Anto
516 posts

Anto
@anto_edd
Full-time marketer at a billion-dollar company. Weekends spent building @Hire_AIHuman @theofficial_app @snoopdoc_app
India Katılım Kasım 2016
543 Takip Edilen354 Takipçiler

The financial incentive to spam on X will decline enormously over the next 30 days and soon be negative.
English
Anto retweetledi

The software sector is facing a massive debt wall:
~$40 billion in software and services debt matures in 2028, the largest single-year concentration.
The vast majority of this is rated B- or lower, deep in junk territory, with no investment-grade debt in the mix.
In total, ~$100 billion in software debt matures from 2026 to 2029, with an additional ~$70 billion beyond 2030.
Meanwhile, AI disruption is increasing credit risk for software borrowers, the exact companies that private credit funds have been lending to most aggressively.
Software is also the largest sector in the leveraged loan market, representing 12% of the total.
Refinancing this debt at higher rates with deteriorating fundamentals will be a growing problem for the sector.
The software sector has a tough road ahead.

English
Anto retweetledi

In a world where you can be anything, be a number 50
English
Chennai can very well become like this in next 10 yrs but….
#Chennai
Travel Diaries@I_love_family1
Panama City, Panama 🇵🇦
English

This footage from the Infosys in Bangalore during the 1990s reflects the spirit of Indian progress and mindset at the time
India was already on track to become a superpower by 2020
So what actually went wrong?
English

guys i think the launch worked
Dhravya Shah@DhravyaShah
been building in this space for years now, and have followed nishkarsh for years as well - congrats on the launch! since this is in the same space we're building in, i dived deep into it and have thoughts. the launch itself is very hype-y, and is meant to trigger rage bait 1. it's positioned as a database, but is almost a @supermemory-like system 2. their example of "vector dbs" not being able to do this, is really a question of "embedding models". and embedding models have superpositions, they are cheap and are easily able to infer differences between them. it's not hard to ask claude to do a mini experiment to prove this (attached below). What does matter is: is it able to track how knowledge evolves? time passes? this made me curious so i read their paper 3. their research paper is hardcoding and gaming the benchmark by different prompt for every category!!! (see image below). If their benchmarking is fixed, supermemory will remain the SOTA. 4. they reinvented contextual retrieval paper by Anthropic from 2024 and called it "the orphaned pronoun paradox" 5. they mention they use a custom "in-memory vector store" = at about 500GB, you will have to pay more than $10k for just the RAM. 6. inference is run too many times in the pipeline - which means for every LLM token you ingest, you will end up paying 5x more than token cost for the graph + contextualization + storage. 7. latency and cost numbers were never reported. My hunch is because of the architecture, the latency will struggle at scale. but i can't tell - their product is behind demo gate. 8. the benchmarking code is not OSS (from what i can tell). not replicable + who knows how much context they are injecting into the model? what's the K? 9. inorganic, undisclosed ads (just read the quote tweets). influencer accounts with 400k+ followers all saying the same thing. people keep getting away with this @nikitabier lol i'm all in for healthy competition and progress in this fields, enjoy seeing good work being done by others. but its easy to just say things. "no one will check." playing the game the right way is hard, and everyone's just saying whatever they can to impress people. TLDR is: you should use this if you want to spend 2-5x more for no real marginal improvement and enjoy unhealthy research and business practices. attached: 1. experiment to disprove hypothesis of vector dbs not understanding grey vs grey 2. one of their prompts, which just says "say i dont know". they scored 100% :)
English
@getmesomelatte Exactly you can’t even walk for 100 meters..such a poor planning
English

Anto retweetledi

The next generation of solo entrepreneurs won’t be developers.
They won’t obsess over tech stack or trendy design libraries.
They will be no-code people focused on solving a problem, shipping crazy fast with AI, and cracking distribution on social media.
They will be 100x wealthier than us.
English

With AI building a saas is super easy
any feature is one prompt away
almost believed myself... stop
English

We're accelerating into the Singularity:
> Claude/Anthropic → Fastest to ~$20B revenue ever
> ChatGPT → Fastest ever from 0 to 1B users
> OpenClaw → Fastest GitHub repo ever to 250K+ stars
> Vibe Coding → Adopted by 90% of US coders in shortest time ever
> Cursor → Fastest SaaS to $1B+ ARR
> Lovable, Bolt & Replit → Fastest to $100M ARR
> Tesla FSD → Fully autonomous driving 99% intervention-free
> SpaceX brought more tons on orbit than 4 past years combined
> OpenAI → Targeting $20B+ in 2026
> Suno → $200M ARR, viral top music hits generated by AI
> OpenAI, Scale AI, Anthropic, Project Prometheus, xAI raised almost $100B combined
> Mercor AI → $1M to $500M ARR in ~17 months
> Gamma → Profitable at $100M ARR
> ElevenLabs → $90M to $281M ARR in under a year
> Granny Spills, Lil Miquela & thousands of AI influencers scoring over 1B views
> Google Willow → Solved in 5 minutes what the fastest supercomputer would take 10 septillion years
> AI drug discovery → First fully AI-designed drug in 18 months vs 3–6 years
> AI inference cost → Down 280x in 2 years for the same performance level
> AI context window → from 4k to 1m token in just 2 years
> David Sinclair's longevity experiments in weeks vs 100,000 years
> DNA sequencing 80x+ faster
> AlphaFold went beyond proteins to full genome interaction
> Humanoid robots entering factory floors at scale
> Supercomputing surges
> Startups going from 0 to 1 billion valuation in less than a year
The next 3 years gonna by the most insane years in human history. I'll have my last mega locked in run until 2030 to retire and go offgrid to live a farm life without internet. I dont think we're gonna invent a way to be mentally healthy in the post-ai world. I dont know any mentally healthy person now, everyone is struggling in some form
English




I really liked Dubai.
And it's so sad what's happening right now 😞
But I'm so happy to be here 🇨🇭
No drama.
No conflicts.
Just peace and quiet.
And one of the safest places to be in case WW3 breaks out.


English
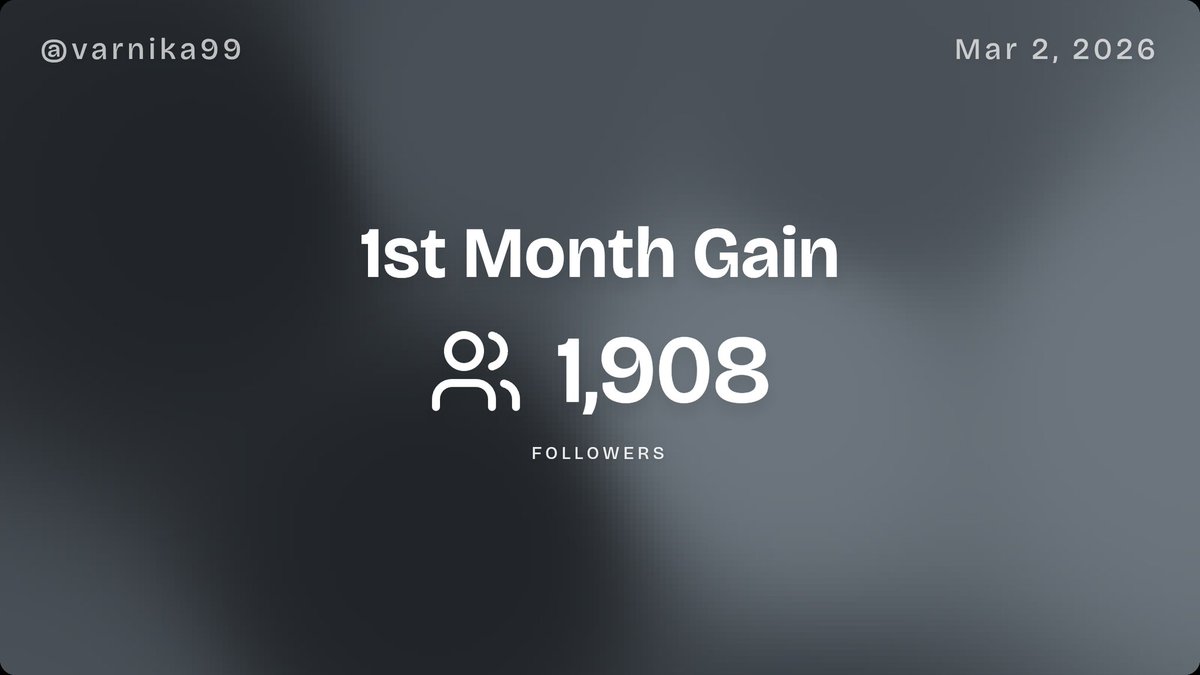
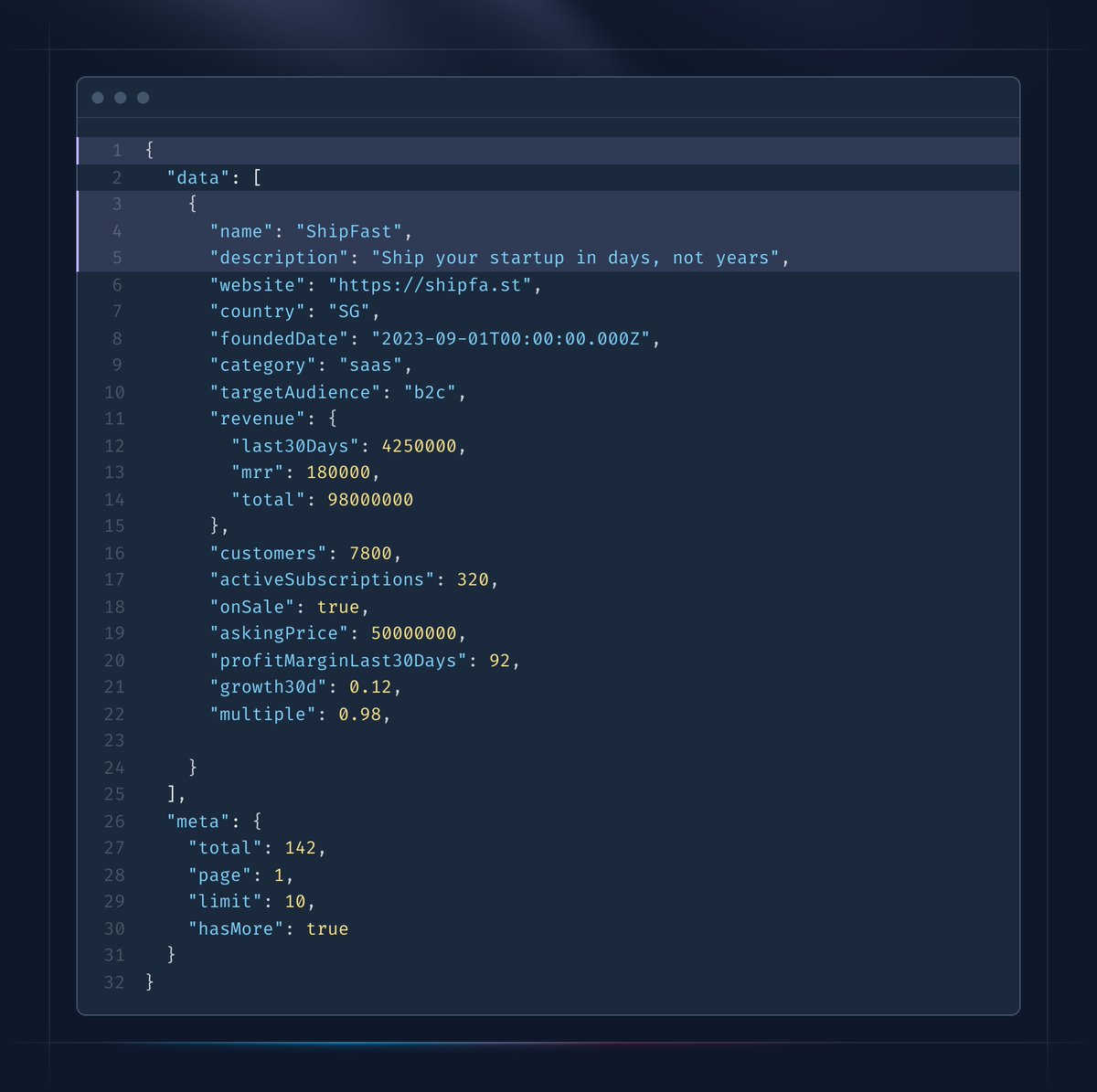
I built an API for TrustMRR ✨
You can now access the $1.2B database of verified revenue programmatically for free.
Use cases:
🤝 Get the 5 most recent startups listed for sale
🏆 Fetch revenue for the last 30 days for {xHandle}
💡 See whether SaaS makes more money than mobile apps
I added a bunch of filters and sorting options so you can find clever ways to use the API.
Go to your /dashboard to get started, or use the link below ↓
English
@naturedotcom Good for you, i get zero engagement barely 100+ views on all my post
English

Anto retweetledi

🚨 Someone just open sourced a fully autonomous AI hacker and it's terrifying.
It's called Shannon.
Point it at your web app, and it doesn't just scan for vulnerabilities. It actually exploits them. Real injections. Real auth bypasses. Real database exfiltrations.
Not alerts. Not warnings. Actual working exploits with copy-paste proof-of-concepts.
Here's what this thing does autonomously:
→ Reads your entire source code to plan its attack
→ Maps every endpoint, API route, and auth mechanism
→ Runs Nmap, Subfinder, and WhatWeb for deep recon
→ Hunts for Injection, XSS, SSRF, and broken auth in parallel
→ Launches real browser-based exploits to prove each vulnerability
→ Generates a pentester-grade report with reproducible PoCs
Here's the wildest part:
It follows a strict "No Exploit, No Report" policy. If it can't actually break it, it doesn't report it. Zero false positives.
It pointed at OWASP Juice Shop and found 20+ critical vulnerabilities in a single run including complete auth bypass and full database exfiltration.
On the XBOW Benchmark (hint-free, source-aware), it scored 96.15%.
Your team ships code daily with Claude Code and Cursor. Your pentest happens once a year. That's 364 days of shipping blind.
Shannon closes that gap. One command. Fully autonomous.
The Red Team to your vibe-coding Blue team. Every Claude coder deserves their Shannon.
10.6K GitHub stars. 1.3K forks. Already trending.
100% Open Source. AGPL-3.0 License.

English