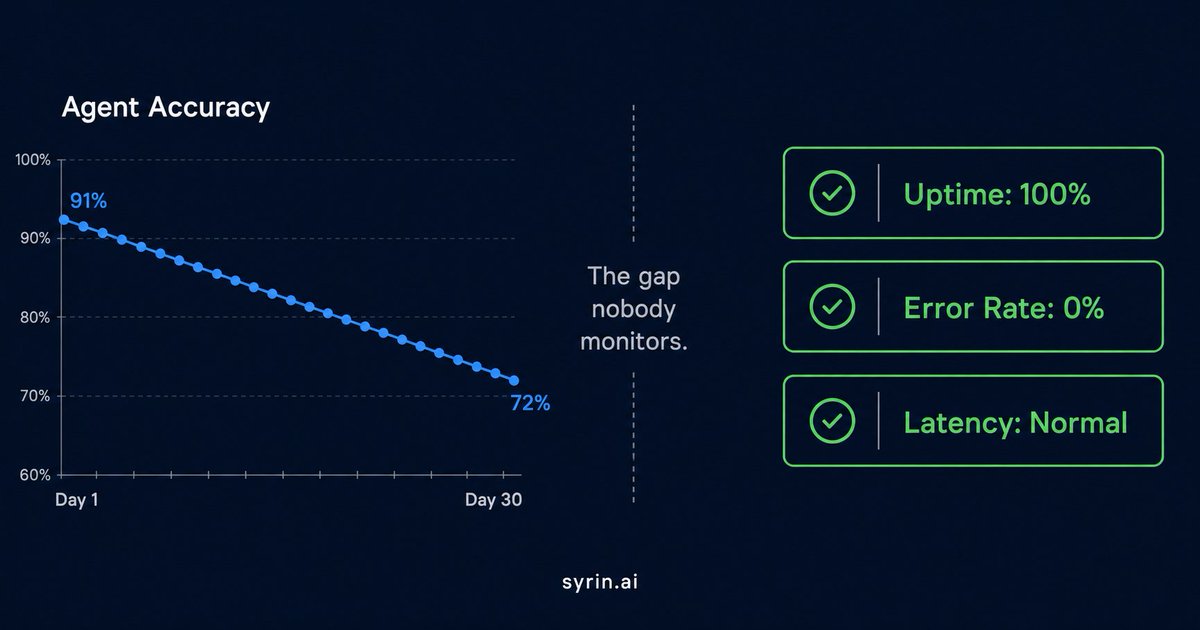
So when something breaks in production, there's no control group.
No variable isolation. Just a list of suspects and a deadline.
Web teams solved this 15 years ago with A/B testing. Agent teams are still guessing.
#buildinpublic #aiagents #agentengineering
English