Afshin Dehghan retweetledi

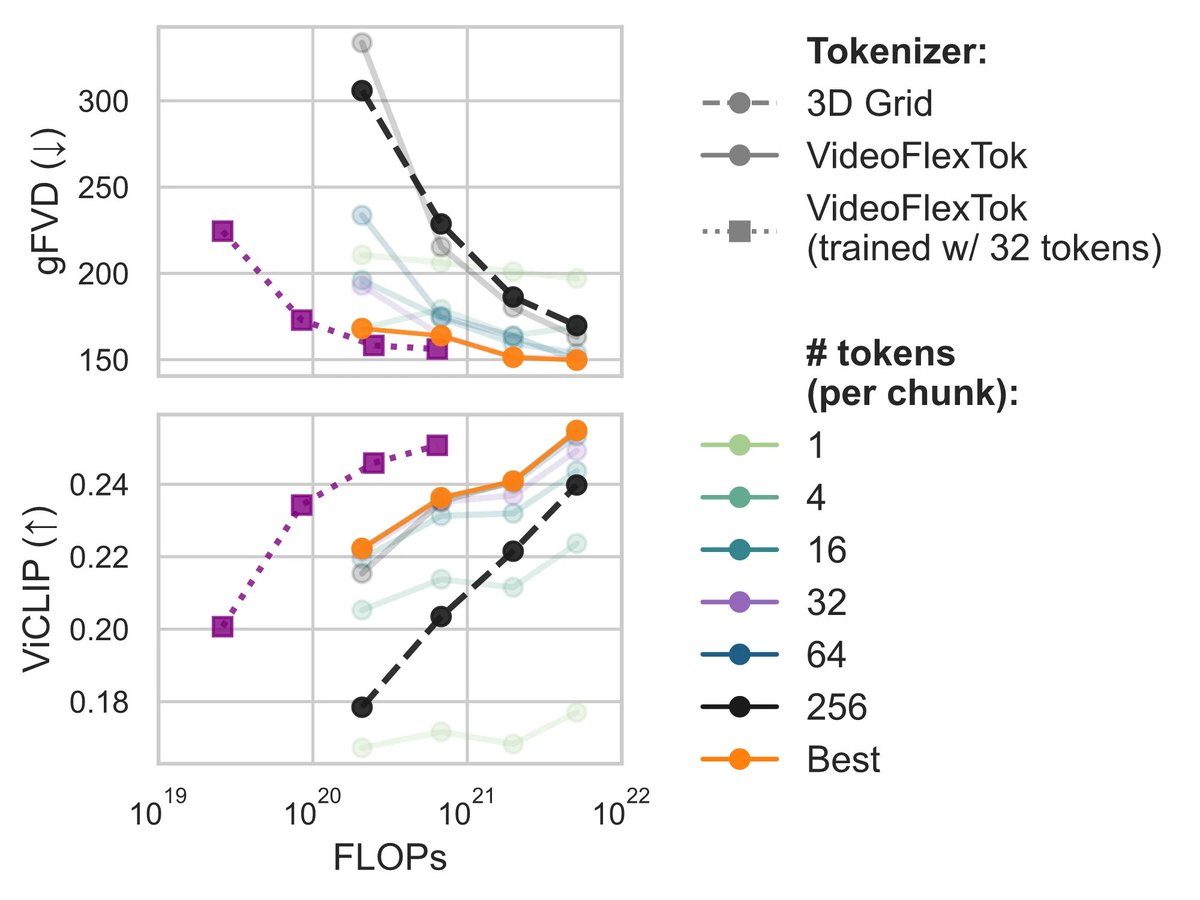
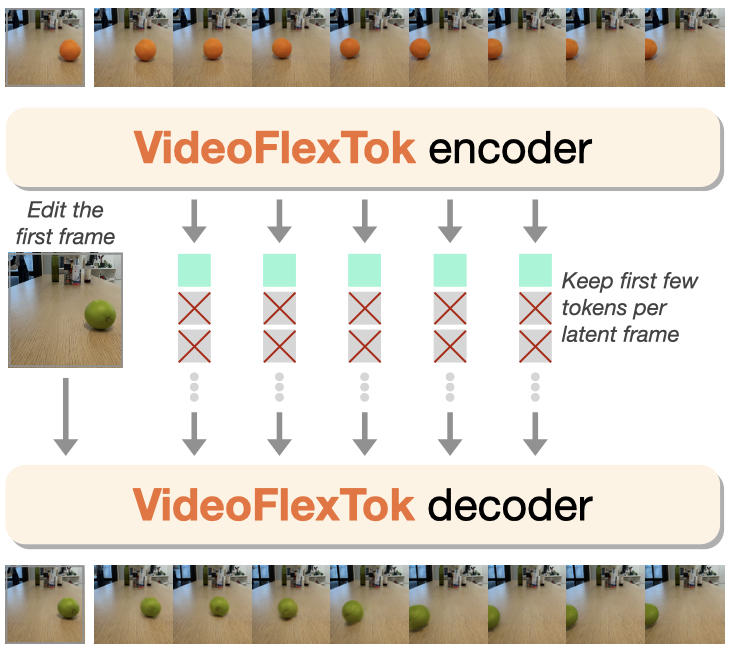
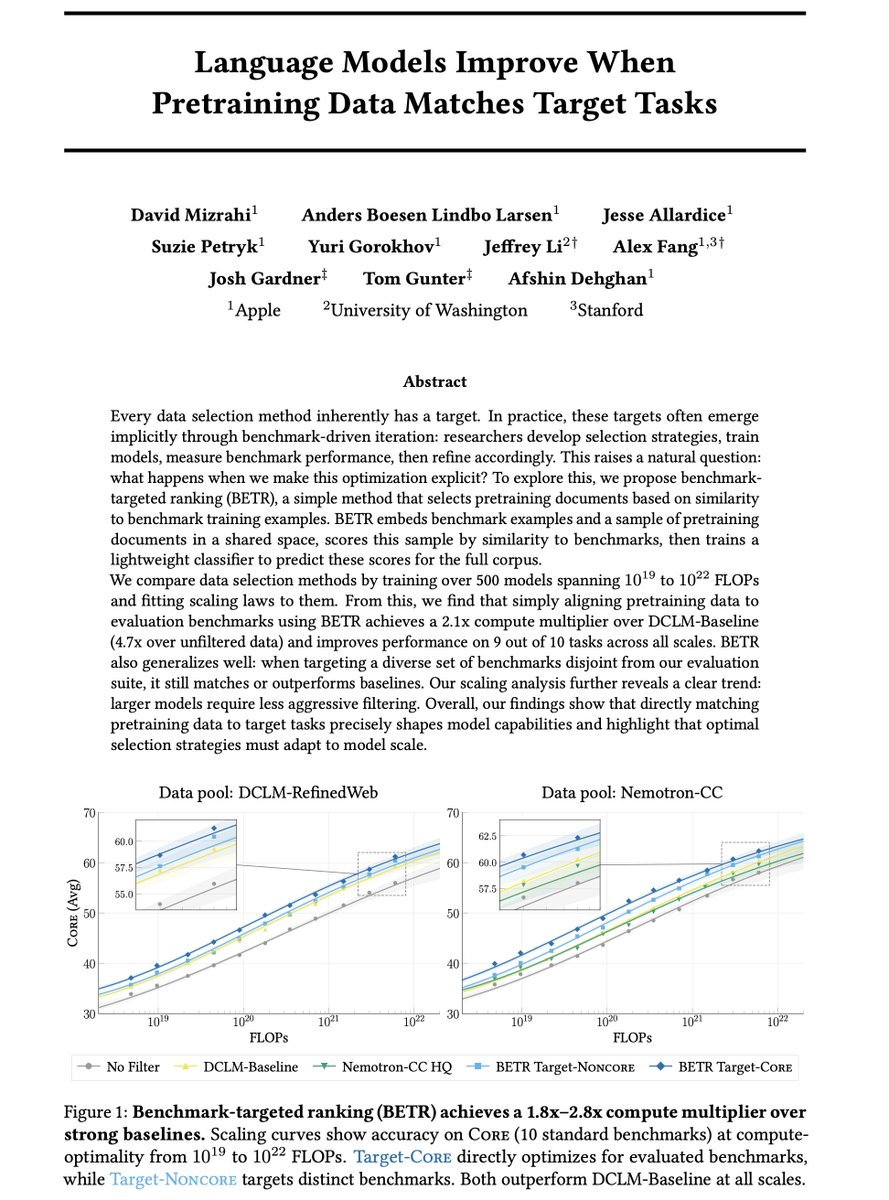
Moving forward, we're excited to see what coarse-to-fine representations can enable beyond generation: world models that plan at different levels of abstraction using fewer tokens, efficient test-time scaling, as well as extending the framework to longer temporal signals and other modalities.
8/n
English