Sabitlenmiş Tweet

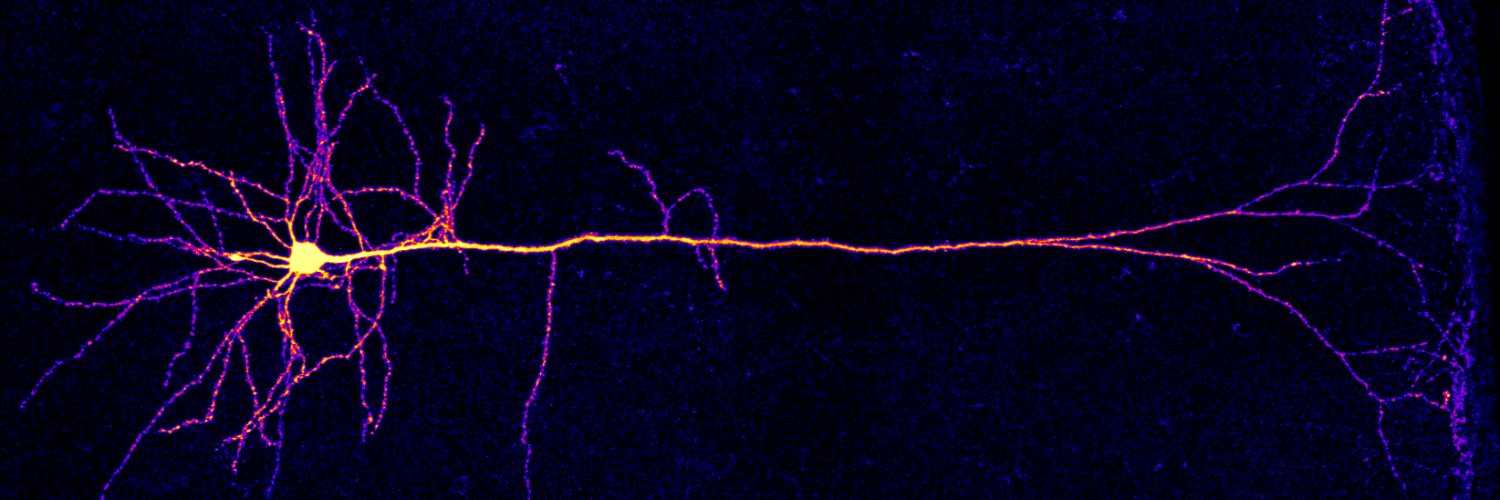
How do you implement spiking neurons and dendrite-dependent reinforcement learning using analog electronic circuits?
We discuss this and more in our latest paper, just published! 👇 pnas.org/doi/10.1073/pn…
English
Alessandro Galloni
392 posts
@argalloni
Research Scientist in Neuromorphic Computing at Innatera. Previously: comp. neuro + ephys @ UCL, Francis Crick Institute, Rutgers


why the fuck meta employees watching videos their users are taking









🚨 Did you know that small-batch vanilla SGD without momentum (i.e. the first optimizer you learn about in intro ML) is virtually as fast as AdamW for LLM pretraining on a per-FLOP basis? 📜 1/n

