos el equipo😄
Español
@Josebaseba @microlinkhq @Kikobeats Pero eso lo puedo hacer yo con Selenium o Playwright por ejemplo. Entiendo que aquí la diferencia es que no necesitas levantar nada y solo es una llamada a la API...
Español
@abediaga @microlinkhq @Kikobeats La parte de scrapping "normal" de ML está orientado a normalizar cualquier web y garantizarte que en un JSON te lleguen todos los campos comunes.
Con esto ML puede darte previews de cualquier web con mucha consistencia, lo que sería otra vertical.
Español


Evolución anual de las matriculaciones de BYD, 100% eléctricos, en España.

Español

@CECOTECoficial llevo 10 días esperando una compra y ni vosotros ni la empresa de transporte me informan cuando llegará el pedido. Lamentable servicio postventa. Una y no más.
Español



@Gsnchez Pero webscrapping serio… proxys, peticiones http, selenium, etc.
English
En bquantfinance.com parece que de momento lo que más interesa es la parte de value investing cuantitativo, imagino que será lo próximo a ampliar. Pero os digo una cosa, os podría hacer un módulo de webscraping especializado en proveedores financieros que os sorprendería 🤣
Español
@Gsnchez Yo utilizo una Raspberry pi 3 en casa. Y para algunos casos de peticiones recurrentes desde diferentes IPs uso vps de digitalocean.
Español

Necesito una herramienta para guardar y consumir info random que me voy encontrando. Debería tener, como mínimo, estas siguientes características:
1. Multidispositivo
2. Que sea fácil enviarle recursos desde cualquier lado (whatsapp, twitter, email, youtube, spotify... wherever).
3. Que permita organizar por carpetas con facilidad
4. Curva de aprendizaje fácil. No quiero un segundo cerebro de esos
5. Fácil de manejar internamente (seleccionar varios para borrarlos, moverlos, lo que sea).
6. Diferentes ordenamientos de la info (para poder ponerlo cronológico con los más antiguos primeros)
7. Idealmente, ver/leer/escuchar en la propia herramienta el contenido que sea, para no tener que salir y volver a entrar para borrar ese recurso.
Español

¿Quieres conocer cómo es el ecosistema de Inteligencia Artificial de Canadá? Puedes leer mi análisis aquí. datadragon.ai/el-ecosistema-…

Español
@irene_analista @LaRutaMacguffin Seguro que en algo más que un hilo queda. Tus lectores necesitamos la versión larga en un post.
Español

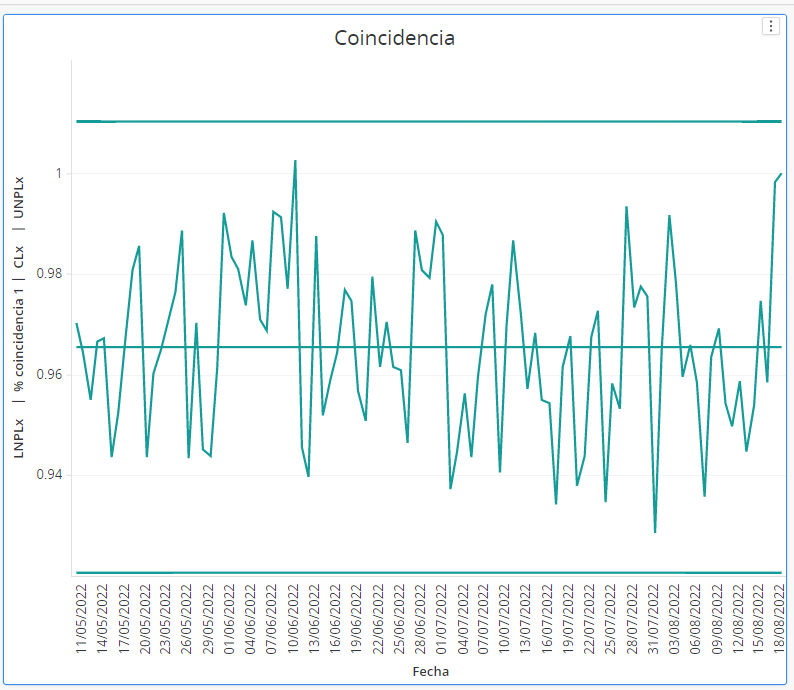
Y con esto no sabía si escribir un artículo no solicitado para @LaRutaMacguffin , un doctorado, un libro o un guión de ficción. Pero tengo mucha plancha y... seguramente..se quede en este hilo resumido "Cómo cristalizar en un simple gráfico 6 añitos de aventuras y desventuras"😇
Español
En un par de semanas UNA hace seis años como analista 🎂🎂..Y MI PEQUEÑO CEREBRO de mujer ha dado hoy con la última tecla para regalarme...un Gráfico de Control con el que monitorizar la coincidencia de conversiones de una BD y GA (para una misma fuente/medio)
Español