Sabitlenmiş Tweet
apapanto
16K posts

apapanto retweetledi

A 21-year-old MIT student wrote a master's thesis in 1937 that Harvard's most famous professor of cognitive science later called "possibly the most important master's thesis of the century."
I read it at 2am and could not believe one paper had quietly built the entire foundation of every computer that exists today.
His name was Claude Shannon. The thesis is called "A Symbolic Analysis of Relay and Switching Circuits."
Every smartphone in your pocket. Every server farm running ChatGPT. Every chip Nvidia ships. Every line of code an engineer has ever written. All of it traces back to a single insight one graduate student had at 21 years old, working on a side project at MIT.
Here is the story almost nobody tells you.
Claude Shannon was born in 1916 in a small town in Michigan. He grew up tinkering. Built a telegraph between his house and a friend's house using barbed wire from a nearby fence. Repaired radios for the local department store. He studied both mathematics and electrical engineering at the University of Michigan because he could not decide which one he loved more. That refusal to choose is what eventually made him.
When he got to MIT for graduate school in 1936, he was assigned to operate a strange machine called the differential analyzer. It was room-sized. Mechanical. Built by Vannevar Bush. It used a tangle of gears, shafts, and electrical relays to solve calculus problems. Most students just operated it.
Shannon did something else. He stared at the relay circuits inside it. The way they clicked open and closed. The way they routed signals through the machine.
He noticed something nobody had noticed before.
The relays inside the machine had two states. Open or closed. On or off. One or zero. And the way the relays were wired together to make decisions looked exactly like a 90-year-old branch of mathematics that almost everyone had forgotten about. Boolean algebra. Invented by a British mathematician named George Boole in the 1850s. Boole had built a system of logic where statements could be true or false, and you could combine them with operators like AND, OR, and NOT to derive new statements.
For 90 years, Boolean algebra had been a curiosity. A philosophical tool. Nobody saw a practical use for it.
Shannon saw it.
He realized that an electrical circuit was not just an electrical circuit. It was a physical implementation of a logical statement. A switch that closed when both A and B were true was an AND gate. A switch that closed when either A or B was true was an OR gate. The entire branch of pure mathematics that Boole had invented as a thought experiment could be built out of wires and relays. And once you could build logic out of wires, you could build anything that could be expressed in logic out of wires too.
This was the insight that quietly created the modern world.
Before Shannon's thesis, electrical engineers designed circuits the way artisans built watches. By feel. By experience. By trial and error. Every new circuit was a craft project. There was no theory underneath it.
After Shannon's thesis, circuit design became a branch of mathematics. You could specify the logic you wanted on paper, and translate it directly into a wiring diagram. You could prove a circuit was correct before you built it. You could simplify a circuit by simplifying the underlying logical expression.
The MIT historian who reviewed his thesis described the shift in one sentence. It transformed circuit design from an art into a science.
Shannon was 21 years old when he wrote it.
That alone would have earned him a place in every computer science textbook on Earth.
But Shannon was not done. He spent the next 11 years working on a problem nobody had even framed properly. He wanted to know what information actually was. Not what messages were. Not what signals were. What information was. Mathematically. Quantitatively. As a measurable thing.
In 1948, while working at Bell Labs, he published a 79-page paper called "A Mathematical Theory of Communication." The paper invented the entire field of information theory in a single shot.
He proved that all information, regardless of whether it was a voice on a phone, a photograph in a magazine, or a chess move on a board, could be measured in a single unit. He named that unit the bit. Short for binary digit. It was the first time anyone had given information a unit of measurement.
The paper proved something that sounded impossible. He showed that you could send a message reliably through a noisy channel, with arbitrarily low error, as long as you encoded it correctly and stayed below a specific limit he called the channel capacity. Every Wi-Fi connection, every satellite signal, every cell phone call, every fiber optic transmission across the floor of the Pacific Ocean operates inside the mathematical bounds that Shannon proved in this single paper.
He did all of this in his spare time while officially working on cryptography for the war effort.
The strangest part of the man is what he did when he was not inventing the future.
He rode a unicycle through the hallways of Bell Labs at night while juggling. He built a chess-playing machine in 1950 that played a primitive form of chess decades before computers were supposed to be capable of it. He built an electronic mouse named "Theseus" that could solve a maze and remember the solution. It was one of the first machines on Earth that learned. He built a flame-throwing trumpet for fun. He had a closet full of unicycles in different sizes. He installed a chairlift across his backyard so his kids could get to the lake faster.
Marvin Minsky, one of the founders of artificial intelligence, said Shannon was the most genuinely playful great scientist he had ever met. Other people approached research with seriousness. Shannon approached it like a kid who had snuck into the toy store after closing time.
Stevens Institute of Technology called him the least known genius of the 20th century.
That title is exactly correct. Most people have heard of Einstein, Turing, von Neumann. Shannon's name barely registers outside engineering departments. Yet without his master's thesis, there is no digital circuit. Without his 1948 paper, there is no internet. Without his framework, there is no measurement of information at all, which means no compression, no error correction, no cryptography, no machine learning.
He died in 2001 at age 84, after years of Alzheimer's disease that took away his ability to recognize the world he had built. Most newspapers ran a small obituary. The world he had given us did not pause.
His thesis is on the MIT archive. His 1948 paper is on the Bell Labs site. Both are free. Both are short. Both are still readable today by anyone willing to spend an evening with them.
The least known genius of the 20th century is one click away from you.
Most people will never open the file.

English
apapanto retweetledi
A mathematician who shared an office with Claude Shannon at Bell Labs gave one lecture in 1986 that explains why some people win Nobel Prizes and other equally smart people spend their whole lives doing forgettable work.
His name was Richard Hamming. He won the Turing Award. He invented error-correcting codes that made modern computing possible. And he spent 30 years at Bell Labs sitting in a cafeteria at lunch watching which scientists became legendary and which ones faded into nothing.
In March 1986, he walked into a Bellcore auditorium in front of 200 researchers and told them exactly what he had seen.
Here's the framework that has been quoted by every serious scientist for the last 40 years.
His opening line landed like a punch. He said most scientists he worked with at Bell Labs were just as smart as the Nobel Prize winners. Just as hardworking. Just as credentialed. And yet at the end of a 40-year career, one group had changed entire fields and the other group was forgotten by the time they retired.
He wanted to know what the difference actually was. And he said it wasn't luck. It wasn't IQ. It was a specific set of habits that almost nobody is willing to follow.
The first habit was the one that hurts the most to hear. He said most scientists deliberately avoid the most important problem in their field because the odds of failure are too high. They pick a safe adjacent problem, solve it cleanly, publish it, and move on. And because they never swing at the hard problem, they never hit it. He said if you do not work on an important problem, it is unlikely you will do important work. That is not a motivational line. That is a logical one.
The second habit was about doors. Literal doors. He noticed that the scientists at Bell Labs who kept their office doors closed got more done in the short term because they had no interruptions. But the scientists who kept their doors open got more done over a career. The open-door scientists were interrupted constantly. They also absorbed every new idea passing through the hallway. Ten years in, they were working on problems the closed-door scientists did not even know existed.
The third habit was inversion. When Bell Labs refused to give him the team of programmers he wanted, Hamming sat with the rejection for weeks. Then he flipped the question. Instead of asking for programmers to write the programs, he asked why machines could not write the programs themselves. That single inversion pushed him into the frontier of computer science. He said the pattern repeats everywhere. What looks like a defect, if you flip it correctly, becomes the exact thing that pushes you ahead of everyone else.
The fourth habit was the one that hit me the hardest. He said knowledge and productivity compound like interest. Someone who works 10 percent harder than you does not produce 10 percent more over a career. They produce twice as much. The gap doesn't add. It multiplies. And it compounds silently for years before anyone notices.
He finished the lecture with a line I have never been able to shake.
He said Pasteur's famous quote is right. Luck favors the prepared mind. But he meant it literally. You don't hope for luck. You engineer the conditions where luck can land on you. Open doors. Important problems. Inverted questions. Compounded hours. Those are not traits. Those are choices you make every single day.
The transcript has been sitting on the University of Virginia's computer science website for almost 30 years. The video is free on YouTube. Stripe Press reprinted the full lectures as a book in 2020 and Bret Victor wrote the foreword.
Hamming died in 1998. He gave his final lecture a few weeks before. He was 82.
The lecture that explains why some careers become legendary and others disappear is still free. Most people who could benefit from it will never open it.

English
apapanto retweetledi
A British kid became a chess master at 13, then a bestselling video game designer at 17, then a PhD neuroscientist at 33, then the CEO of the AI lab that won the 2024 Nobel Prize in Chemistry.
People called him unfocused for twenty years. He was running the most deliberate career plan in modern science.
His name is Demis Hassabis, and the thing almost nobody understood while he was doing it was that every single step was feeding the same underlying obsession.
Here is the thread that connects the whole career, and why it matters for how anyone should think about building toward a hard goal.
The chess came first. He was born in London in 1976 and started playing at age four. By eight, he was the London champion for his age group. By thirteen, he had an international master rating that put him in the top fifty players in the world under his age bracket. He was on a track that would have made him a professional player for the rest of his life.
He walked away.
The reason he gave later, in interview after interview, is the part most people miss. He said chess forced him to think constantly about thinking itself. Every move required him to simulate what his opponent was simulating about him. He became fascinated not with winning the game, but with the process the human brain was running in order to play it. He decided chess was too small a container for the real question he wanted to answer, which was how intelligence actually works.
The video games came next. He used the money he won from chess tournaments to buy a ZX Spectrum. He taught himself to code. By seventeen, he was a lead programmer on a game called Theme Park that sold millions of copies. He could have stayed in that industry and built a career as one of the top game designers in Britain.
He walked away from that too.
He went to Cambridge, did a double first in computer science, and then made the move that looked like the strangest pivot of his life. He enrolled in a PhD in cognitive neuroscience at University College London. He was thirty. His peers from Cambridge were already running companies. He went back to graduate school to study how the human hippocampus builds memories and imagines future scenarios.
His 2007 paper on the link between memory and imagination was named one of the top ten scientific breakthroughs of the year by Science magazine. But the paper was never the point. The point was that he had spent three decades quietly building the exact combination of skills nobody else in the world had put together.
Deep intuition for how intelligent agents behave in complex systems, from a lifetime of chess. Hands-on engineering fluency, from years of shipping commercial software. And a rigorous scientific understanding of how biological brains actually produce cognition, from a PhD in neuroscience.
In 2010, he used that combination to co-found DeepMind with Shane Legg and Mustafa Suleyman. The mission statement he wrote was two sentences long and sounded absurd to most people who heard it. Solve intelligence. Then use it to solve everything else.
For the first six years, DeepMind worked almost entirely on games. Atari. StarCraft. Go. People outside the field could not understand why a lab that claimed to be building artificial general intelligence was spending hundreds of millions of dollars teaching computers to play Pong.
Hassabis kept explaining the reason in interviews and almost nobody was listening. Games were not the goal. Games were a controlled environment where you could iterate on general-purpose learning algorithms fast, measure their progress precisely, and prove to yourself that you had built something that could transfer between domains.
In 2016, AlphaGo beat Lee Sedol, the world champion at Go, in a match that had been considered decades away. And the day after that match ended, Hassabis sat down with his team lead David Silver and asked what they should do next.
The answer was the thing he had been working toward his entire life.
They turned the same deep reinforcement learning approach at a problem biology had been stuck on for fifty years. Protein folding. Given an amino acid sequence, predict the three-dimensional shape the protein would fold into. Every drug discovery effort in the world depended on it. The best computational methods could only solve a small fraction of proteins. Experimental methods took years per structure and millions of dollars per protein.
AlphaFold2 was released in 2020. Within a year, it had predicted the structure of almost every protein known to science. Two hundred million structures. Made freely available to the entire research community. More than two million researchers from a hundred and ninety countries have used it since.
In October 2024, Demis Hassabis and John Jumper were awarded the Nobel Prize in Chemistry for that work.
The line almost nobody quotes from his speeches is the one that explains the whole career. He has said, many times, that he did not build AlphaFold to solve protein folding. He built AlphaFold to prove that the approach he had been developing for thirty years could actually work on a real scientific problem. Protein folding was the demonstration. AGI was always the goal.
The chess taught him how to think about adversarial systems. The games taught him how to ship software. The neuroscience taught him how the only existing example of general intelligence actually worked. DeepMind used all three to build a method that could transfer between domains the way the human brain does. And the moment the method was ready, he pointed it at the single most important unsolved problem he could find in a domain where a breakthrough would save millions of lives.
Most people looking at his career from the outside, at any point before 2016, would have called it scattered. A chess prodigy who gave up chess. A video game designer who walked away from a gaming career. A computer scientist who detoured through neuroscience. A startup founder who burned six years on board games.
From the inside, it was the most focused career in modern science. Every step was quietly answering the same question. How does intelligence actually work, and what would it take to build one that could solve problems humans have not been able to solve alone.
The people who change a field are almost never the ones who looked focused along the way.
They are the ones who were obsessed with a single question so deep and so long that the path they took to answer it looked like chaos from the outside and like a straight line from the inside.
And they almost never get credit for the plan until decades later, when the Nobel Committee calls.

English
apapanto retweetledi

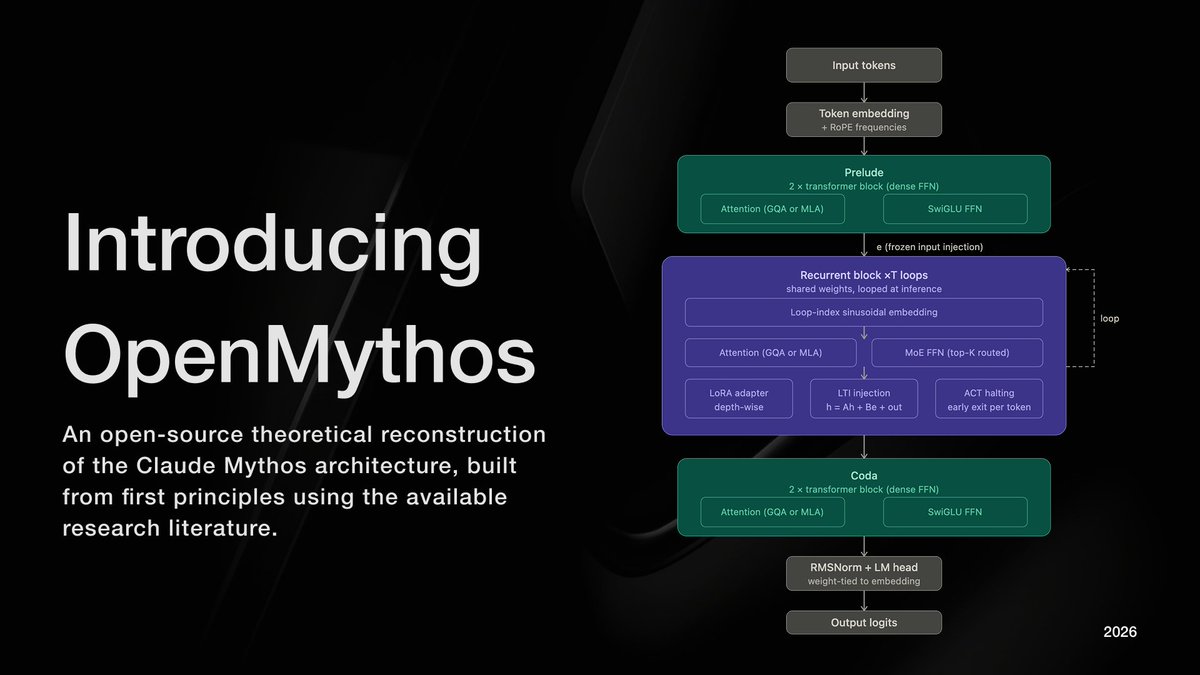
Introducing OpenMythos
An open-source, first-principles theoretical reconstruction of Claude Mythos, implemented in PyTorch.
The architecture instantiates a looped transformer with a Mixture-of-Experts (MoE) routing mechanism, enabling iterative depth via weight sharing and conditional computation across experts.
My implementation explores the hypothesis that recursive application of a fixed parameterized block, coupled with sparse expert activation, can yield improved efficiency–performance tradeoffs and emergent multi-step reasoning.
Learn more ⬇️🧵
English
apapanto retweetledi

Napoleon understood something modern politicians pretend to ignore: wars cost money, and central banks exist to finance them without the messy business of asking taxpayers directly.
The Banque de France, established in 1800, gave Bonaparte exactly what he needed: a printing press disguised as monetary policy. Within four years, Napoleon granted the bank exclusive note-issuing privileges for Paris, and by 1848, it monopolized currency creation across France.
The pattern never changes: create a central bank, grant it money creation powers, then fund endless military adventures while citizens watch their purchasing power evaporate.
Bonaparte's wars consumed roughly 2.5 billion francs between 1803-1815. Direct taxation would have sparked revolution (again). So the Banque de France simply created money, bought government bonds, and voilà—invisible taxation through inflation. French citizens paid for Austerlitz, Jena, and Waterloo through debased currency, not knowing they funded each cannonball and cavalry charge through their shrinking wages and savings.
The genius of central banking lies in this deception. You can't see inflation the way you see income taxes. When bread costs more, people blame bakers, not bankers. When wages stagnate, they blame employers, not money printers. Napoleon's wars would have ended quickly if he had to knock on doors asking French families to fund another campaign against Austria.
Every central bank since has followed Napoleon's playbook. The Federal Reserve financing Wilson's war, Nixon's Vietnam spending spree, Bush's Iraq adventure.
The technology changes, but the scam remains identical: steal purchasing power gradually, fund government expansion continuously, and convince the public that monetary policy serves their interests rather than the state's appetite for power.

English
apapanto retweetledi

Hi! I'm here with *another launch*, it just happens to be extremely niche, nerdy, and probably only for a handful of people.
In the desktop app, Claude Cowork and Code now have a little Bluetooth API for makers & developers, allowing you to build hardware devices that interact with Claude.
I, for instance, built a little desk pet that alerts me whenever Claude is waiting for permission.

English
apapanto retweetledi

In 1955, a British civil servant noticed a mathematical impossibility inside the Royal Navy.
Between 1914 and 1928, the number of active Navy ships dropped by 67 percent. The number of sailors dropped by 31 percent.
But the number of desk officials managing them? It increased by 78 percent.
He spent years studying this absurdity. What he found is now the silent trap destroying tech careers in the age of AI.
His name was Cyril Northcote Parkinson. He realized that the amount of actual work being done had zero correlation with the number of people doing it. He proved that bureaucracy creates its own internal work just to keep itself busy.
He published a single sentence that changed organizational psychology forever.
"Work expands so as to fill the time available for its completion."
If you have two hours to write a report, it takes two hours. If you have two weeks for the exact same report, it takes two weeks. The brain creates artificial complexity, requests unnecessary meetings, and invents new subtasks to justify the allocated time.
This is not a flaw in human motivation. It is a feature of survival in a corporate structure. Looking busy is historically how you keep your job.
In the modern world, this is the most dangerous vulnerability for anyone working in tech.
AI did not just speed up work. It collapsed the timeline entirely. Tasks that took four days now take four minutes.
Most people handle this completely wrong. They fall straight into the Automation Trap.
You use an AI agent to automate your workflow. You finish a 40 hour sprint in 10 hours. You proudly show your manager exactly how efficient you are. You assume this massive increase in productivity will guarantee a promotion.
Leadership does not see a genius. They see a specific role they can easily eliminate to save budget.
Or worse, Parkinson's Law kicks in. They do not give you a raise. They give you three more projects of equal low-level value to fill your remaining 30 hours. You did not gain leverage. You just increased your output for the exact same pay. You automated your own workflow, and six months later, they realize they do not need you.
Here is how you actually survive the shift.
Stop broadcasting your AI efficiency. If you automate your job, keep the timeline the same. Deliver the work on the original deadline. You protect your baseline income and job security.
Take the hours you just saved and upskill aggressively. Do not use that time to scroll online. Study system architecture. Build new data models. Solve the higher-level business problems that management actually cares about.
Stop attaching your worth to manual execution. Syntax and repetitive tasks are commodities now. Detach your professional identity from the labor that can be automated. Attach it firmly to business results.
Parkinson published his law in 1955. The paper sat in academic literature for decades.
The Navy bureaucracy he studied is long gone.
But the mechanism he discovered is the exact reason why working harder is now a losing strategy.
Every time you optimize a manual task.
Every time you brag about saving your boss three hours.
Every time you ask for more busywork to fill your Friday.
It is the same exact trap.
The secret to tech survival? Stop competing with the machine. Become the director of the system.

English
apapanto retweetledi

🚨In 1990s, Stanford researcher Dr. Robert Sapolsky discovered something that should have broken the internet by now.
He was studying dopamine pathways in primates and found that the brain doesn't just adapt to repeated stimulation. It actively fights back.
When you flood dopamine receptors consistently, the brain deploys what neuroscientists call "opponent processes." For every artificial high you create, your nervous system generates an equal and opposite neurochemical low. Not eventually. Immediately. The system is designed to maintain balance, so it starts producing compounds that directly counteract dopamine while you're still experiencing the dopamine hit.
This means every notification, every scroll, every digital reward doesn't just give you a high followed by a return to baseline. It gives you a high followed by a crash below baseline. You end up in neurochemical debt.
Tech companies never publicized this research. They probably never read it. They were too busy discovering that variable ratio reinforcement schedules could keep users engaged for hours. They built addictive systems by accident, then refined them into addiction machines once they realized what they'd stumbled onto.
Your phone delivers an average of 80 dopamine hits per day. Your ancestors got maybe 5. Each hit triggers opponent processes that create a corresponding low. By the end of a typical day of normal phone usage, your baseline dopamine is running in negative territory. You feel flat, restless, vaguely unsatisfied, and hungry for stimulation because your brain chemistry is literally below zero.
You think you're bored. You're chemically depressed by artificial highs.
The opponent process theory explains why nothing feels interesting anymore. Your brain isn't broken. It's precisely calibrated to maintain neurochemical balance, and you keep throwing that balance off with artificial intensity. Every Instagram hit requires an equal Instagram crash. Every TikTok high gets paid for with a TikTok low. Every notification rush gets balanced with notification emptiness.
Your reward system is running a neurochemical deficit that grows larger every day.
Sapolsky's research revealed something even more disturbing: opponent processes don't just create temporary lows. They become permanent changes to your baseline dopamine production. Chronic overstimulation doesn't just make you tolerant to digital rewards. It makes you insensitive to natural rewards.
The sunset that would have captivated your great-grandfather becomes invisible to you not because sunsets got worse, but because your dopamine system needs intensity levels that sunsets can't provide. A good conversation becomes boring not because conversations got less interesting, but because your brain requires the rapid-fire stimulation of social media to register engagement.
You've accidentally trained your reward system to ignore everything that isn't artificially amplified.
This connects to research from Dr. Anna Lembke at Stanford, who found that people who undergo complete digital fasting for just 30 days show measurable increases in dopamine receptor density. Their brains literally regrow sensitivity to natural rewards. Food tastes better. Music sounds more complex. Social interactions become genuinely engaging again.
But there's a catch that nobody talks about: the first two weeks of dopamine detox feel like clinical depression. Your brain has been chemically dependent on artificial stimulation for years. Removing that stimulation creates actual withdrawal symptoms. Restlessness, anxiety, inability to focus, emotional flatness, and desperate cravings for digital input.
Most people interpret these symptoms as evidence that they need their phones. Actually, they're evidence that they've been neurochemically dependent on their phones without realizing it.
The withdrawal period isn't a bug. It's proof the reset is working.
What happens after week three is remarkable. Colors become more vivid. Conversations become genuinely absorbing. Simple pleasures like hot coffee or cool air become satisfying in ways you forgot were possible. Your brain rediscovers that reality contains enough complexity and beauty to hold your attention without artificial amplification.
You don't need more interesting content. You need more sensitive reward systems.
The solution isn't better apps or more engaging entertainment. The solution is restoring your brain's factory settings for what constitutes a worthwhile experience.
Sapolsky's opponent process research suggests this can happen faster than anyone expected. Every day you don't artificially spike your dopamine, your baseline moves a little higher. Every natural reward you pay attention to rebuilds receptor density. Every moment of boredom you endure without reaching for stimulation strengthens your capacity for sustained focus.
Ancient humans lived in a world that provided exactly the right amount of stimulation to keep their reward systems healthy. Enough challenge to stay engaged, enough calm to stay balanced, enough novelty to stay curious, enough routine to stay stable.
We built a world that provides 10 times too much stimulation and wonder why nothing feels rewarding anymore.
Your brain is not the problem. Your environment is the problem.
Change the environment, and the brain heals itself automatically.

Darshak Rana ⚡️@thedarshakrana
English
apapanto retweetledi

The US government is simultaneously blacklisting Anthropic as a national security threat and summoning Wall Street CEOs to warn them about how powerful Anthropic's technology is. Read that again.
Tuesday: Bessent and Powell pull bank CEOs into Treasury HQ for an emergency meeting. The message: Anthropic built a model called Mythos that found zero-day vulnerabilities in every major operating system and every major web browser. Thousands of them. Including a 27-year-old bug in OpenBSD, a system famous for being unhackable. The model chains multiple exploits together autonomously. It doesn't just find the lock. It picks it, opens the door, and walks through.
Anthropic decided the model was too dangerous to release publicly. First time in seven years an AI company has withheld a model over safety concerns. Instead they gave it to Apple, Microsoft, Google, AWS, JPMorgan, and eight other companies through something called Project Glasswing. $100 million in credits. The goal: patch the bugs before someone else builds something similar and doesn't bother telling anyone.
Here's where it gets surreal. Two days before this meeting, a federal appeals court upheld the Pentagon's designation of Anthropic as a supply chain risk to national security. The same company Treasury is now begging banks to listen to. Pete Hegseth wants Anthropic banned from military work because the company refused to let Claude be used for autonomous weapons. The White House said it "fired Anthropic like dogs."
So the Pentagon says Anthropic is too dangerous to work with. Treasury says Anthropic built something so dangerous that every bank CEO needs to hear about it in person. Both statements are about the same company in the same week.
The model that the government is warning Wall Street about is the model the government won't let the military use. The company being treated as a foreign adversary is the one being asked to secure American financial infrastructure. This is what happens when AI capabilities outrun the government's ability to form a coherent position on who builds them.
Bloomberg@business
EXCLUSIVE: Treasury Secretary Scott Bessent and Federal Reserve Chair Jerome Powell summoned Wall Street leaders to an urgent meeting on concerns that the latest AI model from Anthropic will usher in an era of greater cyber risk. bloomberg.com/news/articles/…
English
apapanto retweetledi

This is Algebrica. A mathematical knowledge base I’ve been building for 2.5 years.
215+ entries, carefully written and structured.
400k+ views over this time. Not much in absolute terms, but meaningful to me.
No ads.
No courses to sell.
No gamification.
No distractions.
Just essential pages, aiming to explain mathematics as clearly as possible, for a university-level audience.
Built simply for the pleasure of sharing knowledge.
Content licensed under Creative Commons (BY-NC).
Best experienced on desktop.
If it helps even a few people understand something better, it’s worth it.

English
apapanto retweetledi

Polish physician Eugene Lazowski, working with fellow doctor Stanisław Matulewicz, carried out one of the most ingenious acts of medical resistance in Nazi‑occupied Poland. In the early 1940s, Matulewicz discovered that injecting patients with killed (non‑infectious) typhus bacteria would trigger a false‑positive on German typhus tests without causing illness.
Lazowski realized this could be used to protect Jewish families and Polish civilians in the town of Rozwadów, where deportations and forced labor were escalating. Quietly and systematically, the two doctors began administering these harmless injections to people at risk, especially Jews, who were forbidden from receiving medical care and could only be treated secretly through Lazowski’s backyard fence.
As the number of “typhus cases” grew, German authorities panicked. Terrified of the disease, which had devastated armies in World War I, they declared the area an epidemic zone and imposed quarantine rather than entering the community or deporting its residents. For two years, this fabricated outbreak shielded roughly 8,000 people from roundups and transport to concentration camps.
When German inspectors finally visited, Lazowski staged the sickrooms carefully, and the inspectors, fearful and eager to leave, confirmed the epidemic without discovering the ruse. After the war, Lazowski emigrated to the United States, and his story remained largely unknown until he published his memoir in the 1990s. His operation stands as one of the most remarkable examples of life‑saving deception during the Holocaust.
Lazowski’s operation is also incomplete without noting how it ended and why it stayed hidden for decades. In 1944, as the Germans began retreating and suspicion grew, he narrowly escaped arrest and fled with his family, leaving the “epidemic zone” behind just before the ruse might have been uncovered. After the war, he practiced medicine in Poland but avoided discussing his actions because the communist government discouraged stories that highlighted independent resistance or aid to Jews outside state‑approved narratives.
Only after emigrating to the United States did he begin sharing the full account, eventually publishing his memoir in the 1990s. Survivors from Rozwadów later confirmed how his fabricated outbreak had shielded their community, turning what looked like a small medical trick into one of the most quietly consequential rescue efforts of the Holocaust.
© Reddit
#drthehistories

English
apapanto retweetledi

Memory bandwidth for local AI hardware matters a lot more than most people think
People keep comparing boxes like this:
model size
vs
memory capacity
That is only half the story
The better mental model is:
> capacity = what fits
> bandwidth = how hard it can breathe
> software stack = how much of that you actually cash out
You are buying a memory subsystem
and then negotiating with physics
Here is the current local AI hardware ladder:
> RTX PRO 6000 Blackwell
> 96GB
> 1792 GB/s
> RTX 5090
> 32GB
> 1792 GB/s
> RTX 4090
> 24GB
> 1008 GB/s
Raw single-card bandwidth king stuff
Now Apple
> Mac Studio M3 Ultra
> up to 512GB unified memory
> 819 GB/s
> Mac Studio M4 Max
> up to 128GB
> 546 GB/s
> MacBook Pro M5 Max
> up to 128GB
> 460 to 614 GB/s
> MacBook Pro M5 Pro
> up to 64GB
> 307 GB/s
> Mac mini M4 Pro
> up to 64GB
> 273 GB/s
> MacBook Air M5
> up to 32GB
> 153 GB/s
Apple is not winning raw bandwidth vs top NVIDIA
Apple is winning the:
> “I want one quiet box with a stupid amount of usable memory”
argument
And that is still a very real argument
Now another interesting new category
> DGX Spark
> 128GB unified memory
> 273 GB/s
> GB10 class boxes like ASUS Ascent GX10
> 128GB unified memory
> 273 GB/s
These are not bandwidth monsters
They are coherent-memory NVIDIA CUDA appliances
That matters
Because 128GB in one box changes what fits locally, even if it does not magically outrun a 5090 once the same model fits on both + CUDA
Then there is the one category that actually made x86 interesting again for local AI:
> Ryzen AI Max / Strix Halo
> up to 128GB unified memory
> 256 GB/s
> up to 96GB assignable to GPU on Windows
This is also where the Framework Desktop matters
Not “just another mini PC”
This is one of the first mainstream x86 boxes where local AI starts feeling like a serious hardware class instead of a laptop pretending very hard
Then the trap people keep falling into:
Most “AI PCs” are not in this tier
They are down here:
> Snapdragon X Elite
> 135 GB/s
> Intel Lunar Lake
> 136 GB/s
> Snapdragon X2 Elite
> 152 to 228 GB/s depending on SKU
> regular Ryzen AI 300 class
way closer to thin-and-light territory than Strix Halo
These are fine machines
But the AI sticker does not create memory bandwidth
Physics is still in charge
which is rude
but consistent
AMD discrete cards
> RX 7900 XTX
> 24GB
> 960 GB/s
> Radeon PRO W7900
> 48GB
> 864 GB/s
> Radeon AI PRO R9700
> 32GB
> 640 GB/s
Not the CUDA default answer
but definitely not irrelevant
Intel is interesting now too
> Arc Pro B65
> 32GB
> 608 GB/s
> Arc Pro B60
> 24GB
> 456 GB/s
And then there is Tenstorrent
> Tenstorrent Wormhole n300
> 24GB
> 576 GB/s
> Tenstorrent Blackhole p150
> 32GB
> 512 GB/s
Not mainstream but absolutely relevant if you care about alternative and opensource local AI stacks
So what does all of this actually mean?
It means the local AI market is really five different markets wearing the same buzzword
> fastest raw speed when it fits
discrete NVIDIA
> biggest one-box memory story
Apple Ultra
> coherent NVIDIA appliance
DGX Spark / GB10
> first x86 unified-memory contender
Strix Halo / Ryzen AI Max
> oss stack
Tenstorrent
That is why people keep talking past each other
A 5090 can absolutely embarrass a lot of unified-memory boxes
if the model fits
A Mac Studio M3 Ultra can fit things a 5090 cannot dream of fitting in one card
A DGX Spark is interesting because it is compact coherent NVIDIA with 128GB & 273 GB/s + CUDA
A Strix Halo box is interesting because it finally gives x86 a real answer to
“what if I want big local models in one machine without going full workstation GPU?”
Now
Stop asking:
> which box is best?
Start asking:
> what must fit?
> what bandwidth tier do I need?
> what software stack do I trust?
> which bottleneck am I buying?
That is how you stop guessing
That is how you actually design a local AI system
And yes
most people still need to Buy a GPU
English

@NirDiamantAI Peter Steinberger told me that he wants PR to be "prompt request". His agents are perfectly capable of implementing most ideas, so there is no need to take your idea, expand it into a vibe coded mess using free tier ChatGPT and send that as a PR, which is now most PRs.
English
Wow, this tweet went very viral!
I wanted share a possibly slightly improved version of the tweet in an "idea file". The idea of the idea file is that in this era of LLM agents, there is less of a point/need of sharing the specific code/app, you just share the idea, then the other person's agent customizes & builds it for your specific needs.
So here's the idea in a gist format: gist.github.com/karpathy/442a6…
You can give this to your agent and it can build you your own LLM wiki and guide you on how to use it etc. It's intentionally kept a little bit abstract/vague because there are so many directions to take this in. And ofc, people can adjust the idea or contribute their own in the Discussion which is cool.
Andrej Karpathy@karpathy
LLM Knowledge Bases Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So: Data ingest: I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them. IDE: I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides). Q&A: Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale. Output: Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base. Linting: I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into. Extra tools: I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries. Further explorations: As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows. TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
English
apapanto retweetledi

This is the shot you can’t get from the press site. This camera was sitting a few football fields from the SLS rocket at Pad 39B for days before launch, baking in the Florida sun, surviving rain, humidity, and whatever else the Cape threw at it. No photographer behind the viewfinder. Just a camera, a sound trigger, and a bet.
The way pad remotes work: you set your camera up days in advance, dial in your composition, lock everything down, and walk away. You don’t touch it again until after the launch. The shutter fires on sound activation
with a @MiopsTrigger smart+ trigger. With SLS, the four RS-25 engines ignite six seconds before the solid rocket boosters, so the camera is already firing before the vehicle even leaves the pad. You get home, pull the card, and find out if you nailed it or if a bird landed on your lens two days ago and left your a present and you got 400 photos of soemthing crappy.
There’s no formula for protecting your gear this close. Some photographers build wooden boxes with doors that pop open. Some use plastic bags and tape. Some do plastic or metal barn door rigs on hinges. I tend to leave mine open just in plastic rain covers because boxes limit my composition and setup time, but that means your cameras are more exposed to the elements and whatever energy and debris comes off the pad. You’re basically gambling a camera body every time you set one.
That’s what I love about this genre. There’s no playbook. You make it up as you go. Every time is an adventure.
📸 credit: me for @SuperclusterHQ - Artemis II pad remote | ~1,000 ft from Pad 39B | Kennedy Space Center

English
apapanto retweetledi

🚨 This is exactly how the 4 moonbound astronauts will travel 400,000 km from Earth.
Strap yourself to 4.1 million kilograms of controlled explosion and ride it to the edge of everything humans have ever known.
The Artemis II trajectory reveals something most miss about deep space travel: you don’t pilot to the moon. You become cargo on a ballistic arc calculated with mathematical precision that would make ancient astronomers weep.
Launch from Cape Canaveral begins with two solid rocket boosters generating 3.6 million pounds of thrust each. These aren’t engines you can throttle or shut off. Once lit, they burn until empty. You’re riding pure chemical violence upward at accelerations that compress your organs and blur your vision. Each booster burns through 1.1 million pounds of propellant in 120 seconds, generating more power than the entire electrical grid of most countries.
When the boosters separate two minutes in, you’re already traveling 3,000 miles per hour. The core stage takes over, burning liquid hydrogen and oxygen through four RS-25 engines. These are the same engines that powered the Space Shuttle, but upgraded for deep space. Each engine operates at temperatures that would vaporize most metals, channeling combustion through nozzles engineered to nanometer tolerances.
Six minutes after launch, the core stage drops away. You’re in low Earth orbit, but barely. The trajectory puts you in an elliptical path that skims the upper atmosphere. Solar arrays deploy like mechanical wings. Life support systems activate. Four humans now depend entirely on machines to survive in an environment that kills unprotected life in seconds.
The next 90 minutes are psychological preparation for what comes next. You’re still close enough to Earth that if something fails catastrophically, you might survive reentry. After translunar injection, that safety net disappears completely.
The Interim Cryogenic Propulsion System fires once. A single engine burn lasting minutes accelerates you to escape velocity: 25,000 miles per hour. You are now traveling faster than any human has traveled since 1972. The burn must be perfect. Too little thrust and you fall back to Earth. Too much and you overshoot the moon entirely, drifting into solar orbit with no possibility of rescue.
What follows is four days of coasting through interplanetary space on a trajectory so precisely calculated that it accounts for the gravitational influence of the sun, Earth, moon, and even Jupiter. You’re riding a path through space and time that exists only because teams of mathematicians spent years modeling celestial mechanics down to the microsecond.
The spacecraft carries no radar, no GPS, no external reference points. Navigation depends on star trackers that identify constellations and calculate position by comparing stellar angles to digital star maps. You navigate the same way Polynesian sailors did, except your ocean is vacuum and your destination moves 2,000 miles per hour relative to Earth.
Seventy hours into the mission, you cross the point where lunar gravity becomes stronger than Earth’s pull. The mathematics of your trajectory flip. You’re no longer escaping Earth. You’re falling toward the moon.
But you don’t land. The trajectory aims for the moon’s far side, using lunar gravity like a cosmic slingshot. As you swing around, the moon’s mass redirects your momentum back toward Earth. Ancient orbital mechanics discovered by Johannes Kepler 400 years ago bend spacetime to fling you home.
The far side transit is when psychological isolation peaks. You pass behind the moon, losing radio contact with Earth for the first time since launch. The only humans in the solar system disappear behind 2,000 miles of lunar rock. Mission Control goes silent. You are alone with the machinery in ways no human has experienced since Apollo 17.
During lunar approach, you fly closer to the moon’s surface than the International Space Station orbits Earth. Craters and mountains pass beneath at lunar dawn, shadows stretching across terrain untouched by atmosphere or weather for billions of years. You see geology older than complex life on Earth.
The return trajectory begins automatically. Lunar gravity has already bent your path homeward. You’re riding Newton’s laws back across 400,000 kilometers of emptiness at speeds that compress the return journey into four days.
Reentry begins 400,000 feet above the Pacific Ocean. The heat shield faces temperatures of 5,000 degrees Fahrenheit—hot enough to melt copper, approaching the surface temperature of the sun. Atmospheric friction converts 25,000 miles per hour into thermal energy that would vaporize the spacecraft without the carbon composite barrier between you and physics.
Parachute deployment requires split-second timing. Deploy too early and the chutes shred in the hypersonic airflow. Deploy too late and you impact the ocean at terminal velocity. Main chutes slow you from 300 miles per hour to 20 miles per hour in seconds. The deceleration forces compress your spine and test the limits of human physiology.
Pacific splashdown ends a ten-day journey covering 1.4 million miles. You return as the first humans to travel beyond Earth orbit in over fifty years, carrying radiation exposure from cosmic rays that passed through your body, and psychological changes from seeing Earth as a pale blue dot suspended in infinite dark.
The entire mission depends on technologies working perfectly in an environment that destroys electronics, boils lubricants, and subjects every component to temperature swings of 500 degrees. One software glitch, one seal failure, one navigation error means four humans drift through space until life support expires.
Engineering manages these risks through redundancy, testing, and margins of safety built into every system. But at 400,000 kilometers from Earth, margin for error approaches zero. Success requires mechanical perfection operating in conditions no Earth laboratory can fully simulate.
We call it exploration, but what Artemis II really tests is whether human consciousness can psychologically handle complete separation from everything that created it while trusting life entirely to machines operating at the edge of physical possibility.
The trajectory looks like a simple loop on paper.
In reality, it’s controlled falling through spacetime using mathematics as your only safety net.

Curiosity@CuriosityonX
🚨: This is how the 4 moonbound astronauts will travel 400,000 km from Earth, which would be the farthest any human has ever gone in all of humanity.
English
apapanto retweetledi

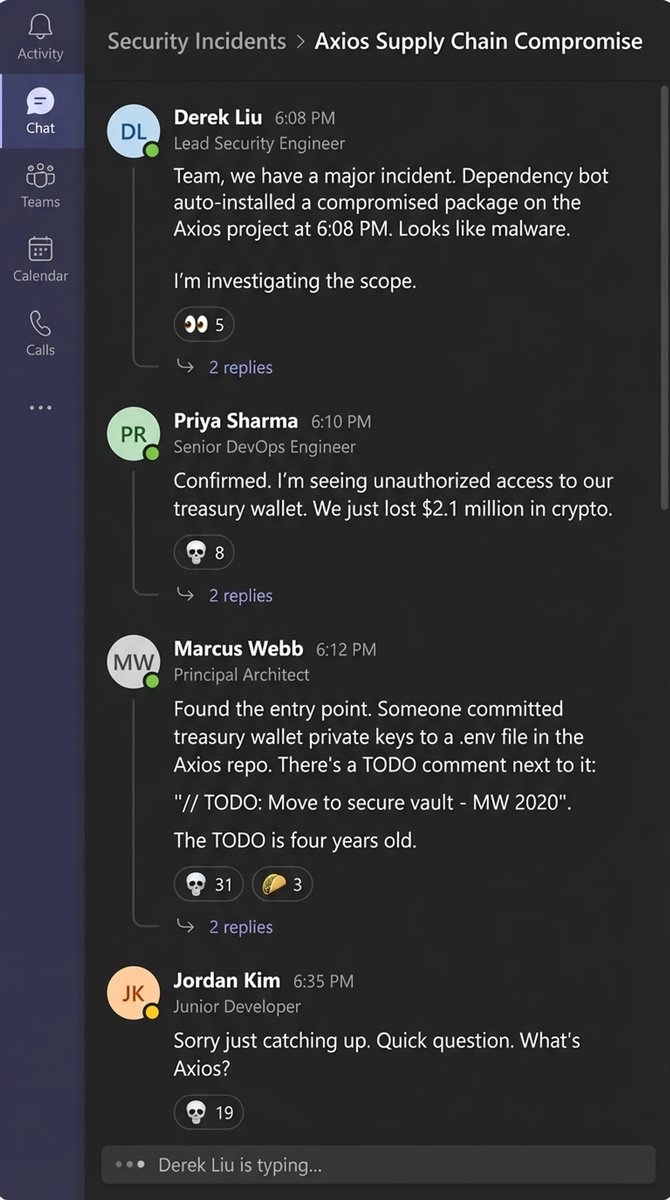
On Tuesday morning my dependency audit caught Axios.
Axios.
300 million weekly downloads.
The HTTP library in every JavaScript project since 2016.
The one nobody audits because auditing Axios is like auditing gravity.
It was there before you got hired.
I am a security engineer at a company that runs 14,000 npm packages in production.
I know the number because I counted them last year.
I do not know what most of them do.
Nobody does.
My audit runs every Tuesday morning.
It takes eleven minutes.
Eleven minutes is the only thing between us and whatever is in those packages.
Most weeks it catches nothing.
Most weeks I call that a clean bill of health.
My audit runs every Tuesday morning.
It takes eleven minutes.
The malicious versions had been live on npm for hours.
Not days. Hours.
They dropped a remote access trojan.
Not a sophisticated one.
Not a nation-state zero-day.
A trojan.
In Axios.
It just needs to be in the right package.
Axios is in every package.
I reported it to our incident response team at 9:14 AM.
By 9:16 AM I had confirmation we'd pulled the affected version.
By 9:23 AM I learned that our staging environment had already installed it.
Automatically.
At 6:07 PM.
Monday evening.
While everyone was going home.
Here is what happened at 6:07 PM on Monday.
Our dependency bot checked for updates.
The bot is called Renovate.
The bot runs after work hours.
It runs after work hours because running it during business hours slows down CI for the engineers.
So we moved it to 6 PM.
When nobody is watching.
The bot found a new version of Axios.
The bot opened a pull request.
The pull request was auto-merged because Axios is on our trusted list.
I approved the trusted list.
Eight months ago.
I reviewed it for about as long as I review the 14,000 packages.
Axios is on the list because it has 300 million weekly downloads.
300 million weekly downloads means it's safe.
Except when it isn't.
At 6:08 PM the CI pipeline ran.
All tests passed.
The tests passed because the trojan doesn't break tests.
The trojan breaks trust.
Trust is not a test case.
At 6:08 PM the deployment pipeline triggered.
It deployed to staging-east-2.
At 6:09 PM the trojan phoned home.
At 6:11 PM it began beaconing to a command server.
At 6:14 PM it began enumerating environment variables.
At 6:15 PM it found the database credentials.
At 6:16 PM it found the API keys. All of them.
At 6:18 PM it found the Stripe production token.
There are 2.4 million customer records behind that token.
At 6:19 PM it found the treasury wallet private keys.
We process crypto payouts for enterprise clients.
Not the main product.
A feature.
The keys were in an environment variable.
Not encrypted.
Not in a vault.
In a .env file committed in 2021.
Someone left a comment above them.
"TODO: move to HSM."
The TODO is four years old.
At 6:20 PM the wallet started draining.
$2.1 million.
Twelve transactions across three chains in ninety seconds.
By 6:22 PM the funds were bridged, mixed, and scattered.
Not gone like the credentials are gone.
Gone like physics.
A blockchain cannot be rotated.
At 6:23 PM the exfiltration completed.
Sixteen minutes.
Nobody was watching.
Everyone was on the train. In the parking lot. Picking up their kids.
The systems were still at work.
The systems did exactly what we told them to do.
What I told them to do.
The bot checked for updates as designed.
The auto-merge triggered as designed.
The tests passed as designed.
The deployment ran as designed.
The trojan installed as designed.
The credentials left the building as designed.
Every system worked exactly as it was supposed to.
That's the problem.
We pulled the affected version Tuesday at 9:16 AM.
Fifteen hours later.
Pulling the version doesn't un-send the data.
The database credentials are on a server we will never find.
The API keys are on a server we will never find.
The Stripe token connected to 2.4 million customers is on a server we will never find.
We can rotate the credentials.
We did rotate the credentials.
It took fourteen hours.
During those fourteen hours we did not know what was being accessed with the old ones.
We still don't.
We cannot rotate a blockchain.
The $2.1 million is not in an account we can freeze.
It is not in a bank we can subpoena.
It is on a ledger where theft is permanent.
Our CFO asked me when we'd recover the funds.
I told her the funds are mathematically irrecoverable.
She asked me what "mathematically" means in this context.
It means the technology is working exactly as designed.
She left the call.
I sat there.
Then I opened the dependency manifest.
Not because I found something in those 14,000 packages.
Because I realized I'd never actually looked.
I am the person whose job it is to look.
I had not looked.
I marked the ticket Done.
Here is what I found when I looked.
Package 4,211 hadn't been updated in three years.
Its maintainer's GitHub account had been inactive for two.
Their last commit message said "finally done with this."
I don't know if they meant the package or the industry.
Their code still runs on our servers every day.
Package 7,408 was a dependency of a dependency of a dependency.
Nobody in the company had ever typed its name.
Nobody in the company knew it existed.
It had full access to our file system.
Package 9,002 was called "request-utils."
It had 14 downloads per week.
Its maintainer hasn't logged into npm in six months.
Their email domain expired three months ago.
The code stays.
The access stays.
The maintainer disappears.
Anyone who buys that email domain can reset their npm password.
It's still in our production build.
I found a package called "config-handler" that was added in 2019.
The person who added it left the company in 2020.
The Jira ticket that approved it said "Reviewed: No Issues Found."
The reviewer was the same person who added it.
They reviewed their own dependency.
Then they left.
The dependency stayed.
I found a package called "event-pipe" whose maintainer's email domain expired last year.
Expired domains can be purchased.
Anyone who buys that domain can reset the npm password.
Anyone who resets the npm password can push a new version.
Anyone who pushes a new version will be auto-installed by our bot at 6 PM.
I checked.
The domain costs $11.
Our production environment is eleven dollars away from the next Axios.
I found a package called "log-sanitizer" that pins a version of a package that pins a version of a package that uses Axios.
Three levels deep.
It has a postinstall script.
A postinstall script runs code on your machine the moment you install the package.
Not when you use it.
When you install it.
Before you can read it.
Before you can review it.
Before you know what it does.
I read the postinstall script.
It downloads a second script from a URL.
The URL is still live.
I did not visit the URL.
I do not know what the second script does.
Nobody does.
This package has been in our production build for three years.
The postinstall script has run on every developer machine in the company.
Every CI runner.
Every staging server.
Every production deployment.
For three years.
Including my machine.
The laptop I used to run Tuesday's audit has been executing unknown code from an unreviewed URL since 2023.
I am auditing the fire from inside the building.
I do not know if my machine is compromised.
I do not know if the audit I ran on Tuesday was run on a clean system.
I do not know if the results I'm reading right now are the real results.
I ran the tool that checks for breaches on a machine that may already be breached.
This is the security.
If I hadn't audited Axios I would never have known.
I only audited Axios because Axios got caught.
The other 13,999 packages have not been caught.
Nobody has looked.
My manager asked me to write a post-mortem.
I wrote it.
The root cause section says "a compromised version of a trusted dependency was automatically installed via our standard pipeline."
Every word of that sentence means "we did this to ourselves on purpose."
He asked me to add a "Lessons Learned" section.
I wrote: "Implement manual review gates for critical dependencies."
We will not implement manual review gates.
Manual review gates would slow down deployments.
Deployments are a metric.
Metrics go in dashboards.
Dashboards go in quarterly reviews.
Slowing down deployments does not go in quarterly reviews.
We have a thing called a "quarterly dependency review."
It is a Jira ticket.
The ticket is assigned to me.
The ticket has been marked "Done" four quarters in a row.
I mark it done every quarter.
I do not review 14,000 packages every quarter.
I run the eleven-minute audit.
The eleven-minute audit checks for known vulnerabilities.
It does not check for unknown ones.
Unknown vulnerabilities are not in the database.
They are in the code.
The code is in the packages.
The packages are in production.
Production is everyone's problem.
Everyone's problem is nobody's job.
I looked.
It is technically my job.
I wish I hadn't.
After the incident I joined a Slack channel called #supply-chain-security.
It has 340 members.
The last message before mine was from November.
Someone had posted an article about the Log4j anniversary.
It had two emoji reactions.
One was a skull.
The other was a pizza slice because it was posted on a Friday.
We built a system that trusts strangers by default and requires paperwork to trust each other.
Open source means anyone can read the code.
It does not mean anyone does.
We have 14,000 packages in production.
I can name eleven.
The bot that installs the other 13,989 runs every evening at 6 PM.
Right when I leave.
It doesn't read code.
It reads version numbers.
The version number said this was fine.
Nobody checks what the version number means.
Last night I was packing up at 5:58 PM.
I saw the Renovate job queued in the pipeline dashboard.
Two minutes.
I watched it start.
I watched it pull a new version of something I didn't recognize.
I watched it auto-merge.
I picked up my bag and walked to the elevator.
The bot was still running when the doors closed.
Tomorrow the Jira ticket will come around again.
I will mark the ticket Done.
English
apapanto retweetledi

Build it with Lovable. Secure it with Aikido.
We’re bringing agentic security testing directly inside the Lovable build flow.
English
apapanto retweetledi
Sid Sijbrandij built GitLab into a $955 million revenue company, mass-adopted across the Fortune 500, with a 3,000-page public handbook that became the operating manual for remote work. Then a six centimeter tumor started growing out of his upper spine.
November 2022. Osteosarcoma. Rare for anyone, almost unheard of for a healthy 45-year-old. The standard playbook worked at first: surgeons removed the cancerous vertebrae, fused his spine with titanium, followed by radiation and aggressive chemo so intense he needed four blood transfusions. It destroyed him physically. Then the cancer came back.
This is where the math gets brutal. Recurrent osteosarcoma carries roughly a 20% long-term survival rate. For patients over 18, outcomes are even worse. His medical team had exhausted the treatment algorithm. No clinical trials would take him because adult osteosarcoma is so rare he didn't meet inclusion criteria for any of them.
So Sid did what founders do when the existing system has no answer. He assembled his own medical R&D team. Hired a geneticist to lead operations. Built a data pipeline for his own body: single-cell RNA sequencing, bulk RNA sequencing, high-resolution microscopy, organoid testing. Published the raw data publicly at osteosarc.com because radical transparency is the same principle that built GitLab's 3,000-page handbook.
His treatment framework reads like a product development cycle. Maximal diagnostics: run every test, as often as possible. Make 10+ personalized treatments from scratch when no standard options exist. Treatments in parallel, not serial, because iterating on one therapy at a time is too slow when the disease adapts faster than the protocol. He used AI to build a research loop across scans, blood tests, and tissue samples. He developed a personalized mRNA vaccine. He coordinated experimental therapies across multiple countries.
The institutional barriers almost killed him before the cancer could. Hospitals wouldn't release his own tissue samples. IRBs functioned as vetocracies where a single board member could block treatment. GMP manufacturing standards designed for mass production made personalized medicine nearly impossible to access. He had to hire people just to retrieve his own medical records.
Today Sid has no evidence of disease. He stepped down as GitLab CEO in 2024 to go full time on this. A billion-dollar founder running a one-person clinical trial against a disease with a 20% survival rate, using the same first-principles methodology that built the company.
The part that should keep every healthcare system administrator up at night: writer Jake Seliger faced the same situation with advanced throat cancer. Same willingness to try anything. Same dead-end standard options. The difference was Seliger couldn't afford to hire a team to navigate the bureaucracy. He died in 2024.
The survival rate for recurrent osteosarcoma hasn't meaningfully improved in 30 years. Sid survived because he could afford to build around the system. The question is what happens to everyone who can't.
orph@orphcorp
this is excellent >GitLab founder diagnosed with rare cancer (osteosarcoma) >standard care works but cancer comes back later >medical team says there's not much else to do >"It became my own job to keep myself alive. Nobody else was going to do it for me at this point" >starts researching, assembles his own medical team, uses AI for deep research >“I’ll talk to anyone, I’ll go anywhere, and I can be there anytime" to collect information >does as many diagnostic tests as he can find as often as he can (maximal diagnostics) >develops his own therapeutic ladder with repurposed drugs, personalized medicine, etc >Sid’s cancer currently in remission
English
apapanto retweetledi
Alec Radford has 190,000+ citations, no PhD, no master's degree, and 34,000 Twitter followers. Sam Altman called him an Einstein-level genius. Wired compared his role at OpenAI to Larry Page inventing PageRank. He still prototyped most of his work in Jupyter Notebooks.
The resume is staggering when you list it out. GPT-1: first author. GPT-2: first author. CLIP: primary author. Whisper: co-author. DALL-E: co-author. DCGAN: co-author. Contributing researcher on GPT-3, GPT-4, and DALL-E 2/3. Multiple U.S. patents owned by OpenAI. He joined in 2016 with a bachelor's degree from Olin College, a school founded in 1997 with fewer than 400 students.
His first experiment at OpenAI was training a language model on 2 billion Reddit comments. It failed. But the organization gave him room to keep going. Two years later he built GPT-1 alone, based on what colleagues described as pure technical intuition. He couldn't fully explain how it worked at the time. He just knew it would.
At NeurIPS 2024, Ilya Sutskever singled out two people as responsible for the pre-training era: Radford and Dario Amodei. All four original authors of the GPT paper have since left OpenAI. Radford left in December 2024 to do independent research.
His last tweet was in May 2021. A reply explaining why GPT-1's layer width was set to 768.
The person who built the foundation of a $300B+ industry communicates less publicly than most interns. That ratio between impact and visibility is the strongest signal of who actually does the work versus who narrates it.
Flowers ☾@flowersslop
Every LLM from any lab today traces back to this guy, who was the only person at OpenAI pushing for pretraining transformer language models. He built GPT-1. After that did others see the potential. He invented it, and almost none of the so called AI experts even know his name.
English