Sabitlenmiş Tweet
Anusha K
1.1K posts


Anusha K
@aiwithanu
ML enthusiast || Available for work : https://t.co/w3R6kfGiH7 || Learning ML to build @mayumiai_hq, @Metagpt_ ambassador, recipient @aigrantsindia
localminima Katılım Eylül 2023
2.3K Takip Edilen215 Takipçiler

@kmeanskaran When is the hiring season at the company you are working at ?
English

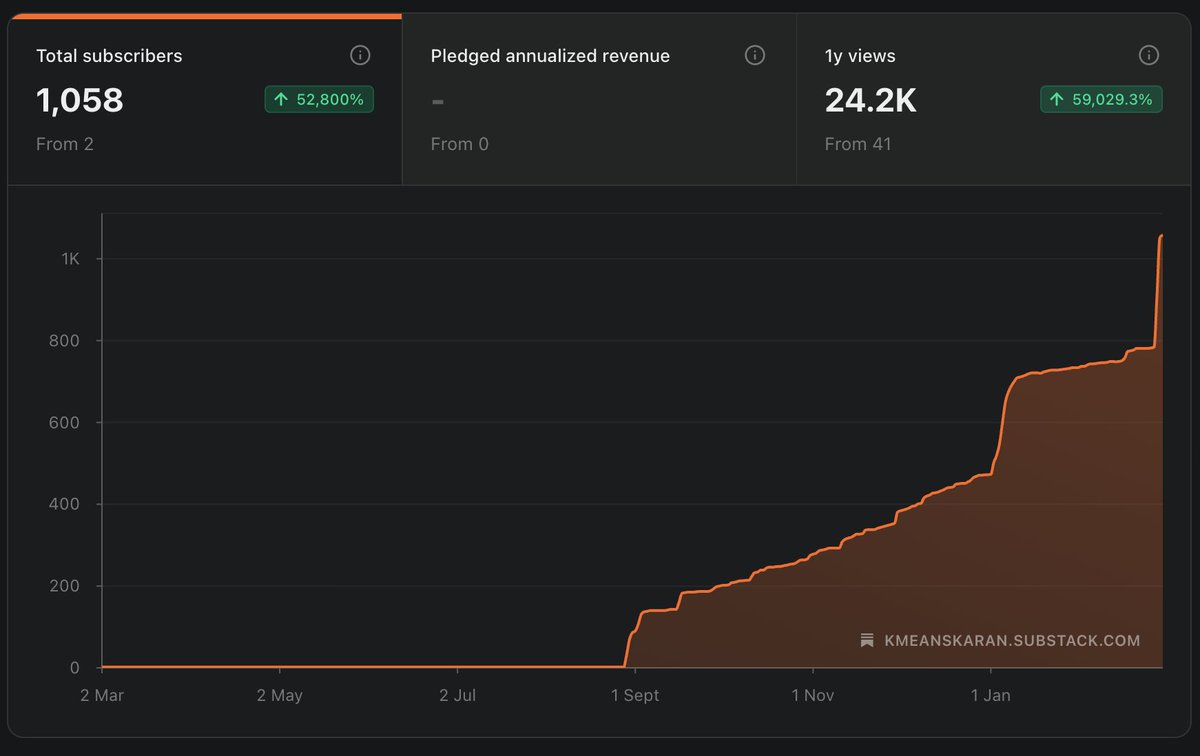
K-MEANS KARAN HAS 1,000+ DATA POINTS 🎉🎉
In Sept 2025, I started my Substack on applied ML and MLOps.
Where I write about how to sharpen your ML skills in real-world work.
Subscribe if you haven't: kmeanskaran.substack.com
Thanks everyone!
Karan,
Your Centroid
English
@rick_pick7430 I remember there are filtering options, see if you can filter by institution
English
@rick_pick7430 Pick a field of ur interest, go to Google scholar or Research gate, and find the email id of the professor who is working in the same field ,and mail them...
English

69/♾
done with PCA, simple linear regression, multiple linear regression, polynomial linear regression, and ridge regression via both closed form solution (OLS) and via gradient descent.
First applied to 2d, then extended to nDim
next is lasso regression.

Anusha K@aiwithanu
68/♾️ Done with multivariate imputation, handling outliers using zscore, iqr proximity, percentile methods, done with (Principle component analysis implementation (without sklearn) + math ) PCA with sklearn is left.
English






@aiwithanu lamao wait till you have to brackprop the entire transformer by hand
English

@aiwithanu they are bit more complex so i just read the results of them
English

68/♾️
Done with multivariate imputation, handling outliers using zscore, iqr proximity, percentile methods, done with (Principle component analysis implementation (without sklearn) + math )
PCA with sklearn is left.




Anusha K@aiwithanu
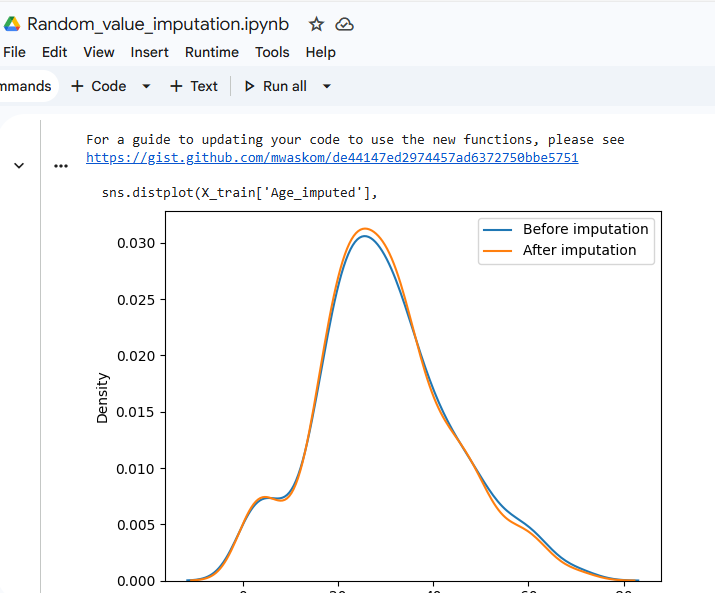
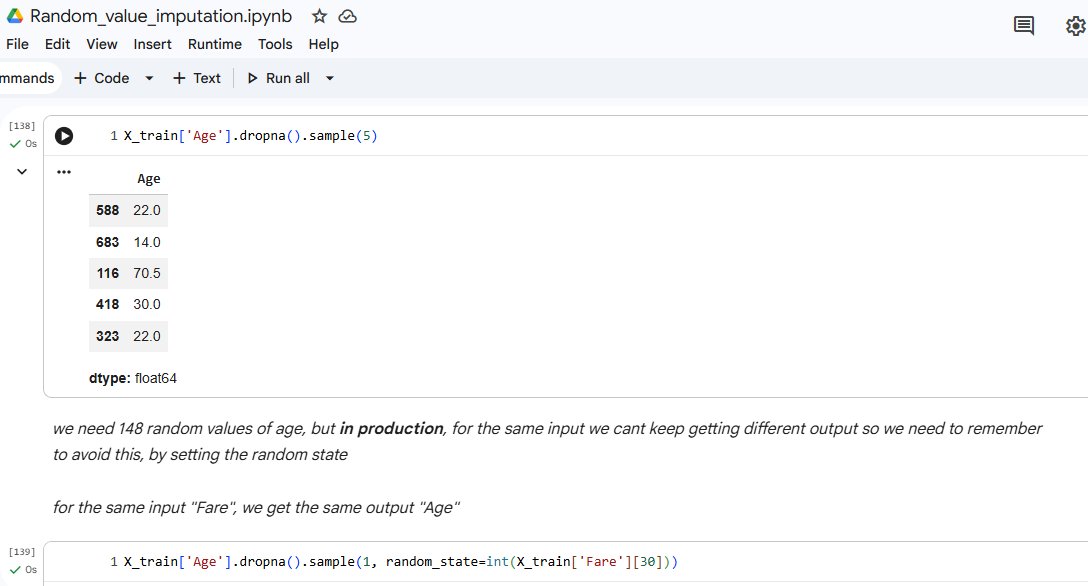
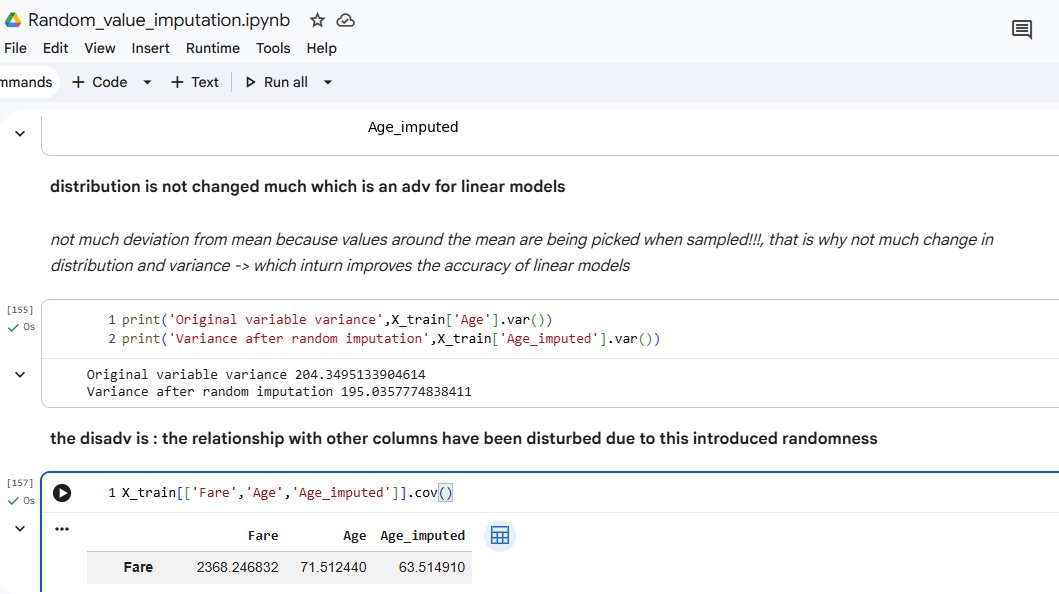
67/♾ Working on univariate imputation for filling missing values . Done with mean/median imputation, arbitrary value imputation, random value imputation.
English
Anusha K retweetledi

We’re officially opening our Bengaluru office—our new home base in India, and Anthropic's second office in Asia-Pacific.
India is our second-largest market for Claude.ai. We’re launching new partnerships to deepen our long-term commitment: anthropic.com/news/bengaluru…
English
67/♾
Working on univariate imputation for filling missing values .
Done with mean/median imputation, arbitrary value imputation, random value imputation.
Anusha K@aiwithanu
66/♾ lambda functions are pretty useful while dealing with mixed variables, where a column has cells with both numerical and categorical data
English
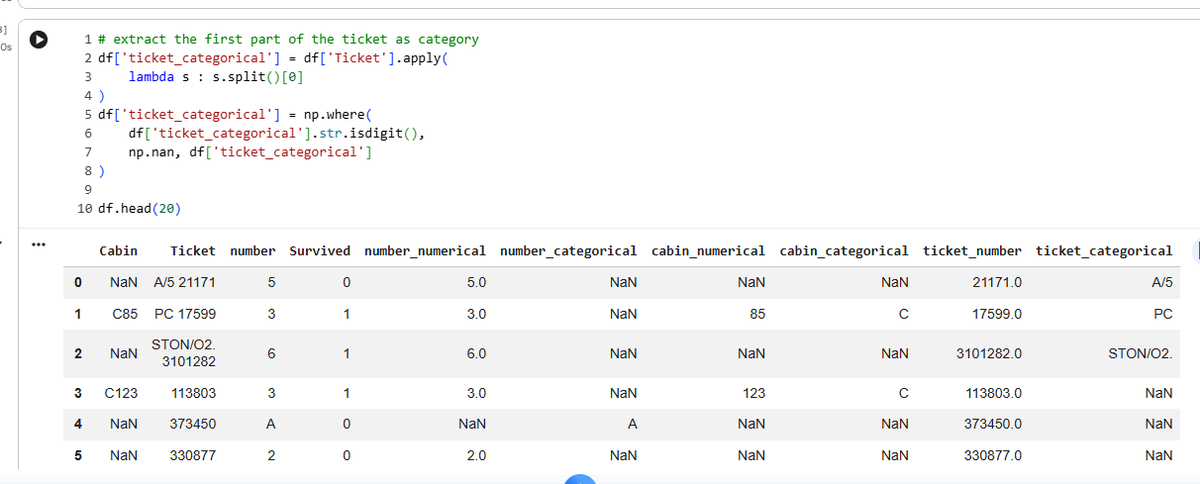
66/♾
lambda functions are pretty useful while dealing with mixed variables, where a column has cells with both numerical and categorical data
Anusha K@aiwithanu
65/♾ To encode numerical data, we use : 1) Binning 2) Binarization Why use it ? To handle outliers better, to improve the value spread (makes spread of data uniform) We use the class KBinsDiscretizer , with encoding as ordinal , strategy : uniform, quantile, kmeans.
English
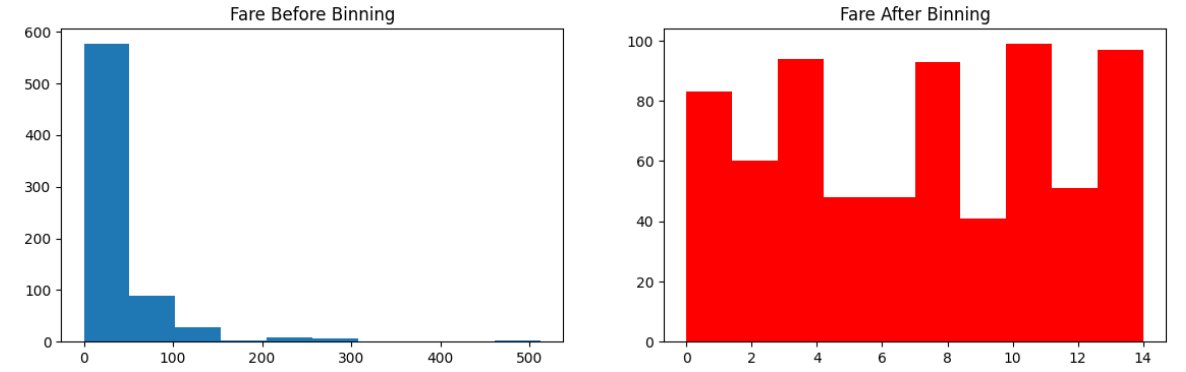
65/♾
To encode numerical data, we use : 1) Binning
2) Binarization
Why use it ?
To handle outliers better, to improve the value spread (makes spread of data uniform)
We use the class KBinsDiscretizer , with encoding as ordinal , strategy : uniform, quantile, kmeans.
Anusha K@aiwithanu
64/♾ We apply box-cox transform (for values strictly greater than 0) and Yeo-johnson transform(for both positive, negative, 0 values). Performance of linear models improves greatly when it has normally distributed data, so we use these to get end output as normal distribution.
English
64/♾
We apply box-cox transform (for values strictly greater than 0) and Yeo-johnson transform(for both positive, negative, 0 values). Performance of linear models improves greatly when it has normally distributed data, so we use these to get end output as normal distribution.

Anusha K@aiwithanu
63/♾ [1/n] : Support Vector Classifier Key Params : C, gamma, kernel C (Regularisation strength) : Low C : allows mistakes, smooth boundary, may underfit High C : forces correctness, complex boundary, may overfit Ex : digits 1 vs 7 Low C -> some 7s look like 1s, that's okay
English