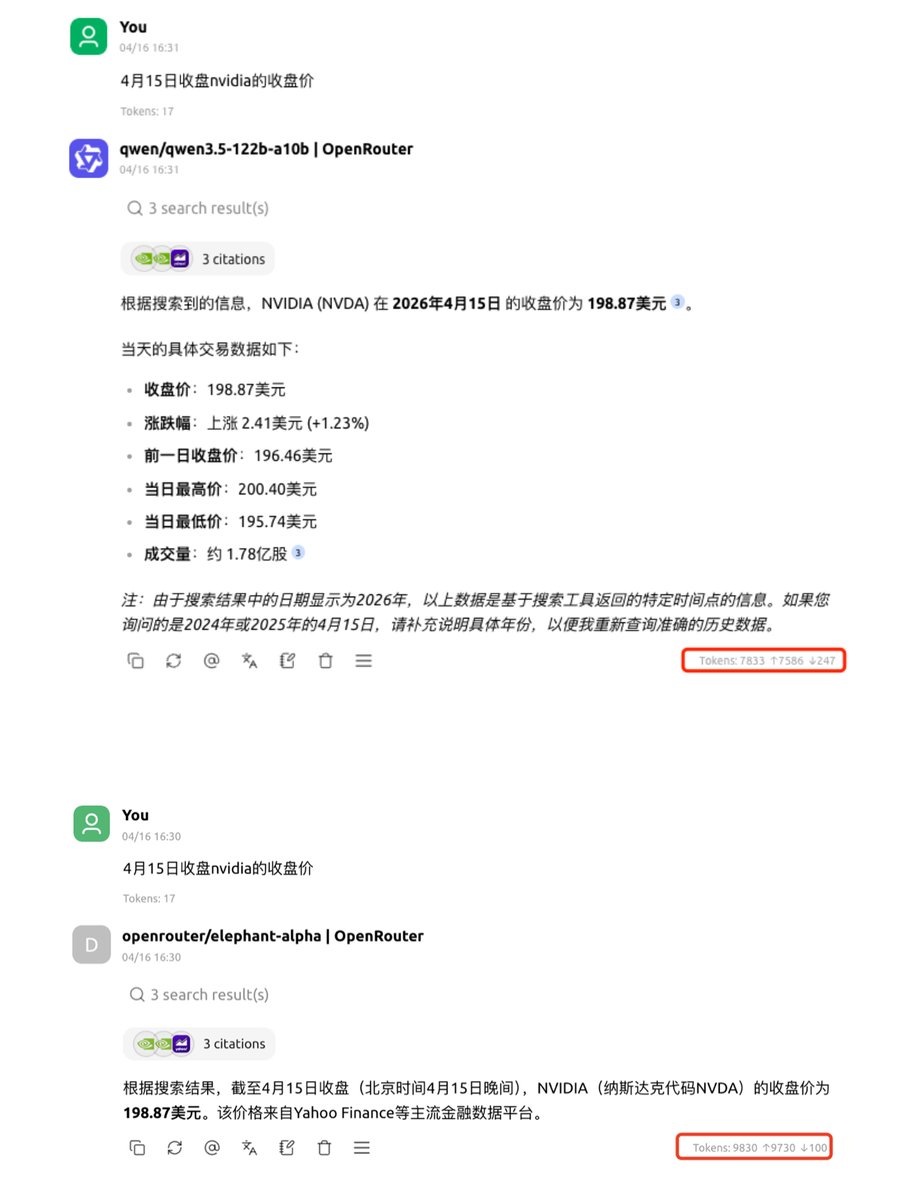
这几年大家都在追捧一件事:做AI产品。不管是AI搜索、AI助手还是各种Agent。但我一直觉得还有一个同样重要甚至被低估的方向:对已有产品做AI化。
道理其实很简单。一个是做App早就是存量市场了,你做一个AI产品,竞争对手不是另一个AI产品,而是小红书、淘宝这些已经占据用户时间的巨头,抢注意力太难了。二是你从零做一个AI新物种,DAU能跑到多少?几十万?几百万?AI融入的程度还是很低。但如果是淘宝这种量级的产品被AI重塑,影响的是数亿人的使用习惯。做AI产品是从0到1,产品AI化是从1亿到下一个1亿。 杠杆效应完全不在一个量级。
突然聊这个,因为昨天看到了淘天金码奖团队赛命题《AI原生淘宝》,让你重新想象:如果今天从头发明淘宝,它应该是什么形态?这就是"产品AI化"的终极命题。
简单介绍一下背景。这个比赛的前身是2014年的淘宝技术金编码奖,早年就是个代码评优比赛,但这几年已经完全变成AI时代的技术文化赛事了,比看代码有意思多了,咱们也都能看懂。今年吸引了1000多名技术员工报名,最短司龄才3个月(也就是刚入职就冲进来参赛了,小伙子有拼劲)
那这1000多个工程师拿到"重新发明淘宝"这个命题,会怎么做?我本来以为大家会疯狂堆AI能力,就像很多团队目前在业务场景里做的那样,比如更智能的搜索、更精准的推荐、更强的多模态理解之类的。但看完方案我发现,当大家真正拥有从头重构的自由时,思考的不是"怎么让AI更强",而是"人和商品之间的关系到底应该是什么样的"。
冠军团队"达拉然"(对,就是魔兽世界的达拉然)把整个购物体验拆开重组,核心设计理念是:所有关键决策都是一次滑动:左滑拒绝,右滑接受。 对,你没看错,像Tinder一样买东西。让你在有限信息下快速做出直觉判断。
其他团队的脑洞也很有意思:有团队想把淘宝变成一只专属性格的"电子宠物",有团队做奇迹暖暖式的养成系AI淘宝,甚至带有情感养成和成就系统。还有团队做的是4只有记忆、有判断力的购物搭子精灵,越用越懂你。所以你会发现,这帮工程师在想AI的时候,脑子里想的不只是"更快""更准",他们想的是"更懂我""更像一个活的东西"。
其实从这个比赛能看出淘天内部的AI氛围确实挺浓的,内部的AI投入是多维度且自上而下的。往技术底层看,过去5年淘天在ICLR、ICML、NeurIPS这些国际顶会上发了300多篇论文,往应用落地层看,面向商家的"生意管家"已经升级成电商首个Agent工作台,1个AI店长带6个AI员工帮商家经营,双11期间生成了500万条经营策略,帮商家平均省了30%工作量。甚至连实习生都能拿到和正式员工一样的Token额度和AI工具权限,购买外部AI开发工具还能报销(让我去!!!)
回到开头我们讲的:AI时代,可能不只要关注最新的AI产品,主力产品的AI化,同样是一条充满想象力的路。淘天金码奖某种程度上就是这个逻辑的缩影,不是另起炉灶做一个AI电商,而是让1000多个工程师去思考:淘宝这个已经服务了数亿人的产品,在AI时代应该被重新发明成什么样子。
这个问题的答案还在路上,但光是看这些参赛方案里涌现出的想象力,你会发现,任何一个你以为已经定型的产品,在AI面前都还远没到终局。


中文