Sabitlenmiş Tweet

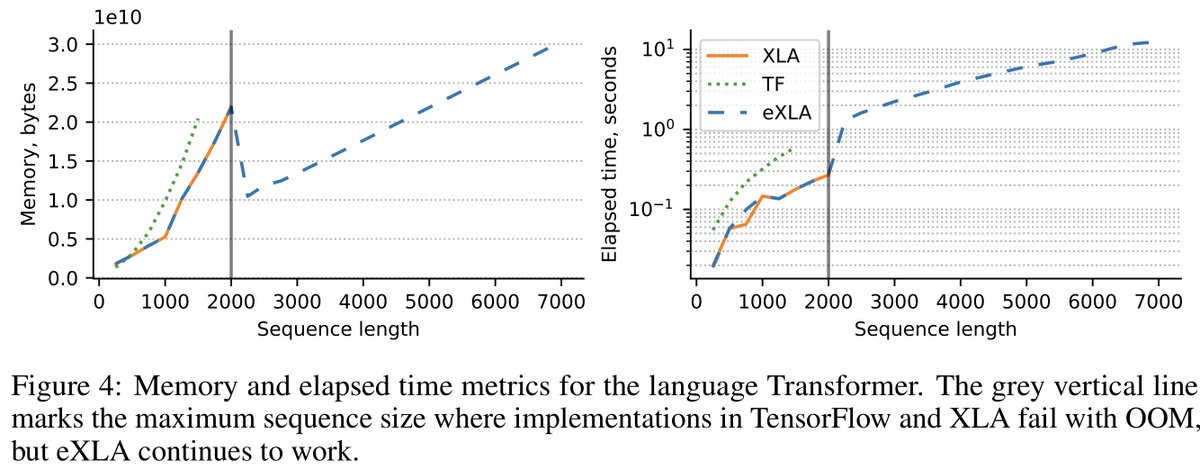
Check out our work "Memory Safe Computations with XLA compiler" at #NeurIPS2022 (with Yuze An, @dyedgreen, @markvanderwilk). The paper and PR can be found at openreview.net/pdf?id=2S_GtHB… and github.com/tensorflow/ten…. The poster is neurips.cc/virtual/2022/p…. Some details in short [1/8]
English