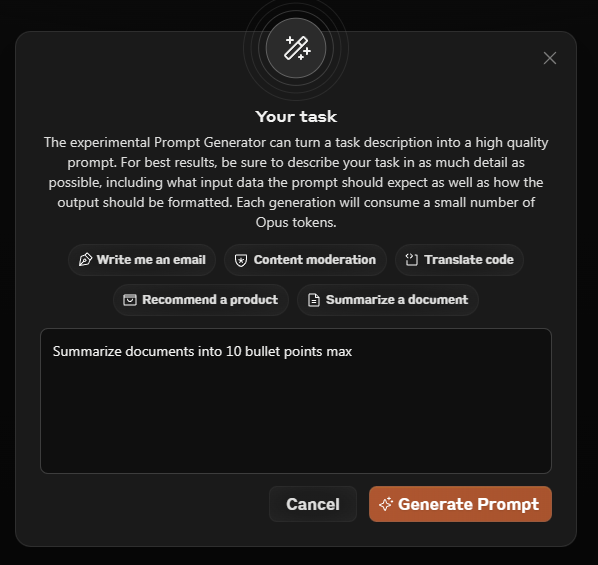
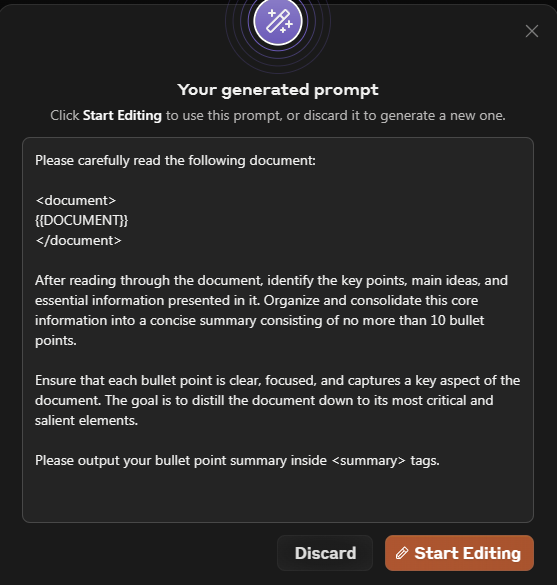
@emollick Absolutely yes to this. I’ve been saying for some time now that prompt engineering is really a function the effectiveness of the model. It’s a semantic reasoning engine so the better it gets, the more the UX changes and UI (prompt engineering) melts away.
English