Sabitlenmiş Tweet

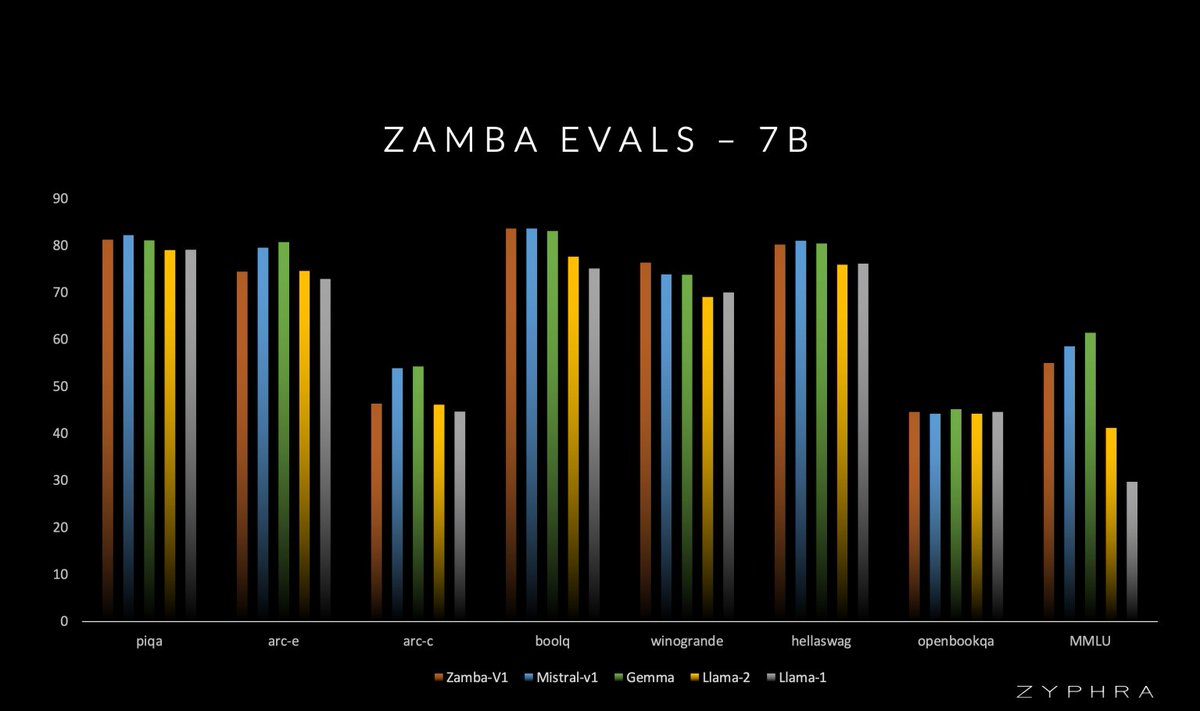
Our tech report for Zamba-7B-v1 is out. We manage to come close to Llama 3 8B, Mistral 7B and others' level of performance, with only 1T tokens, with faster inference and less memory usage at a fixed context length. Read up to learn about our not-so-secret sauce!
Quentin Anthony@QuentinAnthon15
Zyphra is dropping the tech report for Zamba-7B, along with: - Model weights (phase 1 and final annealed) at huggingface.co/Zyphra - Inference/generation code (both pure PyTorch and HuggingFace) at github.com/Zyphra/Zamba-t… and github.com/huggingface/tr… Tech report: arxiv.org/abs/2405.16712 Intermediate checkpoints and improved phase 1 dataset (+dataset paper!) coming soon. Intermediate optimizer states available on request. Some highlights:
English