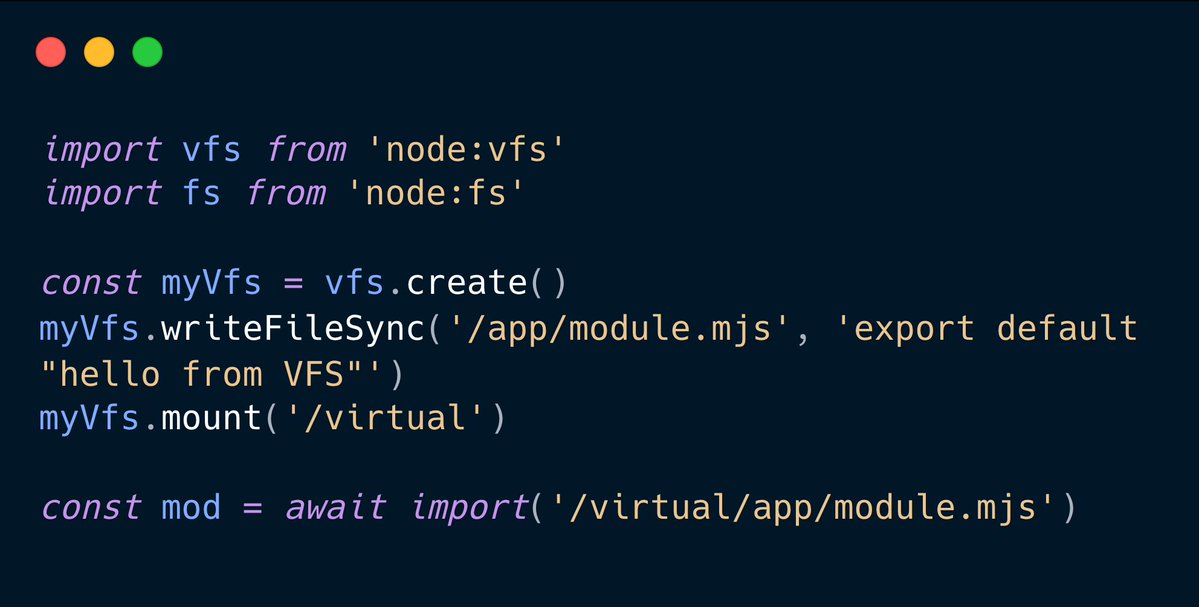
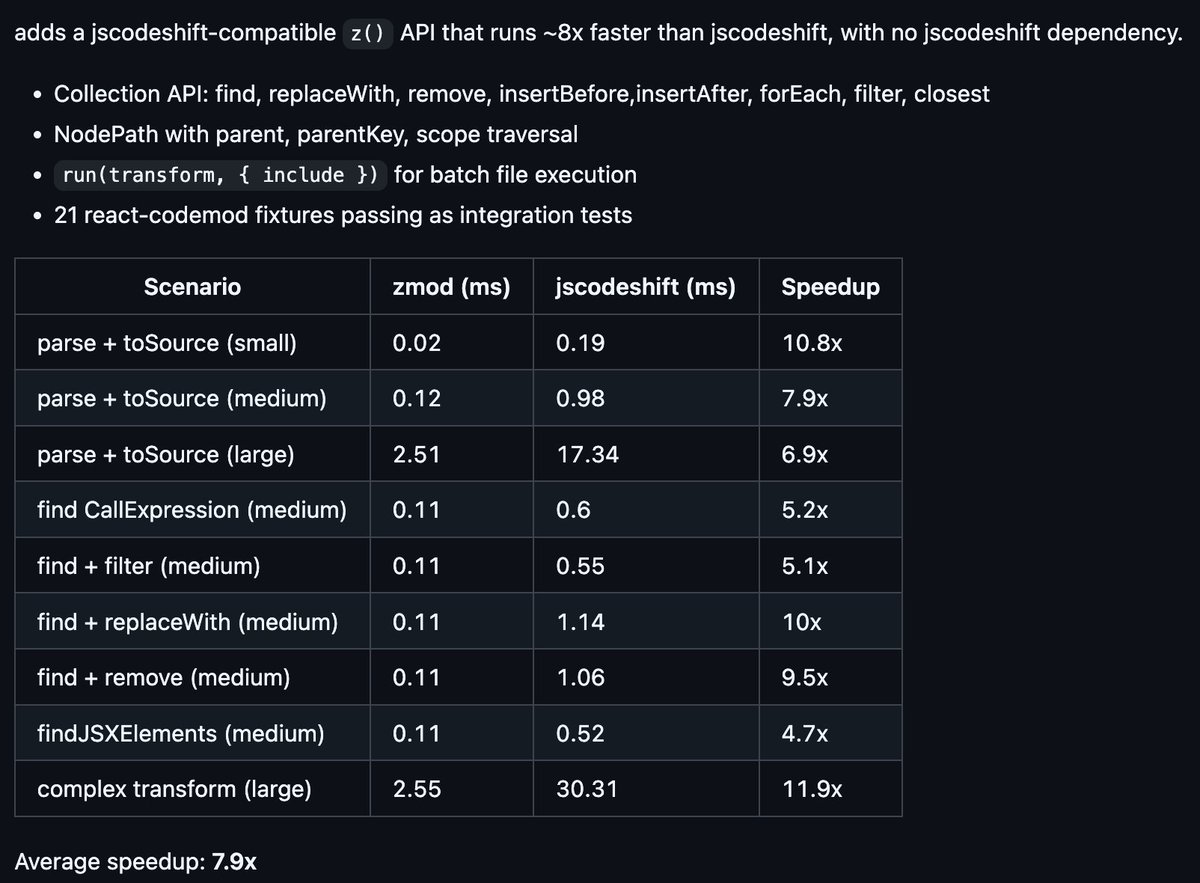
Sabitlenmiş Tweet

Ping me if you need help building codemods. Here are a few pointers:
1. Install Codemod MCP and ask your ai agent to build a jssg codemod: docs.codemod.com/model-context-…
2. Once your codemod is ready, run it locally via CLI: docs.codemod.com/cli
3. Join our community and let me know if you hit a roadblock: go.codemod.com/community
English