Parolalar artık hem kullanıcılar, hem de ürünler için yönetilmesi zor bir operasyonel engele dönüştü. SMS OTP maaliyetleri, parola yenileme süreçlerinin güvenlik gerekçesiyle giderek karmaşıklaşması kullanıcı kaybına yol açıyor.
FIDO Alliance standartları ve WebAuthn altyapısı üzerine inşa edilen Passkeys, bu mimariyi kökten değiştiriyor. Artık sunucuya parola göndermek yok.
Peki, arka planda birbirini tamamlayan o anahtar - kilit ilişkisi nasıl çalışıyor? Sadece biyometrik doğrulama ile bütün doğrulama işlemlerini gerçekleştirmek ne kadar güvenli?
Bu yeni nesil kimlik doğrulama standardının temel mantığını ve Passwordless Life 1.0 olarak adlandırdığım vizyonu, kendi bakış açımla derlediğim yazı serisinin ilk bölümü Medium'da yayında ✅
Parolasız geleceğin nasıl inşa edildiğini merak ediyorsanız göz atmanızı öneririm
🔗 @agitrubard/passkeys-nedir-passwordless-life-e6ae061500f3" target="_blank" rel="nofollow noopener">medium.com/@agitrubard/pa…
JetBrains, Cursor rekabetine çok farklı bir açıdan cevap verdi.
Yeni duyurdukları air.dev (JetBrains Air) aracıyla hedefleri kullandığımız IDE arayüzüne sadece bir yapay zeka sohbet penceresi sıkıştırmak değil. Olayı bambaşka bir yöne eviriyorlar.
Bu araç temelde farklı otonom agentları yönetebildiğiniz bağımsız bir geliştirme ortamı olarak tasarlanmış. Yani Claude, Gemini veya farklı modelleri aynı anda, birbirine müdahale etmeden çalıştırabileceğiniz bir platform sunuyorlar.
İşin maliyet kısmı da oldukça esnek çözülmüş. Herhangi bir abonelik zorunluluğu yok, kendi API anahtarınızı sisteme girip sadece harcadığınız kadar ödeyerek agentları kullanabiliyorsunuz. Ekstra bir platform üyeliğine bütçe ayırmaya gerek kalmıyor.
Bildiğiniz gibi Cursor her şeyi tek bir ekranda çözmeye odaklanıyor. JetBrains ise Air aracıyla mevcut çalışma düzenimizi hiç bozmadan, agent tabanlı karmaşık işleri ayrı bir yerde planlamamızı, standart kodlama sürecine ise yine kendi bildiğimiz ortamda devam etmemizi amaçlamış. Bir nevi projeye özel agent orkestrasyonu yapıyor diyebiliriz.
Şu an macOS için önizleme sürümü yayında, Windows ve Linux desteği de bu yıl içinde gelecekmiş.
🔗 blog.jetbrains.com/air/2026/03/ai…
Java 26 ile birlikte final kelimesi artık gerçekten final oluyor.
Eskiden final olarak tanımladığımız değişkenleri arka planda Reflection gibi yöntemlerle gizlice değiştirebiliyorduk. Artık Java bu arka kapıyı tamamen kapatıyor.
Peki bunu neden yapıyorlar? Asıl sebep performans. Java sisteminin arka planda çalışan motoru, bir değişkenin hiçbir zaman değişmeyeceğinden kesin olarak emin olursa kodları çok daha hızlı çalıştırabiliyor. Eski açık yüzünden bu hızlandırmayı tam anlamıyla yapamıyordu. Artık Java kendi kurallarına %100 güvenmek istiyor.
Korkulacak bir durum var mı? Şu an için hayır. Java 26 şimdilik sadece ufak bir uyarı veriyor. Yani projeyi güncellediğinizde uygulamalar anında durmayacak. Ancak ileriki sürümlerde bu işlem kesinlikle hata verip kodun çalışmasını engelleyecek.
Bu durumdan en çok, arka planda gizlice değişken değiştiren eski tip kütüphaneler etkilenecek. Spring gibi modern araçların yıllardır önerdiği doğru yöntemleri kullananlar ise çok rahat edecek.
Alıştığımız ve sevdiğimiz JetBrains ekosistemini (IntelliJ IDEA, WebStorm, PyCharm vb.) terk etmeden, Cursor'ın o çok konuşulan yapay zeka yeteneklerini kullanabilmek hepimizin beklediği bir gelişmeydi.
İşin en güzel yanı; bu entegrasyon sayesinde artık ekstra bir JetBrains AI aboneliği satın almanıza gerek kalmıyor! Mevcut çalışma ortamınızı değiştirmeden, kod yazım hızınızı ve verimliliğinizi doğrudan Cursor'ın güçlü AI Agent'ı ile zirveye taşıyabilirsiniz.
Hem maliyetten tasarruf edip hem de piyasadaki en iyi AI kodlama asistanlarından birini kendi IDE'nizde kullanmak büyük bir konfor.
🔗 blog.jetbrains.com/ai/2026/03/cur…
Haftalık toplantımızı gerçekleştirdik. 📷
Bu hafta tamamladığımız görevleri paylaştık, önümüzdeki günler için ilerleme planımızı anlattık ve sorularımızı yanıtladık.
Birlikte üretmeye, öğrenmeye ve ilerlemeye devam! 📷
#afetyönetimsistemi
AYS ekibi olarak haftalık toplantımızı gerçekleştirdik🚀
Bu hafta tamamladığımız görevleri değerlendirdik, geliştirmelerimizi paylaştık ve aklımıza takılan soruları birlikte çözdük.
Gelecek toplantılarda görüşmek üzere 🙌
#afetyönetimsistemi
Yeni bir şeye başlarken, ilk günlerdeki hızlı ilerleme bir süre sonra yavaşlayınca “ben bunu yapamıyorum” sanıyoruz.
Oysa çoğu zaman sorun yetenek değil.
Learning curve’un doğal kırılma noktası.
Başta her şey hızlı akar:
Yeni kavramlar oturur, küçük başarılar gelir, motivasyon yükselir.
Sonra bir gün tempo düşer.
Aynı çabayla daha az sonuç almaya başlarsınız.
İşte çabalamayı bıraktığımız nokta genelde burası:
İlerleme görünmez hale geldiğinde.
Bu noktada iki şey olur:
Emek hâlâ vardır ama çıktı daha yavaş gelir.
Beyin “boşa uğraşıyorum” sinyali üretir.
Ama: Bu dönem çoğu zaman “kötü gidiş” değil, derinleşme dönemidir.
Temel öğrenme biter, artık detaylar ve tekrar başlar.
Ve tekrar, dışarıdan bakınca sıkıcı görünür.
Burada ayrımı yapan şey şu olur:
Kısa vadeli motivasyon değil, küçük bir sistem.
Her gün 20–30 dakika bile olsa devam edebilmek
Hedefi “bitirmek” değil, “temas etmek” olarak koyabilmek
Gelişimi günlük değil, haftalık ölçebilmek
Learning curve’un en kritik tarafı şu:
Bırakma isteği geldiği an, çoğu zaman doğru yolda olduğunuz andır.
💢 6 Şubat’ta Kahramanmaraş merkezli olarak meydana gelen depremler, 11 ilimizi derinden etkilemiş ve hafızalarımızdan silinmeyecek yaralar açmıştır.
🕊️ AFAD’ın yaptığı resmî açıklamalara göre bu büyük depremlerde yaklaşık 50.096 vatandaşımız hayatını kaybetmiş, 107.204 vatandaşımız ise yaralanmıştır.
💭 Yaşananları unutmak mümkün değil. Ancak unutmamamız gereken başka bir gerçek daha var: Afetler, hayatın olağan bir parçasıdır. Önemli olan afetlere rağmen değil, afetlerle yaşamayı öğrenmek; gerekli önlemleri alarak olası riskleri en az hasarla atlatabilecek bir bilinç geliştirmektir.
🦾 Bizlere düşen sorumluluk; hazırlıklı olmak, bilgiyi güçlendirmek ve toplumsal dayanışmayı sürekli kılmaktır.
💫 Afet Yönetim Sistemi olarak amacımız; afetlere karşı daha dirençli, daha donanımlı ve daha duyarlı bir toplum oluşturmak, gelecekte benzer acıların önüne geçebilmek adına çalışmalarımıza kararlılıkla devam etmektir. Çünkü afet bilinci yalnızca kriz anlarında değil, her zaman güçlendirilmesi gereken bir sorumluluktur.
Unutmayalım:
🔹 Afete hazırlık hayat kurtarır.
🔹 Toplumsal dayanışma, kayıpların ardından en güçlü umudumuzdur.
🔹 Bilgi ve bilinç, geleceğimizi güvence altına alır.
🙏 Hayatını kaybeden vatandaşlarımızı saygı ve rahmetle anıyor, geride kalanlara sabır ve güç diliyoruz.
#6şubatdepremi #6şubat2023 #deprem#deprem2023#unutmadık #unutmayacağız #afetbilinci#afetehazırlık #depremdayanışması #toplumsaldayanışma #afetyonetimsistemi#ays
Klasik pipeline süreçlerinde akış çoğu zaman repo’nun dışında kurgulanıyor. Kod ile pipeline ise ayrı olarak yönetiliyor. Bir şey ters gittiğinde de "Burada ne değişti?" diye soruyoruz. Peki olması gereken bu mu?
GitHub Actions burada yaklaşımı değiştiriyor. Çünkü pipeline artık repo’nun içinde, kodla birlikte duruyor: .github/workflows. Yani pipeline değişikliği de kod gibi PR’dan geçebiliyor; diff görülüyor, review ediliyor, gerekirse geri alınabiliyor.
Bunun pratik artıları şunlar:
- “Deploy nasıl yapılıyor?” cevabı repo’nun içinde kalıyor.
- Pipeline değişikliği gizli bir arayüz ayarı olmuyor, herkes görüyor.
- PR, tag, release, schedule, manuel çalıştırma gibi akışlar doğal hale geliyor.
- Reusable workflow’larla ekip standardı proje proje kopyalamadan yayılabiliyor.
- Hazır action’lar sayesinde birçok iş sıfırdan script yazmadan kurulabiliyor.
Özetle, GitHub Actions klasik pipeline araçlarına göre süreci daha “repo merkezli” hale getiriyor. Pipeline konfigürasyonu ayrı bir sistemde kaybolmak yerine kodla birlikte yaşadığı için değişiklikler daha görünür oluyor, PR üzerinden daha kolay denetleniyor ve standartları projelere yaymak daha az efor istiyor. Bu da pipeline’ı yönetmeyi zorlaştırmak yerine, zamanla daha sürdürülebilir hale getiriyor.
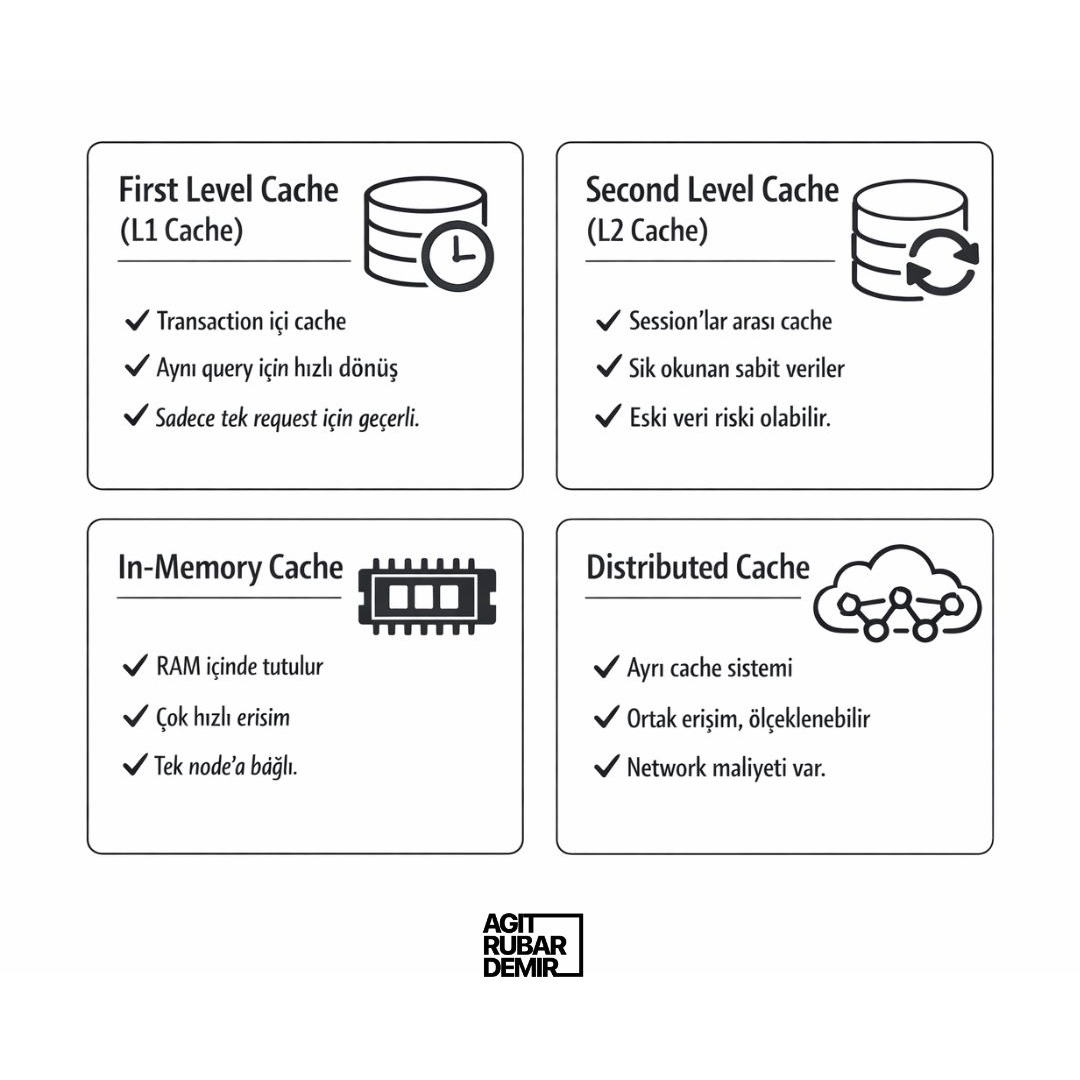
Cache konuşurken çoğu zaman niyet net oluyor: daha hızlı cevap dönmek.
Ama kritik soru şu: Hangi türde bir cache yapısına ihtiyacımız var?
Çünkü cache dediğimiz şey tek bir katman değil. Aynı sistemde birden fazla cache seviyesi birlikte çalışabiliyor ve yanlış seçim yapıldığında hız kazanmak yerine tutarsızlık, fazladan yük ve beklenmeyen bug’lar çıkabiliyor.
Ben bu konuyu seçilebilir hale getirmek için şöyle ayırıyorum:
𝗙𝗶𝗿𝘀𝘁 𝗟𝗲𝘃𝗲𝗹 𝗖𝗮𝗰𝗵𝗲 (𝗟𝟭 𝗖𝗮𝗰𝗵𝗲)
Hibernate/JPA’nın default cache’idir. Aynı transaction içinde aynı entity tekrar okunursa DB’ye gitmeden dönebilir.
✅ Aynı transaction içinde tekrar okuma varsa veya amaç “tek request içinde DB çağrısını azaltmak” ise yeterli olur.
⚠️ Bu cache request dışına taşmaz. Yani sistem genelinde hızlandırma bekleyemeyiz.
𝗦𝗲𝗰𝗼𝗻𝗱 𝗟𝗲𝘃𝗲𝗹 𝗖𝗮𝗰𝗵𝗲 (𝗟𝟮 𝗖𝗮𝗰𝗵𝗲)
Hibernate tarafında session’lar arası çalışabilen cache katmanıdır. Aynı entity farklı request’lerde tekrar okunuyorsa DB yükünü azaltabilir.
✅ Veri sık okunuyor ama nadiren değişiyorsa (ör. referans tablolar, sabit ayarlar) anlamlı olur.
⚠️ Cache invalidation iyi yönetilmezse eski veri görme riski oluşabilir.
𝗜𝗻-𝗠𝗲𝗺𝗼𝗿𝘆 𝗖𝗮𝗰𝗵𝗲
Veri doğrudan uygulamanın RAM’inde tutulur. Network maliyeti olmadığı için en hızlı cache türlerinden biridir.
✅ Tek instance çalışan sistemlerde veya kısa süreli hot data için hızlı sonuç verir.
⚠️ Uygulama restart olunca cache sıfırlanır. Birden fazla instance varsa herkes kendi cache’ini tutar ve veri parçalanabilir.
𝗗𝗶𝘀𝘁𝗿𝗶𝗯𝘂𝘁𝗲𝗱 𝗖𝗮𝗰𝗵𝗲
Redis gibi ayrı bir cache sistemi kullanılır. Birden fazla instance aynı cache’i paylaşabilir, ölçeklenebilir bir yapı sağlar.
✅ Birden fazla servis/instance aynı veriyi paylaşacaksa veya cache’in uygulama restart’ından etkilenmemesi isteniyorsa doğru tercihtir.
⚠️ TTL, eviction, serialization ve network gecikmesi gibi detaylar devreye girer. Yani operasyonel maliyet daha yüksektir.
Kısacası cache seçimi tek bir şeye dayanır:
Biz neyi çözmeye çalışıyoruz? Performans mı, ölçek mi, yoksa veri tutarlılığı mı?
Bu ayrımı net yaptığımızda “cache ekleyelim” demek yerine şunu diyebiliriz:
“Biz burada şu tür cache’e ihtiyaç duyuyoruz.”
2025 yılı değerlendirme toplantımızı gerçekleştirdik 📈
Neleri iyi yaptığımızı, neleri daha iyi yapabileceğimizi ve önümüzdeki yılın hedeflerini hem teknik hem de iletişimsel açıdan birlikte konuştuk.
Bu buluşma, büyüyen ekibimizle ortak bir yol haritası oluşturmak açısından bizim için çok değerliydi.
Zaman ayırıp fikirlerini paylaşan tüm ekip arkadaşlarımıza teşekkürler ✨
#AfetYönetimSistemi #AYS#AçıkKaynak #Dayanışma #YeniYılHedefleri #YolHaritası
Haftalık toplantımızı gerçekleştirdik. 🎯
Her hafta olduğu gibi bu hafta da üzerinde çalıştığımız görevleri gözden geçirdik, yapılan geliştirmeleri paylaştık ve karşılaştığımız sorunlara birlikte çözüm ürettik.
Gelecek toplantılarda görüşmek üzere 🙌
Bir değişkenin değerini ilk ihtiyaç olunan anda tanımlayıp, daha sonra dokunmamak istiyorsak, ilk bakışta “final yeterli değil mi?” diye düşünebiliyoruz.
Fakat Java 25’te bu konuyla ilgili ilginç bir feature var.
final ile Stable Values (JEP 502 – preview) arasındaki farkı en net şekilde şöyle düşünebilirsiniz:
final ne sağlar?
- Değer tam olarak bir kez atanır.
- Atama genelde constructor’da veya static init sırasında olur.
- Sonrasında değişmez.
- JVM/JIT optimizasyonları için güçlü bir sinyal verir.
Ama: Değeri geç atamak istediğimizde final ile mümkün olmaz. Yani değer hazır değilse bile o anda atamak zorunda kalırız.
Stable Values (JEP 502 – preview) ne hedefler?
- Değer sonradan (ilk ihtiyaç anında) atanabilir.
- Yine de yalnızca bir kez atanması hedeflenir.
- Atandıktan sonra sabit kalır (değişmez).
- JVM’in bunu final gibi görebilmesi ve optimizasyon yapabilmesi hedeflenir.
Ne zaman hangisi?
- Değer baştan belliyse: final
- Değer başta belli değil ama bir kere belirlendikten sonra sabit kalmalıysa: Stable Values (JEP 502 – preview)
⚠️ Preview ne demek ve neden önemli?
- Preview, özelliğin nihai olmadığını gösterir: API/davranış sürümden sürüme değişebilir.
- Production ortamda kullanmak isterseniz, genelde preview flag/enable ile derleme/çalıştırma gerektirir.
- Yani bugün yazdığınız kod, sonraki Java sürümünde küçük uyarlama isteyebilir.
Geliştirdiğiniz projelerde bir gün tek bir entegrasyon değişikliğinin beklediğinizden çok daha fazla yeri etkilediğini fark etmiş ya da “sadece küçük bir değişiklik” diye başlayıp, bütün projeyi refactor etmeye başladığımızı ve sürecin uzadığı durumlarla karşılaşmışsınızdır.
Bu tür durumlarda farkında olmasak da, Program to Interface, Not an Implementation yaklaşımı üzerine daha çok düşünmemizi gerektiriyor.
Kodunuz implementasyona bağımlı kaldığında değişiklikler hızla her yere yayılabilir; interface üzerinden kurgulandığında ise değişim daha dar bir alanda kalır ve uzun vadede sürdürülebilirlik sağlar.
Interface/implementation farkını, bu yaklaşımın ortaya çıktığı dönemi ve motivasyonunu (değişimin yayılmasını sınırlama, bağımlılık yönetimi) ve tasarım prensipleri + pattern düşüncesi çerçevesini temel alarak, basit bir PaymentGateway örneğiyle anlattığım Medium makaleme göz atabilirsiniz 👀
🔗 @agitrubard/program-to-interface-not-an-implementation-peki-neden-6073c1b46c1b" target="_blank" rel="nofollow noopener">medium.com/@agitrubard/pr…
Makaleyi faydalı bulduysanız paylaşarak daha fazla kişiye ulaşmasını sağlayabilirsiniz 🙌🏼
Bu konuyla ilgili varsa deneyimleriniz veya sorularınız postun altına yorum bırakabilirsiniz 💬
⚠️ Spring’de REST client yazmak uzun zamandır gereğinden fazla karmaşık bir deneyimdi. RestTemplate eskidi, WebClient güçlü ama her zaman sade değil. Kod çoğu zaman gereksiz konfigürasyon ve yardımcı sınıflarla şişiyordu.
✅ Spring Boot 4.0 ile gelen HTTP Interfaces tam olarak bu karmaşayı toparlayan bir model sunuyor: Daha az kod, daha yüksek okunabilirlik ve daha doğal bir REST client deneyimi.
HTTP Interfaces neleri değiştiriyor?
- REST çağrılarını Java interface seviyesinde tanımlıyorsunuz; Spring gerisini sizin için oluşturuyor.
- Ekstra helper sınıfları, config bean’leri veya boilerplate yapılar büyük ölçüde ortadan kalkıyor.
- WebClient’in altyapısını kullanarak, reaktif olmasa bile modern ve temiz bir API elde ediyorsunuz.
- Test yazmak daha kolay hale geliyor; mock client üretmek çok daha doğal bir akışa oturuyor.
- Üçüncü parti servislerle entegrasyonlarda kodun niyeti çok daha anlaşılır oluyor.
Spring Boot 4.0 ile REST client yazmak nihayet sade, derli toplu ve modern bir yapıya kavuşuyor 🎯
⚠️ Jackson 2, uzun yıllardır Java ekosisteminin bel kemiğiydi ama modern Java’nın hızına yetişemiyordu.
✅ Jackson 3 ise Java’nın son yıllardaki yönüne daha yakın bir model sunuyor: sade, hızlı, güvenli. JSON dönüşümlerini daha hızlı, daha güvenli ve daha modern Java ile uyumlu hale getiriyor.
Jackson 3 neleri değiştiriyor?
- Serialization/deserialization süresi kısalıyor, GC üzerindeki yük azalıyor. Özellikle büyük JSON objelerinde fark hissedilir düzeyde.
- Eski karmaşık yapıların çoğu temizlenmiş durumda. Daha tutarlı, daha anlaşılır bir konfigürasyon modeli geliyor.
- Java17+ ile gelen records, sealed classes, pattern matching gibi özelliklerle çok daha doğal çalışıyor.
- Polymorphic deserialization varsayılan ayarları daha güvenli, riskli kullanım alanları minimize edilmiş durumda.
- Konfigürasyon ve modül etkileşimleri daha temiz; “neden böyle davrandı?” soruları azalıyor.
Spring Boot 4.0 ile birlikte Jackson 3 desteği resmi olarak geldi. Spring Boot 4.0’ın Jackson 3’ü varsayılan hâle getirmesi de önemli. Ekosistem artık tamamen modern Java dönemine geçiyor 🚀
Spring'de aynı işi farklı konfigürasyonlarla tekrar tekrar mı yazıyorsunuz? Her tenant için ayrı bean yaratınca IoC container’daki bean sayısı artıyor mu?
🍃Spring Framework 7 + Spring Boot 4.0 buna çok temiz bir model getiriyor: Programmatic (Dynamic) Bean Registration. Bu yöntem ile ihtiyaç duyulan bean’ler tam o anda kodla dinamik olarak, ek anotasyon tanımlarına gerek kalmadan eklenebilir.
- Koşullu kayıt: Belirli bir property açık olduğunda ilgili bean de konteynıra eklenebilir.
- Listeye göre üretim: Örneğin 3 tenant bulunduğunda 3 servis, 20 müşteri tanımlandığında 20 client bean’i aynı kod bloğu içinde üretilebilir; bu işlem döngüyle gerçekleştirilebilir.
- Merkezi kontrol: Bean’in nerede oluşturulduğu ve hangi parametrelerle üretildiği tek bir yerden yönetilebilir.
- AOT / native uyumu: Üretilen bean’lerin Spring’e açıkça bildirilmesiyle AOT / native senaryoları daha öngörülebilir hâle gelir.
Basit senaryo:
Uygulamanın konfigürasyonlarında tenants = ["tr", "eu"] yazıyorsa, uygulama açılırken bu iki tenant için de otomatik olarak ReportService bean’i oluşturulabilir. Bean’lerin adları da buna göre reportService-tr ve reportService-eu olarak verilebilir. Böylece IoC Container'da iki servis de hazır olur ve kod içinde “tr için olanı getir" veya "eu için olanı getir” diye çağrılabilir.
✅ Doğru Kullanım Senaryolarındaki Avantajlar:
- Yeni müşteri eklendiğinde uygulamanın yeniden paketlenmesi/release edilmesi gerekmeyebilir.
- Multi-tenant, plugin veya feature-flag tabanlı mimariler daha sade bir yapıya kavuşabilir.
- Kod okunurluğu artar; hangi bean’lerin koşula bağlı olduğu doğrudan görülebilir.
- Java tarafındaki akış, koşula bakılarak bean’in gerektiğinde eklenebileceği esnek bir modele dönüşür.
⚠️ Yanlış Kullanım Senaryolarındaki Dezavantajlar:
- Uygulamada “bu bean nerede kaydoldu?” sorusu artar, izlenebilirlik düşer.
- Gereğinden fazla dinamik kayıt yapıldığında config karmaşık ve okunması zor hâle gelir.
- Hangi koşulda hangi bean’in oluştuğu belirsizleştiği için test senaryoları kabarır.
- Bean’ler arasında bağımlılık varsa, yanlış kayıt sırası runtime hatalarına yol açabilir.
- AOT / native derlemelerde eksik bildirim yüzünden “bean bulunamadı” tipinde hatalar görülebilir.
- Farklı ortamlarda (test/production) farklı bean setleri oluşacağı için davranışı öngörmek zorlaşır.