
Aditya
198 posts

Aditya retweetledi

this is a naive understanding of where models are headed. cursor is a prime example of this. they built one of the best coding harnesses, but opus 4.5 absorbed the entire harness into the model, making years of cursor’s work redundant.
yes, you need a harness, but it should be minimal, just enough to build an interface between the api and the user, nothing else.
pi coding agent is the classic example here.
dharmesh@dharmesh
The harness matters more than the model. Models have gotten really good. Great reasoning, large context windows, better instruction following. But, what makes *use* of those capabilities is actually the harness. It's what provides tools, memory, skills and context to the model. ChatGPT is a harness. Claude Cowork is a harness. Without the harness, the model is just an engine with no car. You don't get anywhere.
English
Aditya retweetledi

We desperately need better ways of evaluating models. Something that shows how helpful they are at working hand-in-hand with humans to help them get stuff done in a cooperative/iterative way.
The Claude models have consistently been better at this, and the market rewards that.
English

Gotta say Microsoft clip champ is so intuitive never edited a video but managed do what had to be done at last minute
English
@prastran_inc i always wanted something like this during college!!
something that go through the college email and whatsapp and just notify me of what's due for submission.
English
well i just made something to help my adhd a script that goes through my whatsapp and my emails to remind me of my obligations it presents this stuff into a go tui which starts up on worspace on my laptop as soon as it starts up really helpful

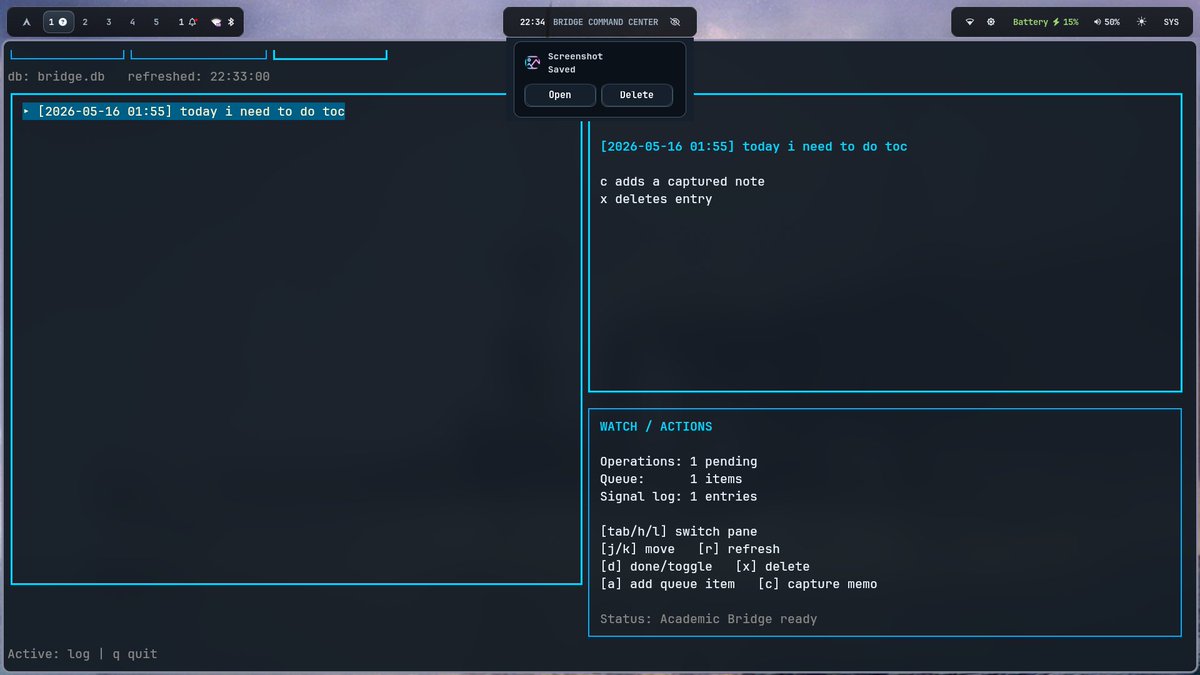
English
built a pi extension to enable fast mode for openai models on pi
incase you want to try it out - github.com/aditya-borse/p…
English
@himanshustwts true. also i think there is nothing like a non verifiable task. it is all about are you creative enough to come up with a feasible and a fair verifier.
English

there are many many domains for training data / envs which are under explored right now and this can be realized from the fact that so far it followed a single principle - how easily you can verify the output.
well coding evolved cuz it offered free programmatic verification and building the equivalent "compiler" for other domains is one of the interesting (and intensive) problems to work on. example: bio is the frontier of the verification problem right now.
English
@paraschopra true, we need more benchmarks like arc agi 3 which measure skill acquisition efficiency.
English

Been thinking a lot about continual learning and I feel we probably have it backwards.
Most formulations care about reducing “catastrophic forgetting” on previously learned tasks when you learn new tasks, but what matters in the real world is speed of adaptation to new tasks.
It’s irrelevant if, as adults, we can solve grade 10 math exams; what matters is if we have learned good representations that are composable such that we can adapt to new tasks with minimal training. You’ve trained well if you can re-learn grade 10 math quickly as an adult, not that you can solve it out of the box.
So we should be measuring performance of AI systems on future expected distributions of tasks, not the distribution encountered in the past.
English


Code is actually the right abstraction.
Too often I see the future of software engineering diminished down to, effectively, writing and reviewing markdown files.
Yes, it will be hard to review thousands of lines of agent code. But maybe the takeaway is that you want less code?
Rather than just giving up ("well I guess we won't read the code, or we'll read this lossy markdown summary") this should be a signal forcing you to think about better systems.
- How can we make our codebase more verifiable? For example, fast/robust/stable tests, or moving to a typed language.
- How can we deslop or improve the architecture/abstractions of the code generated by agents? For example, spending more time up front on the codebase architecture/types before yolo generating all of the code.
- How are we going to maintain and evolve this codebase over time? The slop compounds. One great solution here is... you guessed it, learning from the past decades of software engineering! For example, you might just have the wrong abstraction entirely, leading to a ton of duplicated code.
I think the markdown folks *are* right in some ways. If you are using skills every day, for many different prompts and workflows, isn't that effectively "coding with markdown"? Kinda.
There's been plenty of ink spilled on the merits and benefits of skills. To me, skills make your style of working legible for agents. They don't replace code and that's not really the point.
In reality, there's this messy and constantly re-evolving future in which both of these things are true:
1. Skills (and markdown) are important for how you give input to the agents and ensure high-quality code & systems are created
2. Looking at the actual code will not be replaced by markdown summaries or a collection of spec documents that ignore the lower level details of the code
In summary: reality has a surprising amount of detail (and nuance)!
English


Aditya retweetledi

Sufficiently advanced agentic coding is essentially machine learning: the engineer sets up the optimization goal as well as some constraints on the search space (the spec and its tests), then an optimization process (coding agents) iterates until the goal is reached.
The result is a blackbox model (the generated codebase): an artifact that performs the task, that you deploy without ever inspecting its internal logic, just as we ignore individual weights in a neural network.
This implies that all classic issues encountered in ML will soon become problems for agentic coding: overfitting to the spec, Clever Hans shortcuts that don't generalize outside the tests, data leakage, concept drift, etc.
I would also ask: what will be the Keras of agentic coding? What will be the optimal set of high-level abstractions that allow humans to steer codebase 'training' with minimal cognitive overhead?
English
Aditya retweetledi

It's easy to claim the end of white collar work. But very hard to get LLMs to reliably edit PPTX.
A lot of the workflows our agents address have LLMs taking PPTX, DOCX, XLSX and editing them to get real world outcomes out.
A lot of the white collar work is just this.
We've tested this extensively, and performance is consistently poor unless you write painstaking, slide-by-slide prompts defining what "acceptable" looks like. At which point, it’s almost not worth it because of how much these templates and expected outcomes change in the real world.
My co-founder has penned down some of his thoughts on how different models perform at simple PPTX editing tasks in the URL below. Please check it out and hit us up with any feedback :)
English

Can anyone recommend a dead simple, easy to use notetaking app based on markdown files?
Obsidian is far too complicated for me. I'm looking for Apple Notes, but with markdown storage
English
Aditya retweetledi

