Sabitlenmiş Tweet

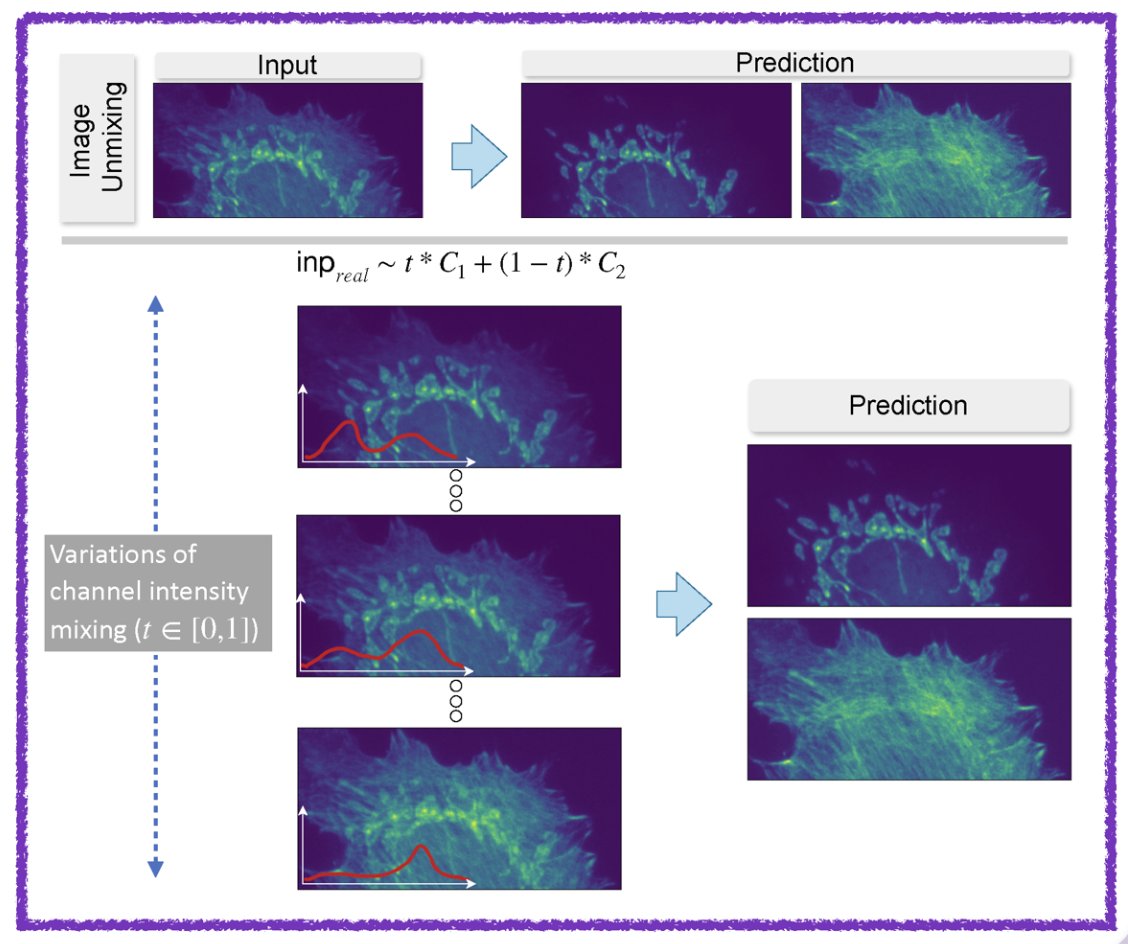
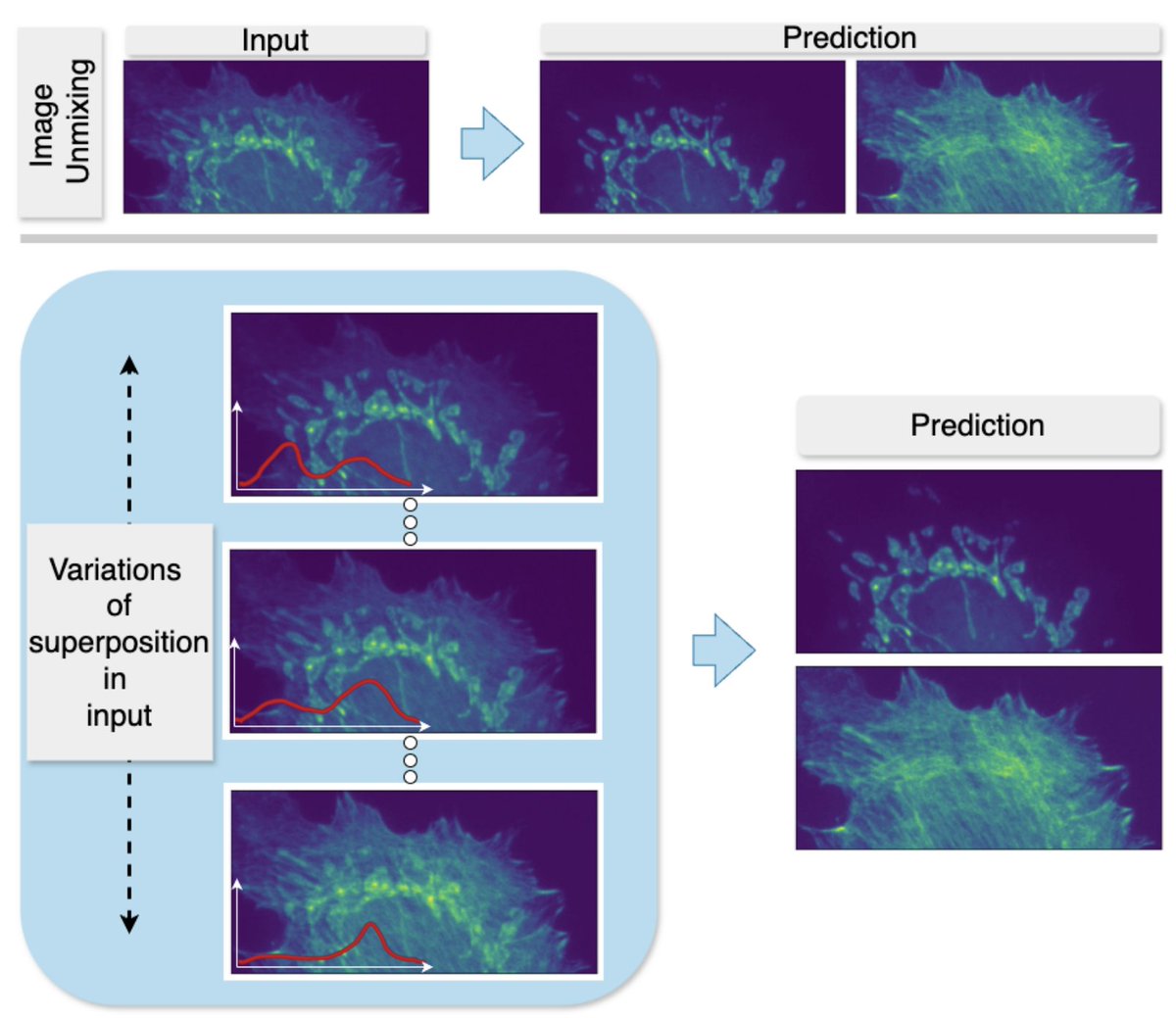
Our work on generalizing across variations in the strength of structures within superimposed images—an issue relevant for semantic unmixing and bleed-through removal in fluorescence microscopy—has been accepted at NeurIPS 2025! (arxiv.org/abs/2503.22983) @florianjug
English