Aditya Vora retweetledi
Aditya Vora
38 posts


Aditya Vora
@anvorain
Ph.D student in GruVi Lab at Simon Fraser University. Interested in Computer Vision and Computer Graphics Research.
Vancouver, BC, Canada Katılım Ocak 2012
1.1K Takip Edilen180 Takipçiler


Aditya Vora retweetledi


Aditya Vora retweetledi


Aditya Vora retweetledi

Aditya Vora retweetledi

Excited to share our recent work: Free-Range Gaussians 🥚✨
The core idea: instead of predicting Gaussians on a pixel- or voxel-aligned grid, we let them live freely in 3D space.
🌐 Project: free-range-gaussians.github.io
📝 Paper: arxiv.org/abs/2604.04874
English
Aditya Vora retweetledi

Check out our work on robust 3D reconstruction from 360° captures.
Using casual 360 video capture, ✨FullCircle✨ leverages the full 360° field of view and removes the camera operator from the reconstruction.
Browse our data, code, and webpage.
Andrea Tagliasacchi 🇨🇦@taiyasaki
📢📢📢 Introducing "FullCircle: Effortless 3D Reconstruction from Casual 360° Captures" TL;DR: 10x faster casual capture with clean reconstructions Homepage: theialab.github.io/fullcircle Code: github.com/theialab/fullc… arXiv: arxiv.org/abs/2603.22572 Led by Yalda Foroutan & Ipek Oztas
English


Our approach produces consistent shape decomposition across multiple levels and in different shape categories, from coarse semantic abstraction to fine detail, all in a fully unsupervised manner.
Done with: @taiyasaki, @lily_goli and @richardzhangsfu
GIF
English
After training, our part embeddings form clear clusters in the embedding space, grouping similar parts from different objects together. This enables the model to learn consistent part correspondences, where visually similar parts naturally lie close to each other.
GIF
English
HiT: Hierarchical Transformers for Unsupervised 3D Shape Abstraction
- Project: aditya-vora.github.io/HiT/
- Paper: arxiv.org/abs/2510.27088
- Code: github.com/aditya-vora/HiT
We will present HiT at @3DVconf Poster 5-27.
Join us if you are around!
GIF
English
Aditya Vora retweetledi

Advances in 4D Representation: Geometry, Motion, and Interaction
Abstract (excerpt)
Instead of offering an exhaustive enumeration of many works, we take a more selective approach by focusing on representative works to highlight both the desirable properties and ensuing challenges of each representation under different computation, application, and data scenarios.
The main take-away message we aim to convey to the readers is how to select and then customize the appropriate 4D representations for their tasks. Organizationally, we separate the 4D representations based on three key pillars: geometry, motion, and interaction. Our discourse will not only encompass the most popular representations of today, such as neural radiance fields (NeRFs) and 3D Gaussian Splatting (3DGS), but also bring attention to relatively under-explored representations in the 4D context, such as structured models and long-range motions.
Throughout our survey, we will reprise the role of large language models (LLMs) and video foundational models (VFMs) in a variety of 4D applications, while steering our discussion towards their current limitations and how they can be addressed. We also provide dedicated coverage on what 4D datasets are currently available, as well as what is lacking, to drive the subfield forward.

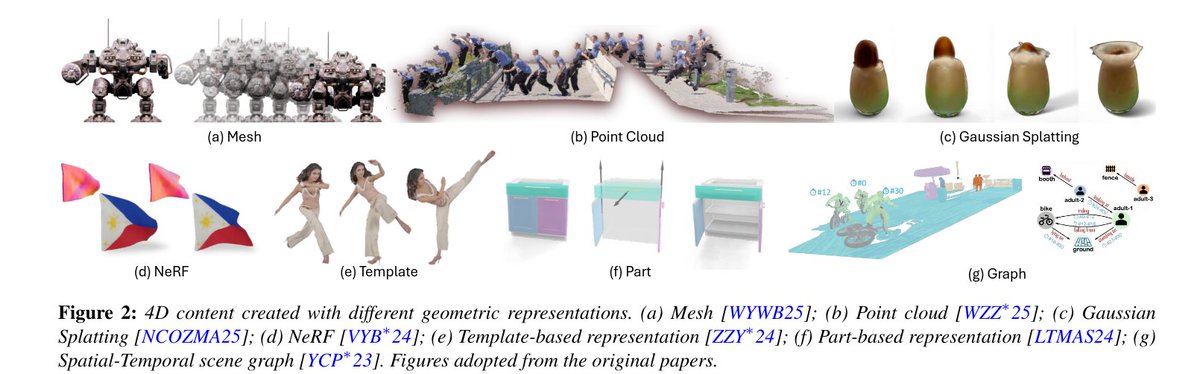
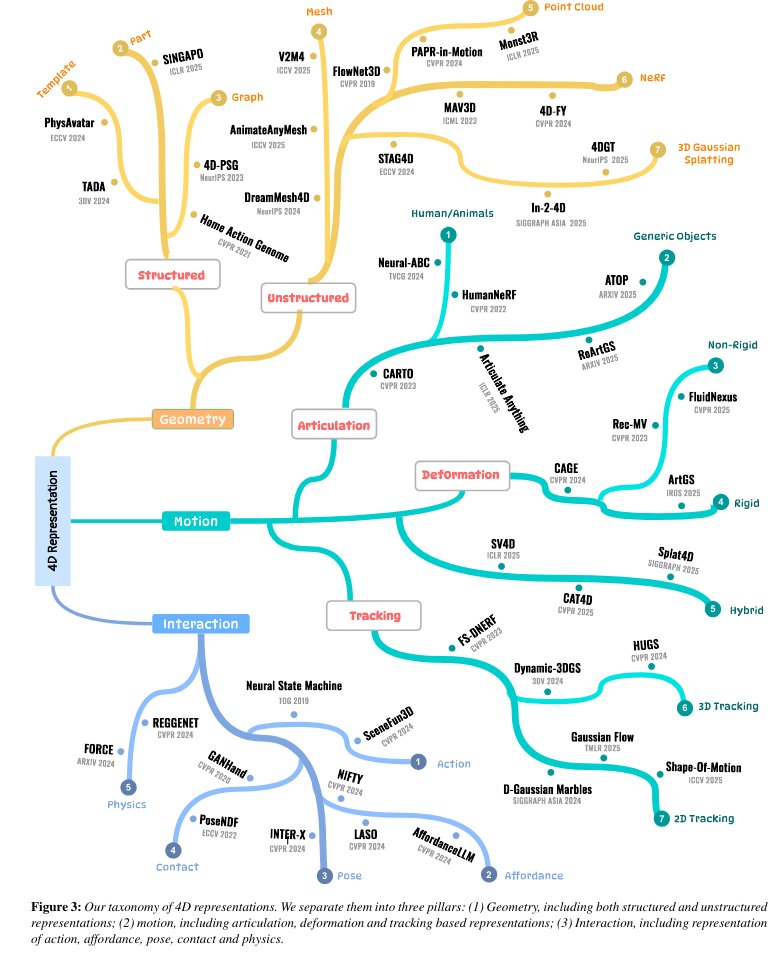

English
Aditya Vora retweetledi

ASIA = Adaptive (3D) Segmentation (from) Image Annotations. I’d also called it SAW, Segment Any Way!
Indeed, the most useful and practical segmentation is one that fully adapts to user intents … see technical details below.
Sai Raj Kishore@sairajk007
📢📢📢 "ASIA" @ #SIGGRAPHAsia2025. 😉 We segment 3D shapes into possibly non-semantic and non-text describable parts using only a few annotated in-the-wild images as references! 👉Project Page: sairajk.github.io/asia/ 📄Paper: arxiv.org/abs/2509.24288
English
Aditya Vora retweetledi

📢📢📢 "ASIA" @ #SIGGRAPHAsia2025. 😉
We segment 3D shapes into possibly non-semantic and non-text describable parts using only a few annotated in-the-wild images as references!
👉Project Page: sairajk.github.io/asia/
📄Paper: arxiv.org/abs/2509.24288
English
Checkout Amir's work on few step image editing with diffusion.
Amir Alimohammadi@amirhossein_alm
[1/6] Excited to share that our new work, Cora, has been accepted to SIGGRAPH! 🚀We improve fast image editing by leveraging semantic correspondences. 🖌️Cora also gives users flexibility in deciding what to keep or change from the input. webpage: cora-edit.github.io
English
Aditya Vora retweetledi

Thank you Zhengzhong for sharing! Our code is now avilable at github.com/mingrui-zhao/S…
Zhengzhong Tu@_vztu
🚨SweepNet: Unsupervised Learning Shape Abstraction via Neural Sweepers [ECCV'24] 🌟𝐏𝐫𝐨𝐣: mingrui-zhao.github.io/SweepNet/ 🚀𝐀𝐛𝐬: arxiv.org/abs/2407.06305 a novel approach to shape abstraction through sweep surfaces
English
Aditya Vora retweetledi
Introducing Slice3D (#CVPR2024 paper #23, 10:30-12, Arch 4A-E) for single-view 3D reconstruction by first predicting multi-slice images. The key is occlusion revelation, while sidestepping multi-view inconsistency. Trained on single A40 & inf time < 20s.
yizhiwang96.github.io/Slice3D/
English
Aditya Vora retweetledi
(1/4) Pleased to announce our
#CVPR2023 paper ARO-Net, a novel shape encoding for learning implicit field representation of 3D shapes. Project page: aro-net.github.io
GIF
English