Sabitlenmiş Tweet

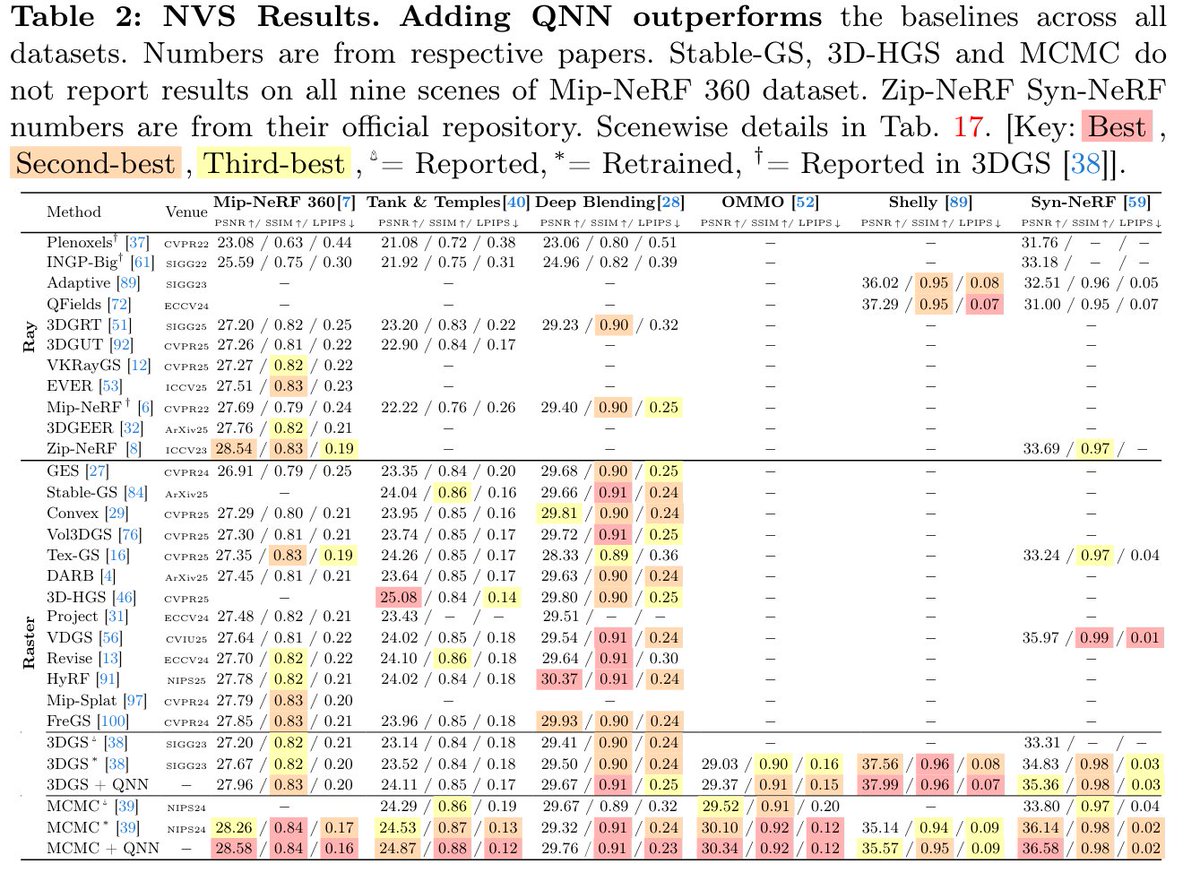
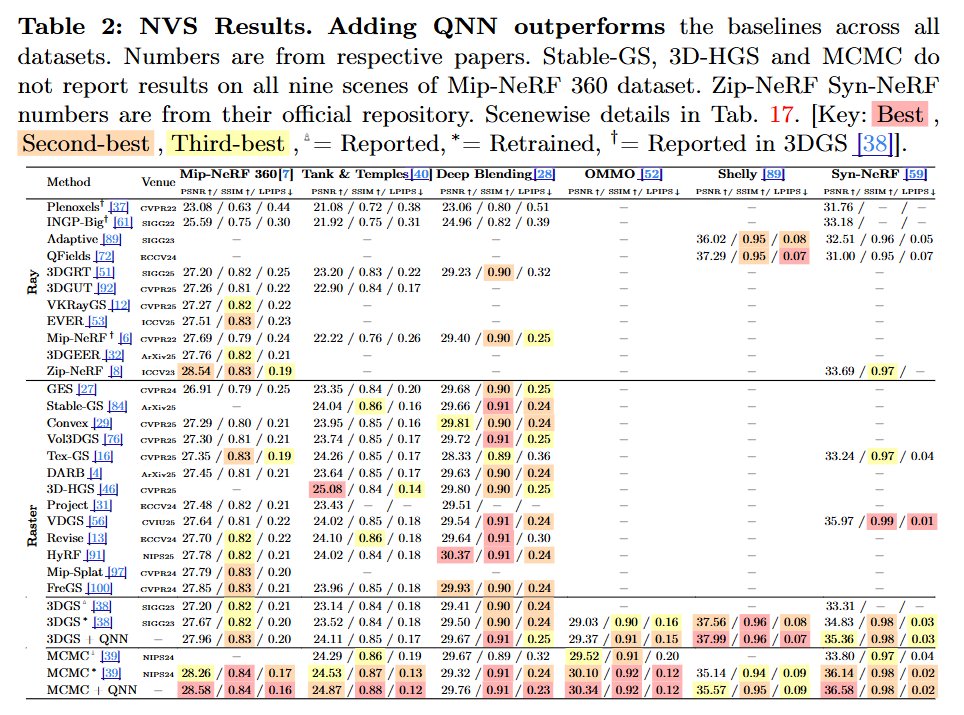
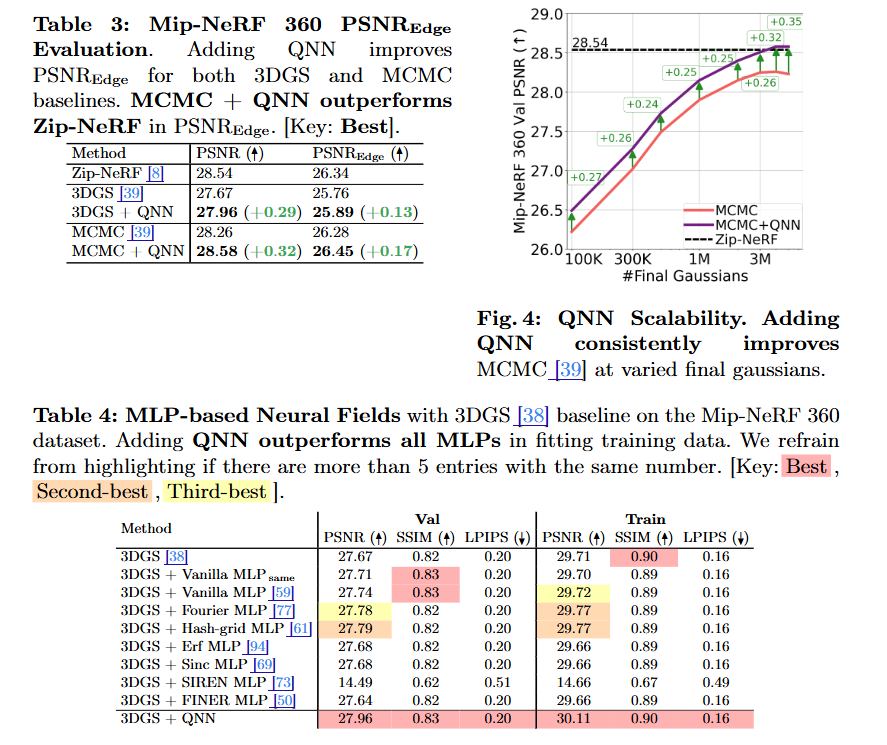
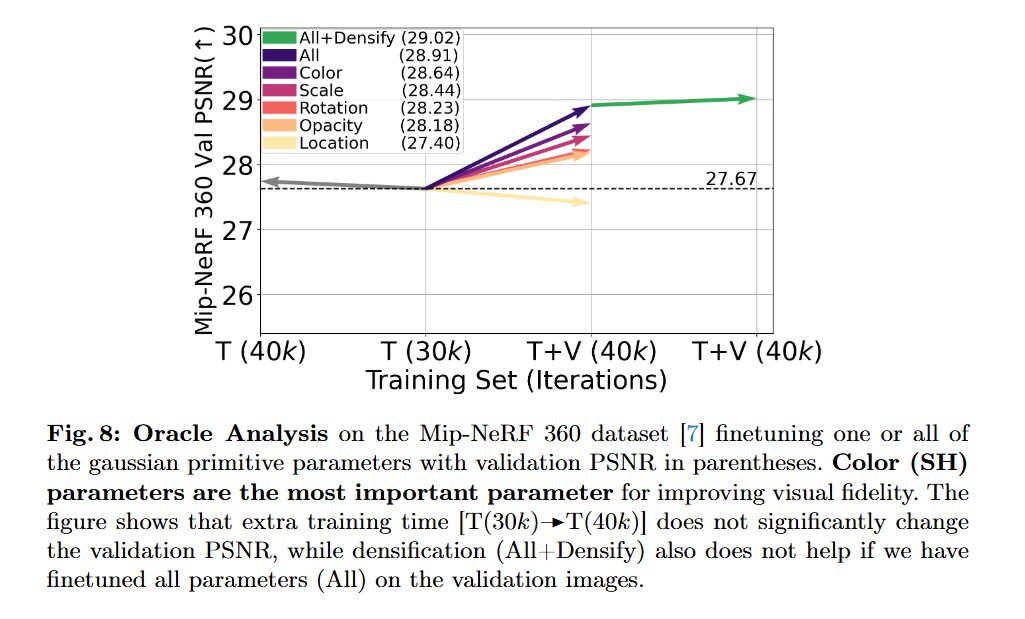
Add QNN to MCMC GS reaches Zip-NeRF-level fidelity at 10× less training time and 40× higher FPS compared to Zip-NeRF @TristanAA97 @lazarvalkov @beakywings
MrNeRF@janusch_patas
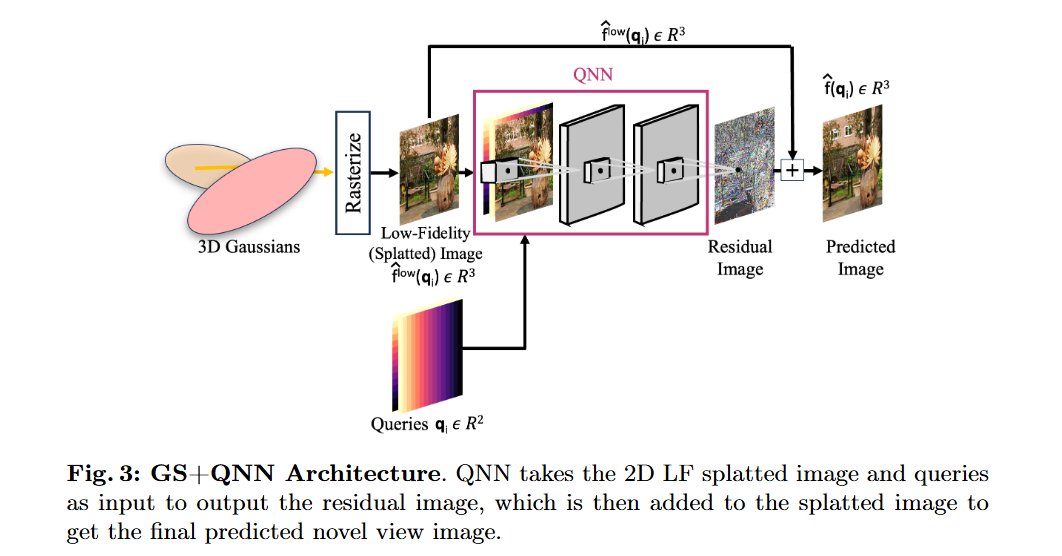
Towards High-Fidelity Gaussian Splatting with Queried-Convolution Neural Networks Contributions: • We propose QNNs, an architecture that convolves both low-fidelity signals and queries to improve the learning of details. • We theoretically investigate the predictive power of QNNs compared to CNNs (Theorem 1) and the number of Gaussians for increasing fidelity (Corollary 1). • We empirically show that GS-based baseline with a QNN surpasses Zip-NeRF [8] in the 3D NVS task (Sec. 5.1). • Our experiments also show that QNNs enhance performance on 1D regression, 2D regression, and 2D SR tasks (Sec. 5.4).
English