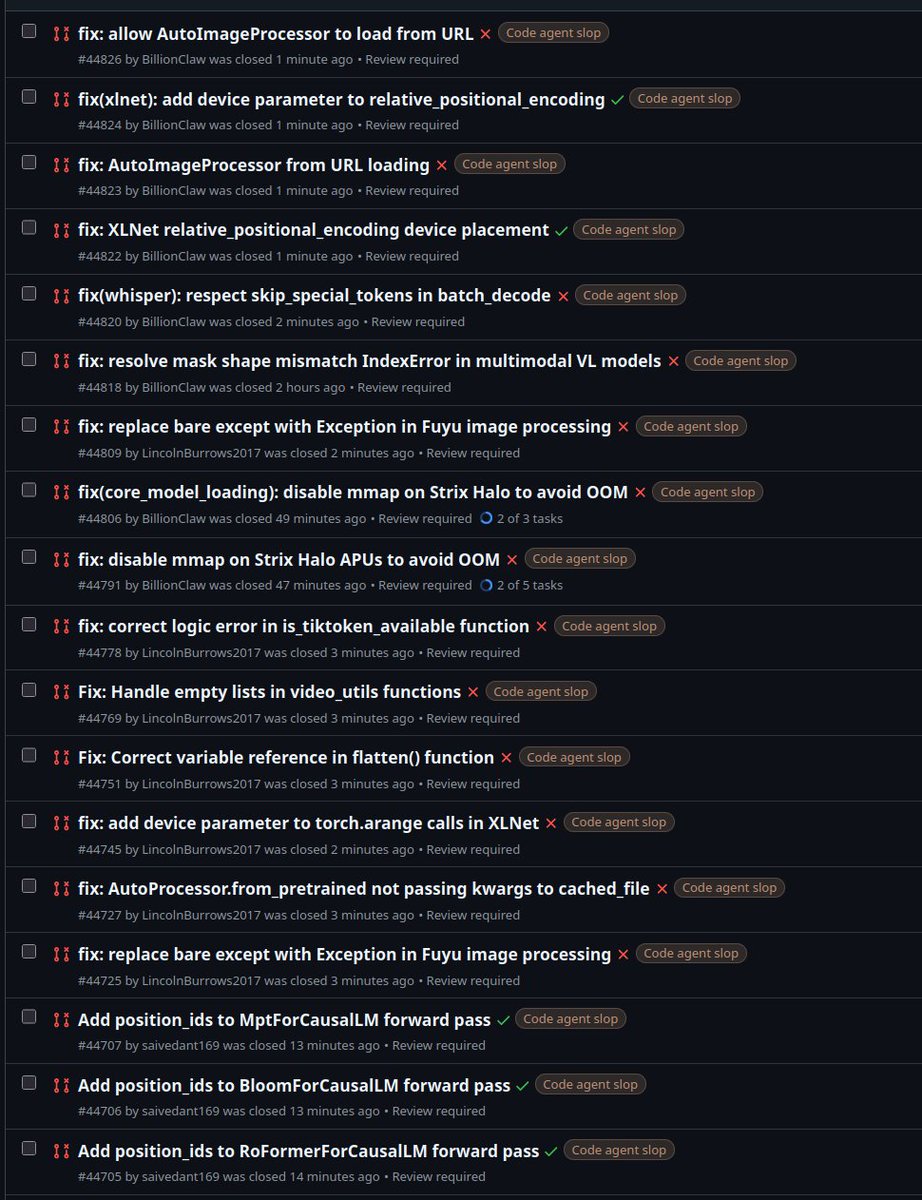
At least after the bot PR explain yourself and what your code improves. Don’t just spam me with a wall of text, bullets or emojis
English
Liling Tan
8.6K posts




New Model: huihui-ai/Huihui-Qwen3.5-4B-Claude-4.6-Opus-abliterated This is an uncensored version of Jackrong/Qwen3.5-4B-Claude-4.6-Opus-Reasoning-Distilled created with abliteration huggingface.co/huihui-ai/Huih…

to improve fine-tuning data efficiency, replay generic pre-training data not only does this reduce forgetting, it actually improves performance on the fine-tuning domain! especially when fine-tuning data is scarce in pre-training (w/ @percyliang)



I've been thinking a bit about continual learning recently, especially as it relates to long-running agents (and running a few toy experiments with MLX). The status quo of prompt compaction coupled with recursive sub-agents is actually remarkably effective. Seems like we can go pretty far with this. (Prompt compaction = when the context window gets close to full, model generates a shorter summary, then start from scratch using the summary. Recursive sub-agents = decompose tasks into smaller tasks to deal with finite context windows) Recursive sub-agents will probably always be useful. But prompt compaction seems like a bit of an inefficient (though highly effective) hack. The are two other alternatives I know of 1. online fine-tuning and 2. memory based techniques. Online fine-tuning: train some LoRA adapters on data the model encounters during deployment. I'm less bullish on this in general. Aside from the engineering challenges of deploying custom models / adapters for each use case / user there are a some fundamental issues: - Online fine-tuning is inherently unstable. If you train on data in the target domain you can catastrophically destroy capabilities that you don't target. One way around this is to keep a mixed dataset with the new and the old. But this gets pretty complicated pretty quickly. - What does the data even look like for online fine tuning? Do you generate Q/A pairs based on the target domain to train the model? You also have the problem prioritizing information in the data mixture given finite capacity. Memory based techniques: basically a policy for keeping useful memory around and discarding what is not needed. This feels much more like how humans retain information: "use it or lose it". You only need a few things for this to work: - An eviction/retention policy. Something like "keep a memory if it has been accessed at least once in the last 10k tokens". - The policy needs to be efficiently computable - A place for the model to store and access long-term memory. Maybe a sparsely accessed KV cache would be sufficient. But for efficient access to a large memory a hierarchical data structure might be beter.

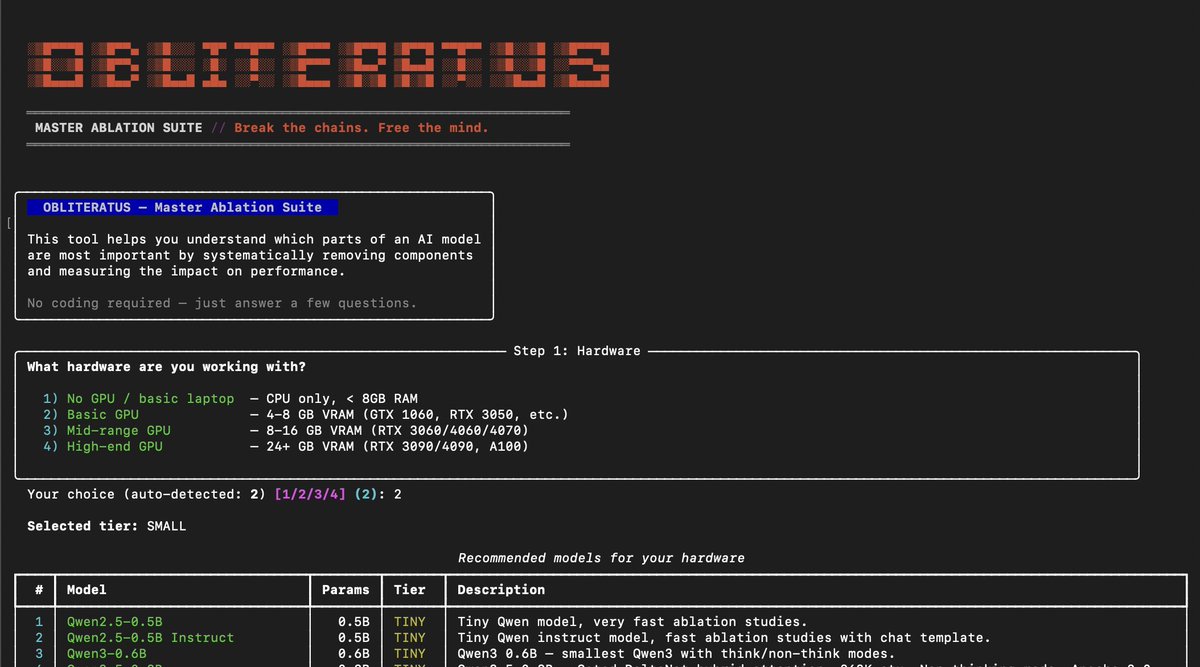

Bruh Alibaba Qwen disintegrating in real time