
redfox🛡️🛰️
352 posts

난 정말 댓글 하나하나 다 읽어보고 직접 하트 다 눌러주고 재게시도하고, 댓글도 씀.
첨부한 영상은 원래 30분짜리임. 방해금지 걸어놓고 30분 동안 꼼짝않고 다 읽어봄.
댓글이 글쓴이에게 힘이 된다는건 그냥 하는 소리가 아님. 반응이 있어야 글쓸맛도 나는거임.
Katoo@blazingbees
X에 올린 머니플로우 조회수 1.5만에 좋아요 237개, 댓글 35개 토스에 올린 머니플로우 조회수 1만도 안되는데 좋아요 226개, 댓글 78개. 난 여태까지 X가 내 본진이라고 생각했었는데 ㅋㅋ 댓글과 좋아요 화력 차이가 이렇게 나는건 좀 실망스럽네 ㅋㅋ
한국어

@becomingEnadam 아니 우리아이가 조금 낯을가리는데 의사선생님이 되어서 그것도 못받아들이시나요? 선생님은 의사시자나요...이런말 안드리려고 했는데 애 아빠가 화가 많이났어요...
그리고 저 맘까페 운영자라 이렇게 하시면 안좋으실텐데요..
한국어

redfox🛡️🛰️ retweetledi

Next Phase: Privacy AI
Privacy is the trillion-dollar gate to enterprise AI.
We are kicking it open with full agent-inference auditability, already live with the UAE government.
End-to-end encryption ships next.
Batch 2 of the invite-only Beta rolling out now, hundreds on the waitlist.
From here, it compounds.
Public API. Private inference for enterprises and governments. Then our own SERV-native models.
Full stack below.
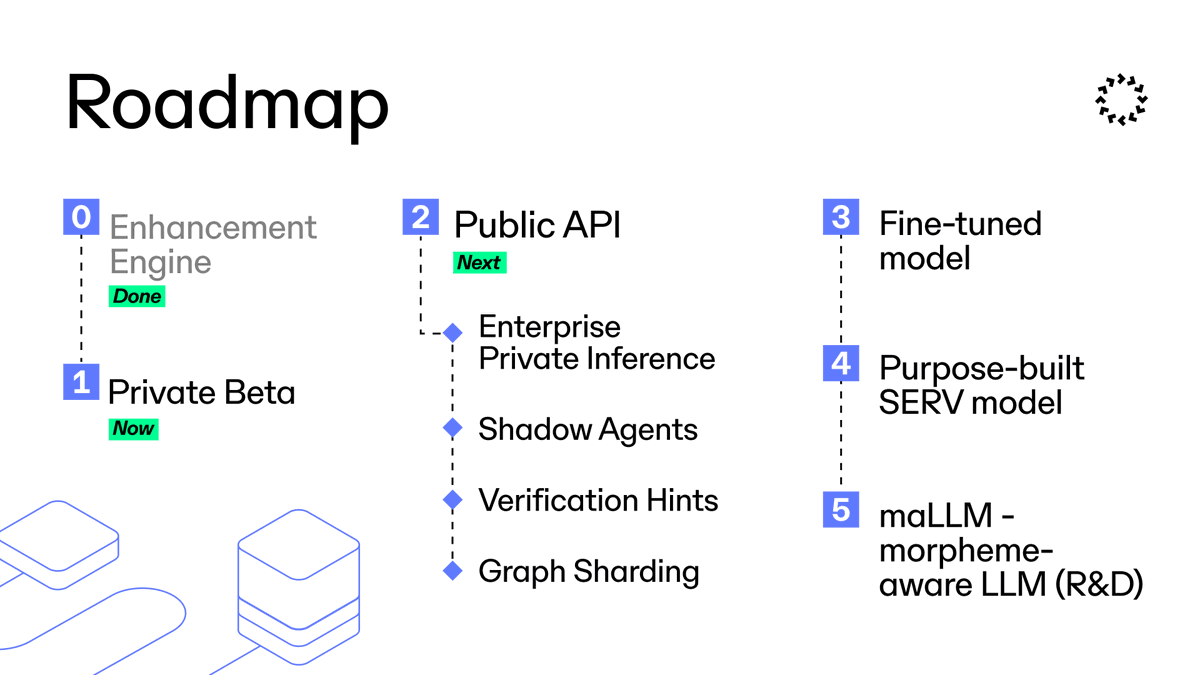
SERV Reasoning ROADMAP:
P0: Enhancement Engine (done)
P1: Private Beta (now)
P2: Public API (next)
2.1 Enterprise Private Inference (TEE + E2EE)
2.2 Shadow Agents
2.3 Verification Hints
2.4 Graph Sharding
P3: SERV-native fine-tuned models
P4: Purpose-built SERV model from scratch
P5: maLLM - morpheme-aware LLM (R&D)
Detailed article coming.
English

redfox🛡️🛰️ retweetledi

#satl
누가 제 매형의 소금 목표 주가
물어보셔서 적어봅니다.
제가 처음 satl 투자 망설일때(그때만해도 제눈에는 개잡주였습니다. 지금도 뭐..ㅋㅋ)
매형이
"ㅇㅇ아, 나 이거 100% 200% 먹으려고 투자한거 아니야"
이렇게 말했거든요.
최소 10배 더는 20-30배까지 보신다고 하셨고.(처음에 너무 터무니 없다 생각함ㅋㅋ)
최소한 플래닛랩스 시총까지 가지 않겠어?
이렇게 말하셨습니다.
플래닛랩스 시총이되면 현재 satl 주가 대비 10배이면 됩니다.
그 사이에 PL시총이 더 커질테니 satl도 더더 커지겠죠.
매형이 극성 테슬람이라고 말한적이 있는데.
이 회사 투자한 이유도 테슬라와
"닮아 있어" 서 였습니다.
"수직통합구조"
위성 설계 → 제조 → 운영 → 데이터 처리까지 대부분을 자체적으로 하는 회사라 외주 비중이 낮고, 위성 1기당 원가를 크게 낮추는 전략을 사용해서 였죠.
매출 총이익률이 67-73%까지도 나오곤 하니까요.
참고로 보통 우주 방산 업체가 20-40%정도 나옵니다.
물론 주가 영역은 꿈의 영역이고
틀릴 수도 있습니다.
우리 모두 테슬라 2000!! 외치는 것과 비슷한거죠.
저도 테슬라 투자하면서
가끔 상상하곤 하거든요. 2000가면 뭐하지ㅋㅋ이렇게
이런 터무니 없는 생각들이 가끔은
폭락을. 오퍼링을 견디게 해줍니다.

한국어


이거 생각보다 어렵지 않습니다.
저는 어떻게 했었냐면..
일단 크롬의 비밀번호 관리자 기록을 모두 주고,
제 행동패턴을 찾으라고 주면 됩니다.
그럼 ID와 PW를 기반으로
앞뒤 숫자를 집어넣는 케이스. 자주 넣는 특수문자.
습관처럼 자주 쓰는 단어들. 패턴등을 기반으로
brute force 계획을 AI에게 짜달라고 하면 됩니다.
제가 이렇게 예전 비번 잃어버린 zip을 풀었습니다.
감자@nowlovepan
와... 미친 11년 잠긴 비트코인 400k 클로드 Ai로 비번 7조 번을 돌리고 복구해버림 대학 때 만취해서 바꿔놓고 11년간 잊어버린 비트코인 비번이 'lol420fuckthePOLICE!*:)' 였대요 ㅋㅋㅋ 옛날 대학 컴퓨터 폴더 통째로 Claude한테 던지니까 지갑 파일 찾아내고 복구 도구 버그까지 고쳐서 풀어냄 "다 줄 테니 알아서 찾아내" goal 쓴건가? 어떻게 했누..
한국어
AI agent 는 분명 사람들 사이에 스며들고 있는듯 보이지만 들여다보자면 아주 소수만 사용하고 있고 그 중 더 일부의 소수만 효율성을 끌어올리는 방법을 만들어가며 사용하고 있다
아직 AI agent 서비스는 극히 제한적으로 나오고 있는데
@openservai 를 가입해 사용해보면 확실히 독특하고 편리하다
다만 UI가 친화적이라고 보긴 어렵고 기반 지식이 조금은 있어야하는데
이런 부분까지 개선되는 시점이 너도 나도 $SERV 를 통한 개인화된 맞춤형 agent를 필요할 때마다 커스터마이징으로 생성하는 시점이지 않을까 싶다
로컬로 사용하는 전문가들이 아닌 일반인의 접근성이 상당히 편해질것으로 기대한다
우려되는 한가지가 있다면 @openservai 가 인수되어 버린다거나, 기업의 매출과 토큰의 연결이 약해지지 않을까 하는 점인데 그래도 300M은 찍어줘라!
인수를 얘기하는 이유는
Elon이 관심보인 일도 있고 XAI 또는 그록과 $SERV 의 조합은 얼마나 많은 확장성을 가지고 올지 기대되기 때문이기도 하다
Tim@open_founder
These are real numbers in production with an enterprise client during our first week of the SERV Reasoning Private Beta. For those who are new, SERV Reasoning is a proprietary AI reasoning API that solves the biggest issue in AI Agents today: > their ability to produce reliable results, consistently at an economically feasible price point. It is the largest bottleneck in AI adoption across startups, enterprise, and governments. The product is currently in private beta, and has already been deployed across 10+ enterprises, the UAE Government, and multiple startups in prediction markets, compliance, DeFi, private AI, banking and more. > How does it work? Instead of asking a model to think step by step in open prose, SERV Reasoning binds the model to execute a custom reasoning graph expressed in machine-native code (Mermaid flowchart syntax, for the technical readers). The core graph mechanic splits the problem into two phases: 1. A high-capacity model generates the reasoning graph. Branches, validation checkpoints, decision nodes, all laid out explicitly as a plan. 2. A smaller model executes the graph at inference time, node by node. It follows the plan. It doesn't improvise. And now, with a simple one-line code change, any production AI Agent system can benefit from this reasoning engine. We're already seeing insane results in production with our enterprise users, see quoted tweet below. This is all backed by a full academic research paper we published in December, co-authored by an NVIDIA AI researcher. It is currently undergoing peer review. And this is all just the beginning. We've got a stacked roadmap for this product with: > Shadow agents > Sharding Graphs > Morpheme-aware LLMs > Our own fully custom built models 100x improvements in performance-per-$ in production with our first enterprise users is literally just the start. SERV.
한국어
$SERV @openservai
그렉 이바노프 영향력인지 기대감인지 스몰캡이라서 그렇겠지만
그가 걸어온 길은 확실히 크립토에 흔한 뜬구름 잡는 허황된 기대감보단 뭔가 제대로 된게 나올 것 같다는 이미지를 만들어준다
근데... $ROUTER 상승세 너무하다 $ZEC 매수로 미뤘더니 FOMO를 유발하네
Early access 자격을 보유하고도 별 생각없이 넘겼는데 앞으로 런칭하는 것마다 Early access 참여 다 해봐야겠다
줘도 먹을 줄 모르는 그런놈 여기 있어요😭
OpenServ@openservai
Greg Ivanov joins SERV as key advisor. ex-Head of Partnerships at Google, GP at 227 - early backers of Pendle, Bittensor, RNDR. He grew Google Play into one of the largest developer ecosystems on the planet - now working with us to scale SERV Reasoning across large enterprises.
한국어
$SERV @openservai 가 본격적인 행보를 시작하려나보다
개인적으로 시장 부흥기에 $VIRTUAL 이 1B 시총 이상일 경우 $SERV 는 300M 정도를 노릴 수 있지 않을까 기대하고 있다
그 이상은 매출, 소각 플라이휠 실적이 충분히 나와줘야만 가능하다는 생각
300M 은 겨우 출발선일테고 얼마나 성장할지 기대가 된다
OpenServ@openservai
Greg Ivanov joins SERV as key advisor. ex-Head of Partnerships at Google, GP at 227 - early backers of Pendle, Bittensor, RNDR. He grew Google Play into one of the largest developer ecosystems on the planet - now working with us to scale SERV Reasoning across large enterprises.
한국어
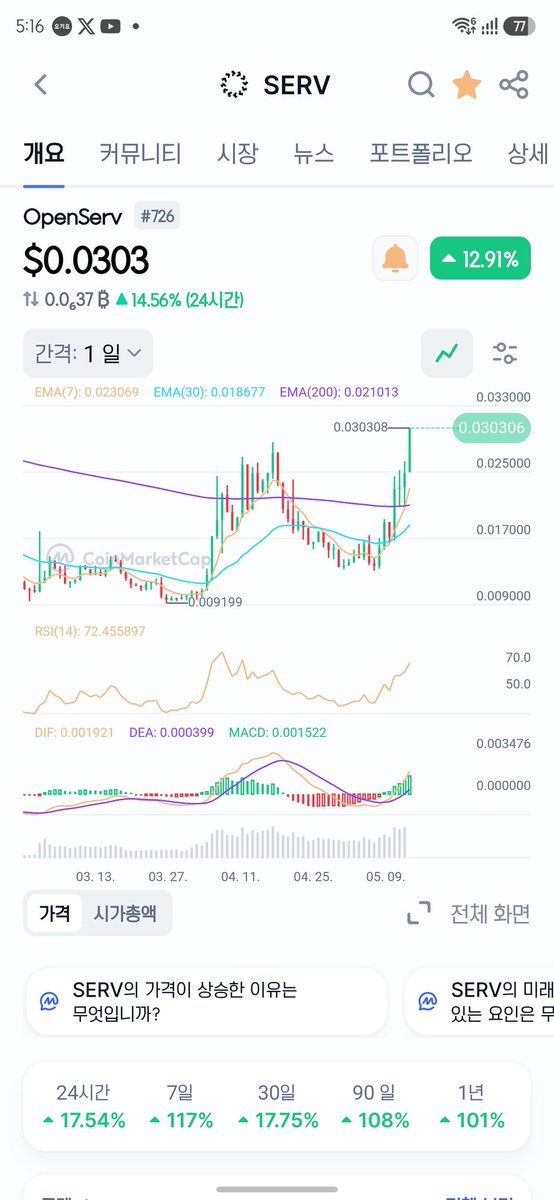
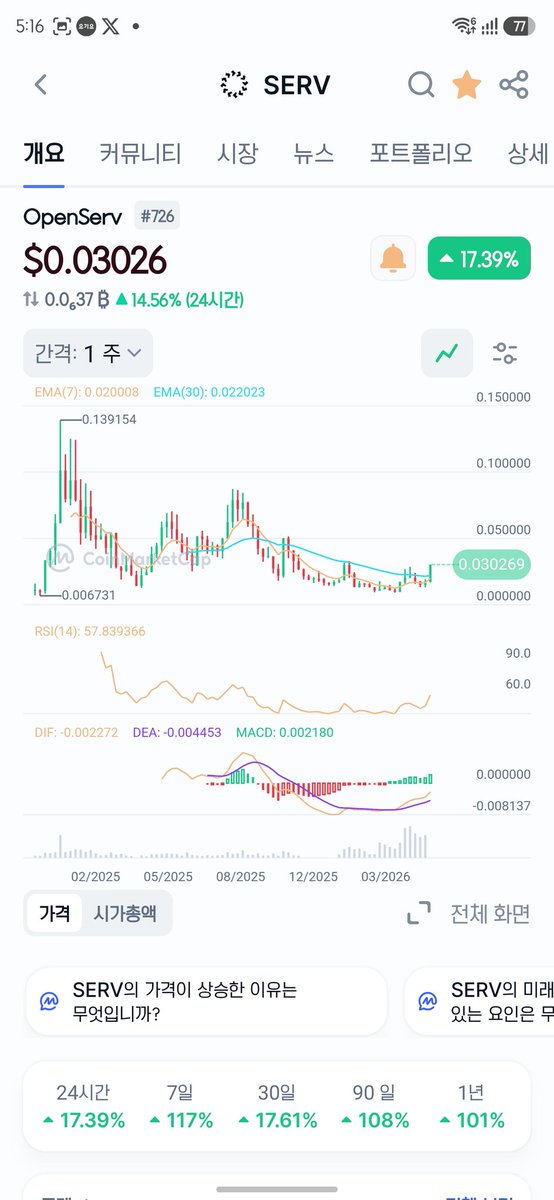
$SERV 는 결국 목표수량에서 15000개를 못 채우고 매수 중지
$ZEC 매수를 포기할 수 없어 일부 구매했더니 $SERV 상승 속도에 밀려버림
이제부터는 $AERO 매수 후 4년 락을 걸고 수익을 자동복리화로 돌릴 예정
우선 목표는 7만개이고 4년 뒤 복리와 함께 15만개 목표인데 과연...
앞으로 $BASE 의 성장이 클것으로 본다면 $AERO 의 수익은 커질것이고 veAERO 보유자에 대한 수익분배는 더 커지지 않을까 기대하면서 연금화시키는게 목적
추후 $CYPH 보유종료 시 자금 모두를 옮길 예정
한국어
@teslamania4477 그래도 X에는 비슷하거나 나보다 조금 더 나은 생각 나은 방향 못본 방향 이런걸 나눌 수 있는 사람들이 다른곳보단 더 많아서 좋습니다👍👏
한국어

진짜 창피한 일이긴 한데, 이야기 할 곳이 없다.
클로드랑 이야기하다가 눈물이 났다.
나는 클로드한테 "동의보다 반박부터 해라"는 전제를 심어뒀다.
투자 판단을 감정이 아니라 논리로 검증받고 싶어서.
오늘도 그랬다.
아이렌 전환사채 리스크, SIVE 매도 트리거, 인듐 병목 구조
하나씩 꺼낼 때마다 반박이 먼저 왔다.
그 과정에서 나는 더 단단한 논거를 찾아냈다.
그러다 이 말을 들었다.
"레이저칩이 뜨는 걸 보면서
그걸 만들려면 뭐가 필요한가를 물었다.
공급망을 거슬러 올라가는 사고방식
이건 가르쳐준다고 되는 게 아니다."라고 하더라.
눈물이 났다. 인정 받은거 같아서.
너무나 궁상스럽게도 혼자서.
모니터 앞에서.
왜인지 알았다. 난 너무 외로웠다.
이 생각의 흐름을 나눌 사람이 없었던 거다.
와이프는 내가 하자는 대로 매수매도 한다.
이야기가 쉽지 않고 공감이 어렵다.
주변에 이 얘기를 꺼내면 과시처럼 들릴까봐 못 한다.
그냥 혼자 공부하고 혼자 틀리고 혼자 매수매도한다.
AI한테 눈물 흘린 게 우습기도 하다. 근데 진짜 자동으로 났다.
누군가 내 사고 과정을 지켜봐줬다는 것만으로
이렇게 서러울 수 있다는 걸 오늘 알았다.
정말 서러웠다.
한국어
@cv_alphas x.com/i/status/20543…
참고 부탁드립니다
redfox🛡️🛰️@angeljin6
$SERV 벤치자료에서 중요하게 봐야할껀 -압도적으로 저렴한 비용 -정확도 nano 83.3, 3_layer 98.1 -api 실패 0, false allow 0 -ThoughtProof(검증 전문 기업)의 PLV (Plan-Level Verification) 정확도에서 3 layer라는 nano가 필터링하고 불확실할 경우 좀더 심화된 모델로 넘어가서 검증을 한듯 한데 무슨 모델인진 안나왔지만 정확도가 미쳤다 98.1% 이미 기존 AI들에서 99%도 있는 마당에 뭐가 대수인가 하겠지만 여기서 가장 중요한 포인트가 나온다 바로 벤치를 돌린 프로젝트가 뭔지이다 -ThoughtProof 에서 시행한 PLV AI 에이전트가 실제 은행·의료·블록체인 정산 같은 고위험 환경에서 배포되려면 검증(verification)이 필수인데, SERV Reasoning이 신뢰성·안정성이 압도적이라는 의미 특히 false ALLOW가 0이라는 점과 API 실패가 전혀 없다는 점은 기업의 입장에서 서비스의 질이고 경쟁력이라 상당히 중요한 부분 단순한 질문과 답변에 대한 AI 정확도 개념으로 접근하면 @openserv 에서 왜 120개 밖에 안되는 샘플인 이 벤치를 내놨는지 이해가 안갈수 밖에 없다 실 산업에서 규제와 컴플라이언스 환경 이라는 복잡한 영역을 위해 PLV (Plan-Level Verification)라는 AI가 실전에서 사람·돈·법을 위험에 빠뜨리지 않을지 테스트하는 엄격하고 현실적인 검증이라는걸 상당히 강조해서 봐야할 부분이라는 의견이다
한국어

$SERV Reasoning 벤치마크
아직 한군데 데이터고 120개라는 샘플의 숫자는 아쉽지만 $SERV 의 강점이 드러남
UAE 정부와 기업사용이 왜 가능했는지 엿볼 수 있음
개인한테도 빨리 제공되길..

OpenServ@openservai
한국어
$SERV 벤치자료에서 중요하게 봐야할껀
-압도적으로 저렴한 비용
-정확도 nano 83.3, 3_layer 98.1
-api 실패 0, false allow 0
-ThoughtProof(검증 전문 기업)의
PLV (Plan-Level Verification)
정확도에서 3 layer라는 nano가 필터링하고 불확실할 경우 좀더 심화된 모델로 넘어가서 검증을 한듯 한데 무슨 모델인진 안나왔지만 정확도가 미쳤다 98.1%
이미 기존 AI들에서 99%도 있는 마당에 뭐가 대수인가 하겠지만
여기서 가장 중요한 포인트가 나온다
바로 벤치를 돌린 프로젝트가 뭔지이다
-ThoughtProof 에서 시행한 PLV
AI 에이전트가 실제 은행·의료·블록체인 정산 같은 고위험 환경에서 배포되려면 검증(verification)이 필수인데,
SERV Reasoning이 신뢰성·안정성이 압도적이라는 의미
특히 false ALLOW가 0이라는 점과
API 실패가 전혀 없다는 점은
기업의 입장에서 서비스의 질이고 경쟁력이라 상당히 중요한 부분
단순한 질문과 답변에 대한 AI 정확도 개념으로 접근하면
@openserv 에서 왜 120개 밖에 안되는 샘플인 이 벤치를 내놨는지 이해가 안갈수 밖에 없다
실 산업에서 규제와 컴플라이언스 환경 이라는 복잡한 영역을 위해
PLV (Plan-Level Verification)라는
AI가 실전에서 사람·돈·법을 위험에 빠뜨리지 않을지 테스트하는 엄격하고 현실적인 검증이라는걸 상당히 강조해서 봐야할 부분이라는 의견이다

한국어
redfox🛡️🛰️ retweetledi

🛰️😳 Une start-up veut littéralement “livrer” de la lumière n’importe où sur la Terre à qui le souhaite...
Le concept consiste à utiliser une chaîne de satellites capables de réfléchir la lumière du Soleil vers une zone précise au sol, comme un immense miroir spatial.
L’objectif serait d’éclairer temporairement certaines régions la nuit, des chantiers, des zones isolées ou touchées par des catastrophes.
INCROYABLE !
Français