Ravi Theja@ravithejads
🚀 RAPTOR: RECURSIVE ABSTRACTIVE PROCESSING FOR TREE-ORGANIZED RETRIEVAL 🌟
Current RAG systems struggle with thematic questions that require information from various parts of a document/ text.
For instance, answering "How did Cinderella reach her happy ending?" from the NarrativeQA dataset requires synthesizing text from multiple document parts.
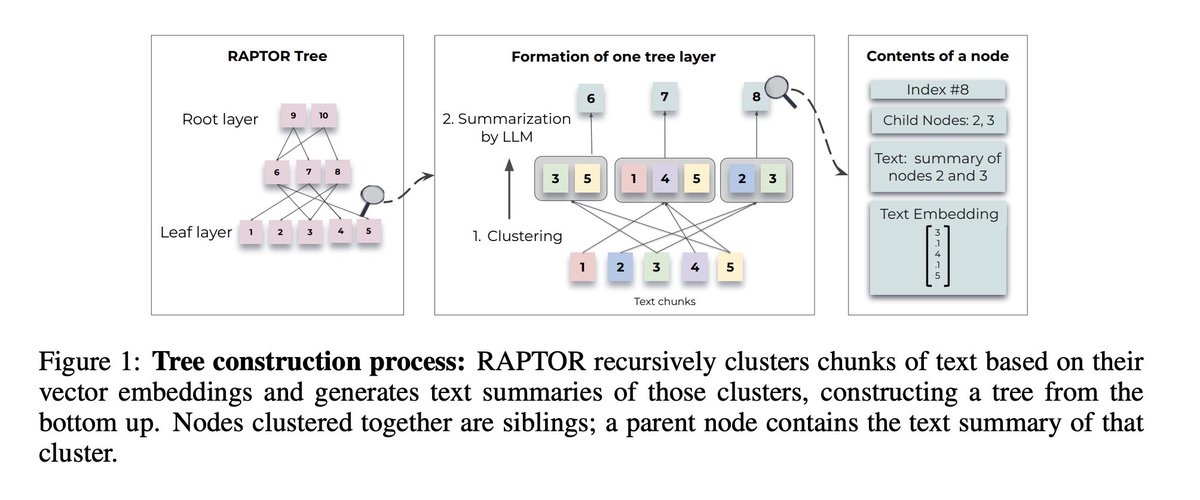
This paper tackles the problem by recursively embedding, clustering, and summarizing text chunks into a summary tree, offering a layered understanding.
💡Approach Highlights:
Segmentation and Initial Embedding:
1️⃣ Divide the text corpus into 100-token chunks, ensuring sentences remain intact for context preservation.
2️⃣ Each chunk is embedded, forming the leaf nodes of the RAPTOR tree.
Clustering and Summarization:
1️⃣ Group similar text chunks using a clustering algorithm.
2️⃣ gpt-3.5-turbo summarises these grouped texts. The summaries are then re-embedded, serving as nodes at the next level of the tree.
3️⃣ Repeat this process to build a structured, multi-layered summary tree.
During the querying stage, it employed two distinct mechanisms in the multi-layered RAPTOR tree.
Tree Traversal Approach:
1️⃣ The retrieval process begins at the root of the RAPTOR tree, selecting the top-k nodes most relevant to the query based on cosine similarity.
2️⃣ This selection process continues layer by layer, moving down to the children of the initially selected nodes and choosing the top-k at each level.
3️⃣ The text from all selected nodes across the layers is concatenated to form the final retrieved context.
Collapsed Tree Approach:
1️⃣ The entire RAPTOR tree is collapsed into a single layer, simplifying the search process.
2️⃣ Cosine similarity is calculated between the query and all nodes in this collapsed layer.
3️⃣ The top-k most relevant nodes are selected based on their similarity to the query, up to a maximum token limit to fit the model’s input constraints.
🎯 Result:
RAPTOR with GPT-4, boosted the performance on the QuALITY dataset by 20% in absolute accuracy.
It's important to note that RAPTOR scales linearly in terms of both build time and token expenditure, making it suitable for processing large documents.
Paper: lnkd.in/gpCGHr95